

大数据文摘出品
作者:宁静
刚刚被拉下神坛的BERT又一次称霸了GLUE、SQuAD和RACE三个排行榜。
今年六月,谷歌发布XLNet,指出并解决了BERT的缺点,在20多个指标上全面刷爆了BERT之前的成绩,数据、算力相比BERT增加了很多,也在业内引起了激烈讨论:到底该用BERT还是XLNet?
Facebook前几天宣布:如果训练更久一点、数据量再大一点,BERT 还是能重新达到 GLUE 基准的第一名。
今天,Facebook开源了这个基于BERT开发的加强版预训练模型RoBERTa,全称”Robustly optimized BERT approach”——强力优化BERT方法,在GLUE、SQuAD和RACE三个排行榜上都取得了最优成绩。
在今天的官方推文中,Facebook AI也直接明了地点出了这一方法的称霸诀窍:更久的训练时间、更多的数据、更强力调参。
Facebook也强调了RoBERTa诞生的意义:
调整BERT训练程序可以显着提高其在各种NLP任务上的表现,同时也表明了这种方法的竞争力。更广泛来看,这项研究进一步证明了,监督训练有可能达到或超过更传统的监督方法的表现。RoBERTa是Facebook不断致力于推动自我监督系统最先进技术的一部分,该系统的开发可以减少对时间和资源密集型数据标签的依赖。
这项研究由Facebook AI和华盛顿大学的研究团队共同完成,并公开了论文和代码,先附上链接:
论文链接:
Github代码链接:
亮点:RoBERTa基于BERT的改进
RoBERTa基于BERT的改进在四个方面展开,包括:
- 更长时间地训练模型,批量更大,数据更多;
- 删除下一句预测的目标;
- 较长时间的训练;
- 动态改变应用于训练数据的masking模式。
论文的贡献在于:
- 提出了一套重要的BERT设计选择和训练策略,并引入了能够提高下游任务成绩的备选方案;
- 文中使用一种新的数据集CCNEWS,并确认使用更多数据进行预训练,进一步改善了下游任务的性能;
- 预训练的masked language model相比发表的其他方法都更具有竞争力,已经开源了在PyTorch中模型训练和参数微调的代码。
模型内部架构
之前的BERT采用Transformer 结构,改经后的RoBERTa使用的是L层的transformer 架构,每个block 都使用一个self-attention head和隐藏维度H。
在讲解模型内部原理之前先简单介绍NLP领域中常用的Transformer 结构:
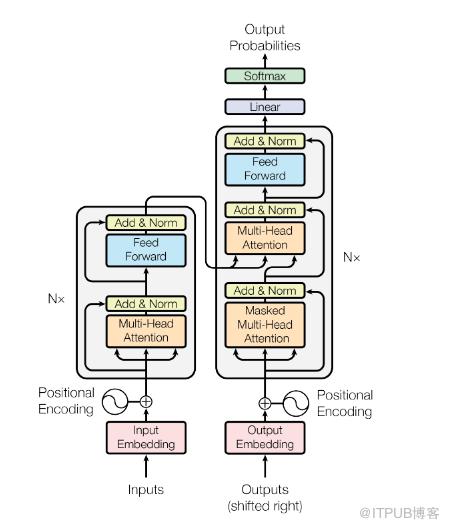
Transformer的主体结构图
模型分为编码器和解码器两个部分,编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为d维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
Transformer用于机器翻译任务,表现极好,可并行化,并且大大减少训练时间。
模型预训练
在预训练模型的过程中,需要完成两个指标:Masked Language Model (MLM) 和Next Sentence Prediction (NSP)
- Masked Language Model (MLM) :MLM的目标是masked tokens序列中的交叉熵,选择输入中的随机token样本,并替换为特殊的token [MASK],BERT模型一致选择输入token中的15%作为可能的替换,在所选的token(selected tokens)中,80%的selected tokens替换为token [MASK],10%的selected tokens保持不变,另外10%替换为随机选择的词汇表token。
- Next Sentence Prediction (NSP)下一句预测:预测两个语段之间的二元分类损失,判断语句有没有前后的依从关系,其中正样本来自于文本语料库中提取连续的句子,负样本来自于不同文档的段进行配对,正负样本相同的概率进行采样。
模型参数优化
BERT用以下参数:β1= 0.9,β2= 0.999,ǫ = 1e-6,L2权重为0.01,伴随着学习率的加快,在前10,000个steps中达到峰值1e-4,然后线性衰减;BERT训练时在所有层和attention结构中采用0.1的 dropout ,使用GELU激活函数,模型预训练有S = 1,000,000次更新,小批量包含B = 256个sequences和T = 512的tokens序列。
实验结果
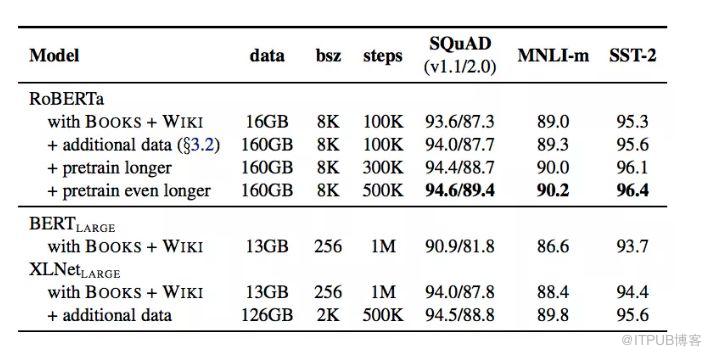
当控制训练数据时,我们观察到RoBERTa比BERTLARGE结果有了很大的改进,当数据集从16GB增加到160GB,训练次数从100K到300K再到500K的过程中,模型准确度也逐渐提升。
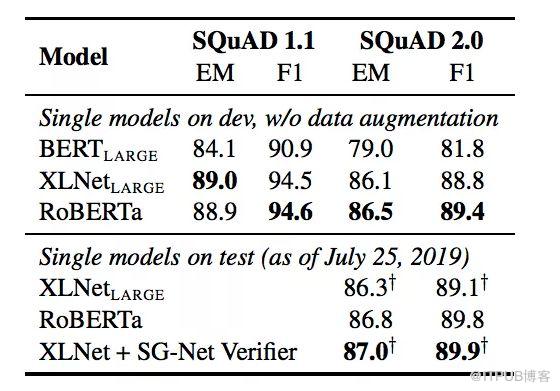
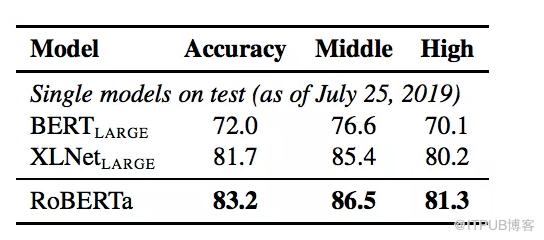
RoBERTa在开发和测试中使用了提供的SQuAD数据,+表示依赖于额外外部训练数据的结果,从下面两个表中,可以看到RoBERTa相比XLNet有精度上的提升,表中加粗的数字。
在RACE测试集上的结果显示,RoBERTa的Accyracy相比BERT(large)提高了10个百分点,相比XLNet(large)提高了2个百分点。
BERT与XLNet之争
自诞生起,BERT在江湖中地地位一直颇动荡。
去年10月,谷歌放出了称霸GLUE榜单的BERT模型,当时BERT最大的创新就是提出了Masked Language Model作为预训练任务,解决了GPT不能双向编码、ELMo不能深度双向编码的问题。之后从那天起,很多任务都不再需要复杂的网络结构,也不需要大量的标注数据,业界学术界都基于BERT做了很多事情。
2019年6月19日,谷歌又放出了一个模型XLNet,找到并解决了BERT的缺点,在20多个指标上全面刷爆了BERT之前的成绩,数据、算力相比BERT增加了很多。
语言模型预训练导致了显著的性能增益,但是在不同方法之间仔细仍然具有挑战性,计算的训练成本是昂贵的,同样,超参数选择对最终结果有显著的影响。
但是,XLNet的王座终没做稳,在充分测量许多关键的超参数和训练数据大小的影响,研究人员发现,Bert的训练明显不足,改进后的Bert模型可以达到或超过在之后发布的每一个模型的性能。
本月初,XLNet 团队尝试以一种在相同环境和配置下训练两个模型的方式,对比了 XLNet 和 BERT 的效果,回应业内的讨论。
研究者尝试让每一个超参数都采用相同的值,使用相同的训练数据。
最终结果?
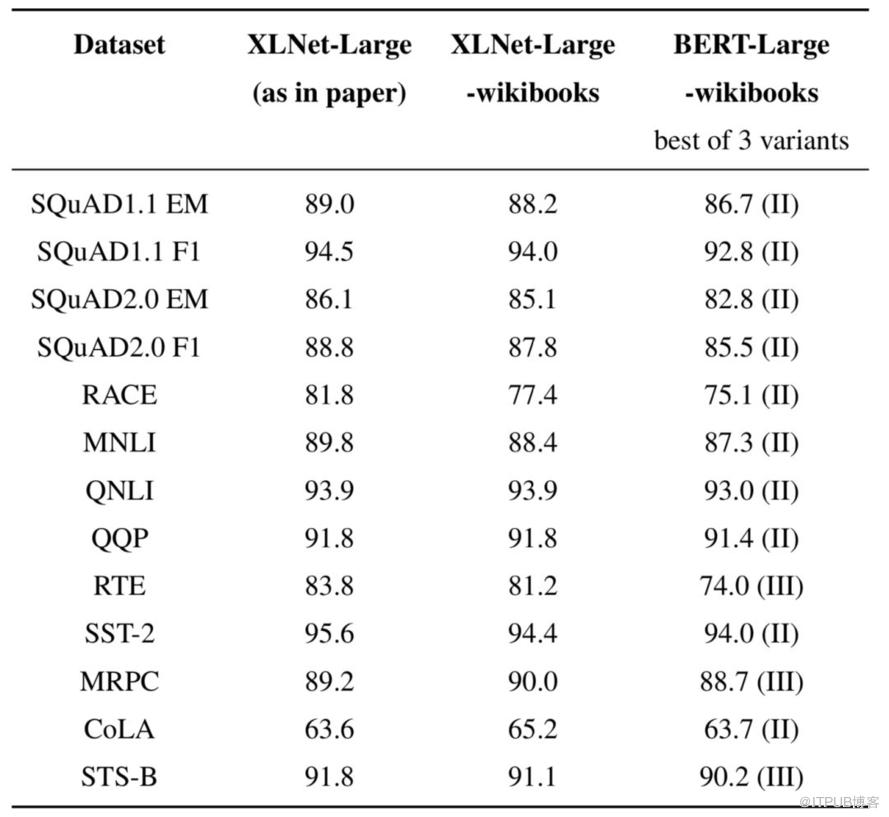
实验中有一些有趣的观察结果:
- 使用几乎相同的训练配方训练相同的数据,XLNet在所有数据集上以相当大的优势超越BERT。
- 在11个基准测试中的8个中,采用10倍以上数据的收益,小于从BERT切换到XLNet的性能增益。
- 在一些基准测试中,例如CoLA和MRPC,在更多数据上训练的模型性能低于在较少数据上训练的模型。
虽然这一研究是XLNet团队发布的,但是对于两者的长期争论仍然有很大的价值。感兴趣的读者可以查看原文?