
最近,谷歌研究人员发表了一篇论文,并在RecSys 2019(丹麦哥本哈根)的论坛上公布,论文中对他们的视频平台Youtube用户视频推荐方式进行了阐述。在这篇文章中,笔者将试着总结我阅读这篇论文后的发现。
解决的问题
当用户在Youtube上观看视频时,一个用户可能会喜欢的推荐视频列表会以一定的顺序显示出来。该论文的研究目标主要有两个:
·需要优化不同的目标;确切的目标功能没有定义,但是目标被划分为参与目标(点击、耗费时长)和满意度目标(喜欢、不喜欢)。
·减少系统隐含的选择偏差,因为用户更有可能点击第一个推荐,尽管位置较低的视频可能产生更高的参与度和满意度。
注:如何有效、高效地学习减少这种偏差是一个悬而未决的问题。
采用的方法
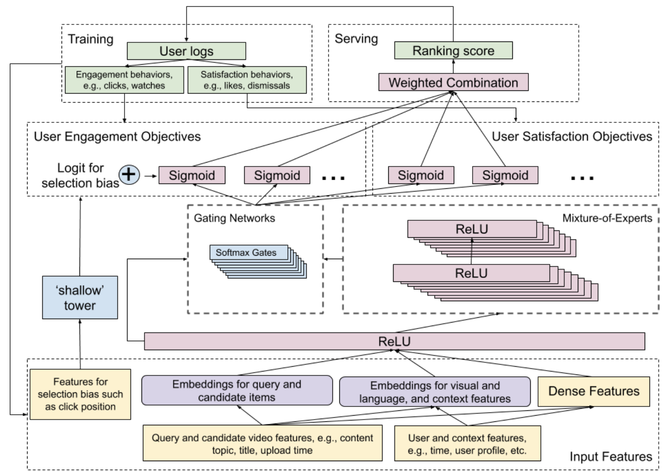
图1:模型的完整架构
这个论文中所描述的模型主要针对两个目标。该团队使用了一个广度和深度(Wide & Deep)模型架构,它结合了广度线性模型(记忆)和深度神经网络(归纳)的力量。Wide & Deep模型将为每个定义的目标(包括参与度和满意度)生成预测。目标分为二分类问题(即是否喜欢某个视频)和回归问题(即对某个视频的评价)。这个模型的顶部会添加一个单独的排名模型。这只是输出向量的一个加权组合,输出向量即不同的预测目标。这些权重是手动调整的,以实现不同目标的最佳性能。为了提高性能,该团队提出了一些先进的方法,如成对的或基于列表的方法,但是由于计算时间的增加,这些方法并没有被应用到生产中。
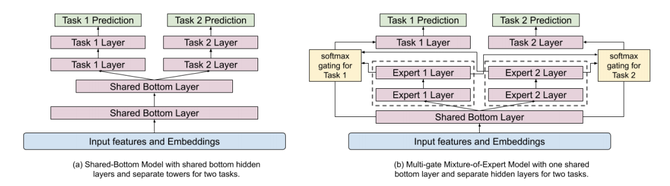
图2:用MMoE替换shared-bottom层
在Wide & Deep模型的Deep部分,采用了MMoE模型(Multi-gate Mixture of Experts)。将当前视频的特性(内容、标题、主题、上传时间等)和正在观看的用户(时间、用户档案等)作为输入。MMoE模型背后的概念是基于在不同目标上有效地共享权重。shared-bottom层被分成多个Expert,这些Expert都被用来预测不同的目标。每个目标都有一个gate函数。该gate函数是一个具有原始共享层和不同Expert层输入的softmax函数。这个softmax函数将确定哪些Expert层对于不同的目标是重要的。如图3所示,不同的Expert会对于不同的目标更加重要。如果与 shared-bottom架构相比,不同的目标具有较低的相关性,则MMoE模型训练受到的影响更小。
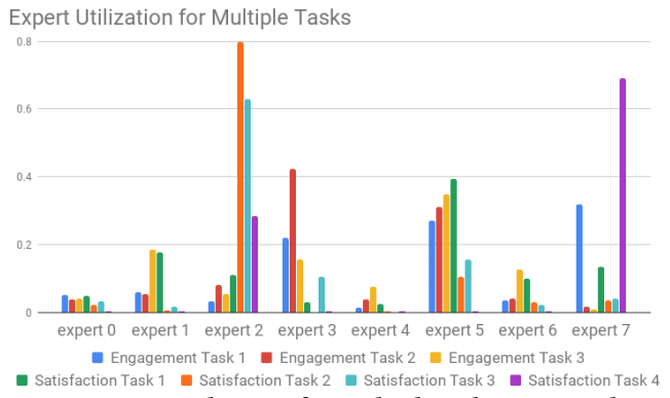
图3:YouTube上的多任务专家应用
该模型的Wide部分是减少系统中推荐视频位置引入的选择偏差。这个Wide部分被称为“浅塔”(shallow tower),它可以只是一个简单的线性模型,使用简单的功能,如视频点击位置和用来观看视频的设备。浅塔的输出与MMoE模型的输出相结合,MMoE模型是Wide & Deep模型体系结构的关键组成部分。这样一来,模型就会更关注视频的位置。在训练中,会设置10%的丢失率被用来防止位置特征在模型中变得太重要。如果您不使用Wide & Deep的架构,并将位置作为一个单一的特性来添加,那么模型可能根本不会关注该特性。
结果如何
该论文的结果表明,用MMoE替换shared-bottom层可以提高模型的参与度(观看推荐视频的时长)和满意度(调查反馈)。增加MMoE中的Expert层数量和乘法的数量进一步提高了模型的性能。但由于计算上的限制,这个数字不能在现场设置中增加。

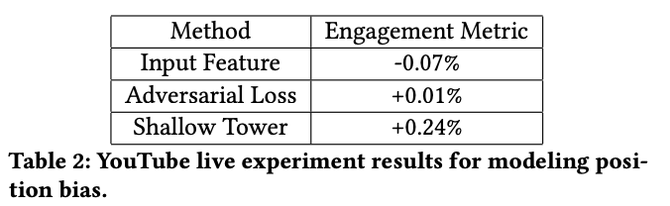
进一步的结果表明,通过减少由于使用浅塔而导致的选择偏差,参与度度量得到了改善。与只在MMoE模型中添加输入特性相比,这是一个较为显著的改进。
值得一提
·虽然谷歌有一个很好的计算基础设施,但他们仍然需要注意训练和服务成本。
·通过使用Wide & Deep模型,您可以在设计一个网络时预先定义对您很重要的一些特性。
·当您需要一个具有多个目标的模型时,MMoE模型是有效的。
·即使拥有一个强大而复杂的模型架构,人们仍然是手动调整最后一层的权重,根据不同的客观预测来确定实际的排名。
原文作者:Tim Elfrink