
我们每天都听到人工智能的突破。然而,你想知道它面临哪些挑战吗?
在 DNA 测序、信用卡交易,甚至网络安全等高度非结构化数据中,都面临挑战,网络安全是保护我们在线存在免受欺诈者侵害的支柱。这种想法是否让你渴望更多地了解这些系统背后的科学和推理?不用担心!我们已经为您服务了在网络时代,机器学习 (ML) 为我们提供了梯度提升机器 (GBM) 实施后解决这些问题的解决方案。我们有足够的算法可供选择,为我们的训练数据做梯度提升,但我们仍然会遇到不同的问题,如精度低,损耗高,结果差异大。
在这里,我们将向您介绍由陈天琪构建的最先进的机器学习算法XGBoost,它不仅将克服问题,而且对回归和分类问题也表现卓越。此博客将帮助您了解 XGBoost 的见解、技术和技能,然后您可以将其带到机器学习项目中。
XGBoost 一览!
eXtreme 梯度提升 (XGBoost)是一种可扩展和改进的梯度提升算法(术语警报)版本,旨在实现有效性、计算速度和模型性能。它是一个开源库,是分布式机器学习社区的一部分。XGBoost 是软件和硬件功能的完美融合,旨在以最短的时间内以精确度增强现有提升技术。下面快速查看 XGBoost 与其他梯度提升算法与随机林与 500 棵树训练的客观基准比较,由Szilard Pafka执行。
XGBoost 的基准性能
快速闪回提升
提高通常意味着提高性能。在ML中,提升是一种连续的合奏学习技术(另一种术语警报,不烦恼!我们也将解释这一点),将弱假设或弱学习者转化为强壮的学习者,以提高模型的准确性。
我们可以通过一个简单的分类示例理解提升的必要性:在基础规则的帮助下将 Twitter 帐户分类为机器人或人类(范围有限):

规则:
- 无帐户信息和个人资料照片 • 机器人
- 用户名是胡言乱语 + 机器人
- 以多种语言发推文 • 机器人
- 它有足够的活动和配置文件*
- 每天大量的推文 » 机器人
- 其他帐户链接 = 人
现在,我们知道了这些规则,让我们在下面的示例中应用这些规则:
场景 – 以英语和法语发布推文的帐户。
第 3 条规则将将其归类为自动程序,但这将是一个错误的预测,因为一个人可以知道和推特多种语言。因此,基于单个规则,我们的预测可能存在缺陷。由于这些单独的规则不够强大,不足以做出准确的预测,因此它们被称为弱学习者。从技术上讲,弱学习者是一个与实际值关联较弱的分类器。因此,为了使我们的预测更准确,我们设计了一个模型,结合弱学习者的预测,使一个强大的学习者,这是使用促进技术完成。
弱规则由基础学习算法在每次迭代中生成,在我们的例子中,这些算法可以是两种类型:
- 树作为基础学习者
- 线性基础学习者
通常,决策树是默认基础学员,用于提升
首先,让我们了解上面提到的合奏学习技巧。
集合学习
与单个 ML 模型相比,组合学习是结合多个机器学习模型的决策以减少错误和改进预测的过程。然后,将最大投票技术用于聚合决策(或机器学习行话中的预测),以推导最终预测。困惑?
把它想象成组织到你的工作/学院/或杂货店的有效路线。由于您可以使用多条路线到达目的地,您倾向于了解流量和延迟,在一天的不同时间可能会给您带来延迟,让您设计出一条完美的路线,Ensemble 学习是一样的!
此图像显示了单个 ML 模型相对于”组合学员”的明确区别:
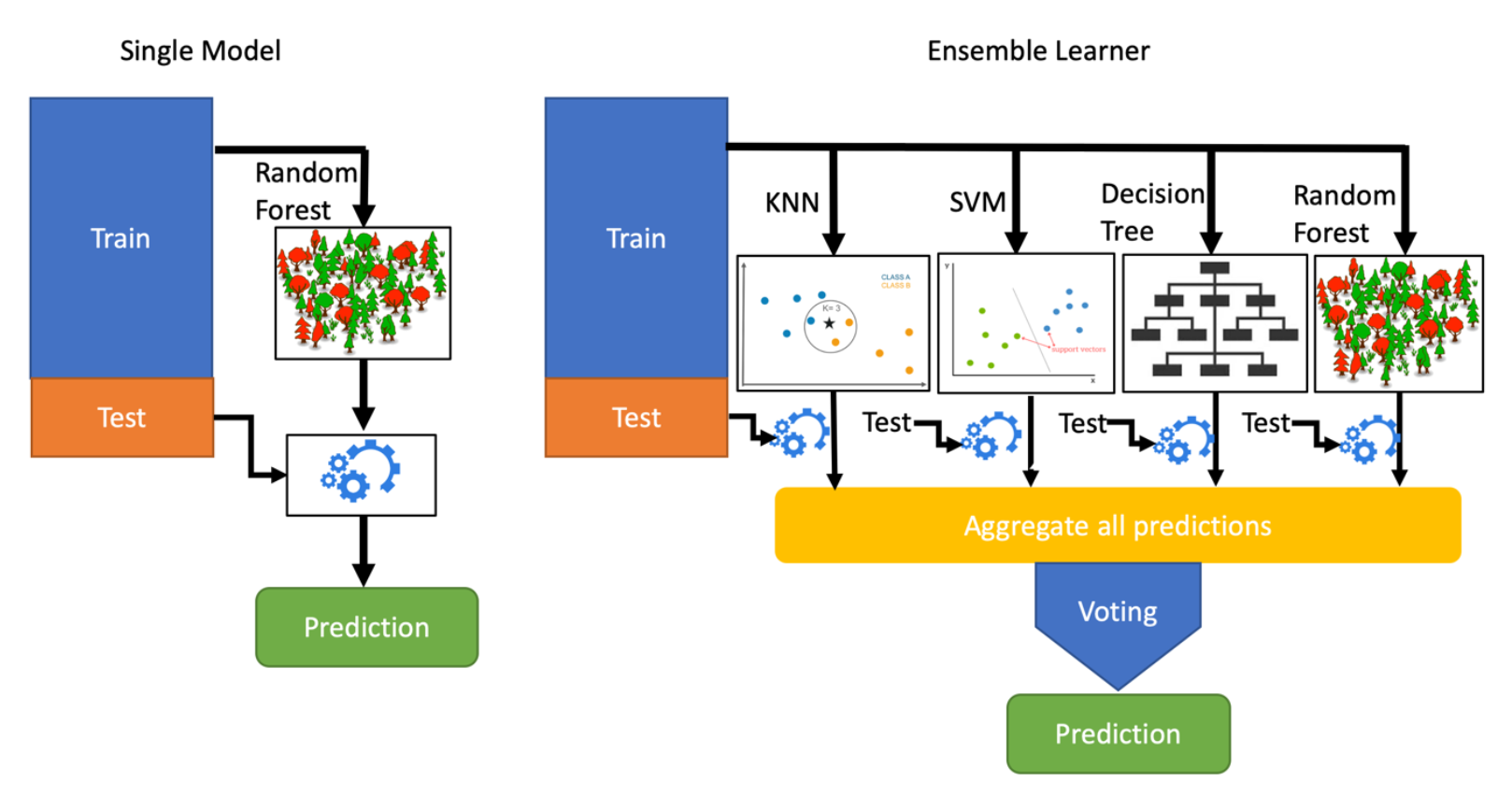
单模型预测与集合学习者
集合学习的类型:
可以通过两种方式执行组合学习方法:
- 装袋(平行合奏)
- 提升(顺序合奏)
虽然两者都有一些迷人的数学封面,我们不需要知道它能够拿起它作为一个工具。由于 Boost 在 XGBoost 中的相关性,我们的重点将更多地放在对 Boost 的理解上。
增压算法的工作:
增压算法创建新的弱学习者(模型),并按顺序组合他们的预测,以提高模型的整体性能。对于任何不正确的预测,将较大的权重分配给错误分类的样本,将较低的权重分配给正确分类的样本。在最终合奏模型中表现更好的弱学习者模型具有更高的权重。
提升永远不会改变以前的预测变量,并且只能通过从错误中学习来更正下一个预测变量g. 树基学习者的树深),以防止训练数据过度拟合。提升的第一个实现被命名为 AdaBoost(自适应增强)。
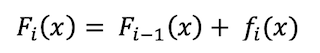
F(i) is current model, F(i-1) is previous model and f(i) represents weak
model
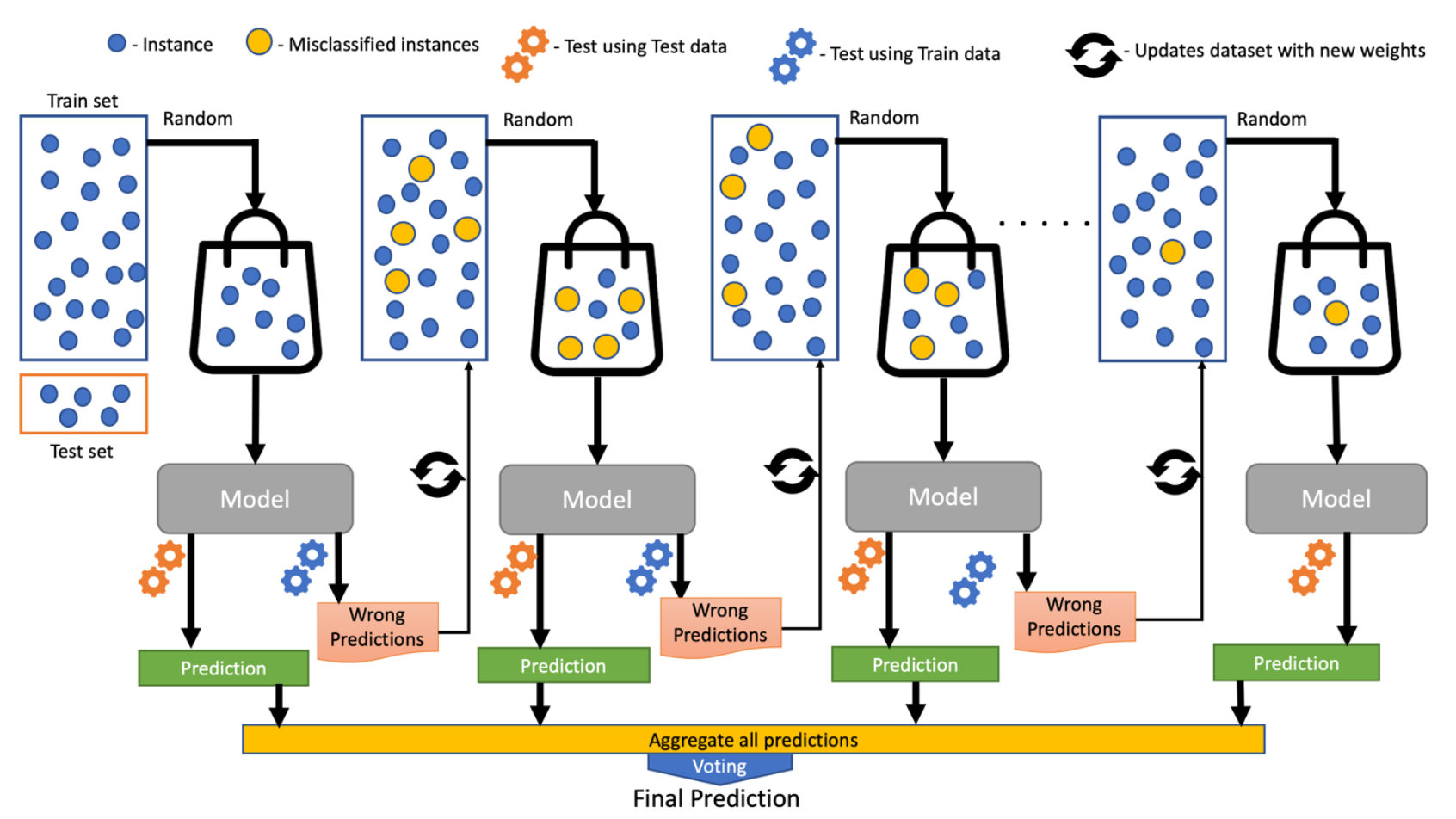
提升算法的内部工作
感觉被做好了准备?在深入探讨该主题之前,请查看另外两种算法(CART 和梯度提升),以了解 XGBoost 的机制。
分类和回归树 (CART):
决策树是一种受监督的机器学习算法,用于根据多个独立变量的输入预测对因变量(目标)进行建模。它有一个树状的结构,根在顶部。代表分类和回归树的 CART 用作总括术语,用于指以下类型的决策树:
分类树:当目标变量是固定的或分类的,此算法用于标识目标最有可能落在其中的类/类别。
回归树:目标变量是连续的,树/算法用于预测其值,例如预测天气。
渐变提升:
梯度提升是提升算法的一个特例,其中通过梯度下降算法将误差降至最低,并生成弱预测模型(例如决策树)形式的模型。
提升和梯度提升之间的主要区别是算法如何从错误的预测中更新模型(弱学习者)readthedocs.io/en/latest/gradient_descent.html”rel=”nofollow”目标=”_blank”=梯度下降,通过更新权重来迭代优化模型损失。损失通常是指预测值和实际值之间的差值。对于回归算法,我们使用 MSE(均方误差)损耗,而对于分类问题,我们使用对数损耗。
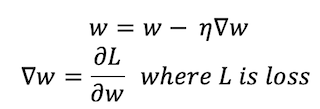
w represents the weight vector, η is the learning rate
梯度提升过程:
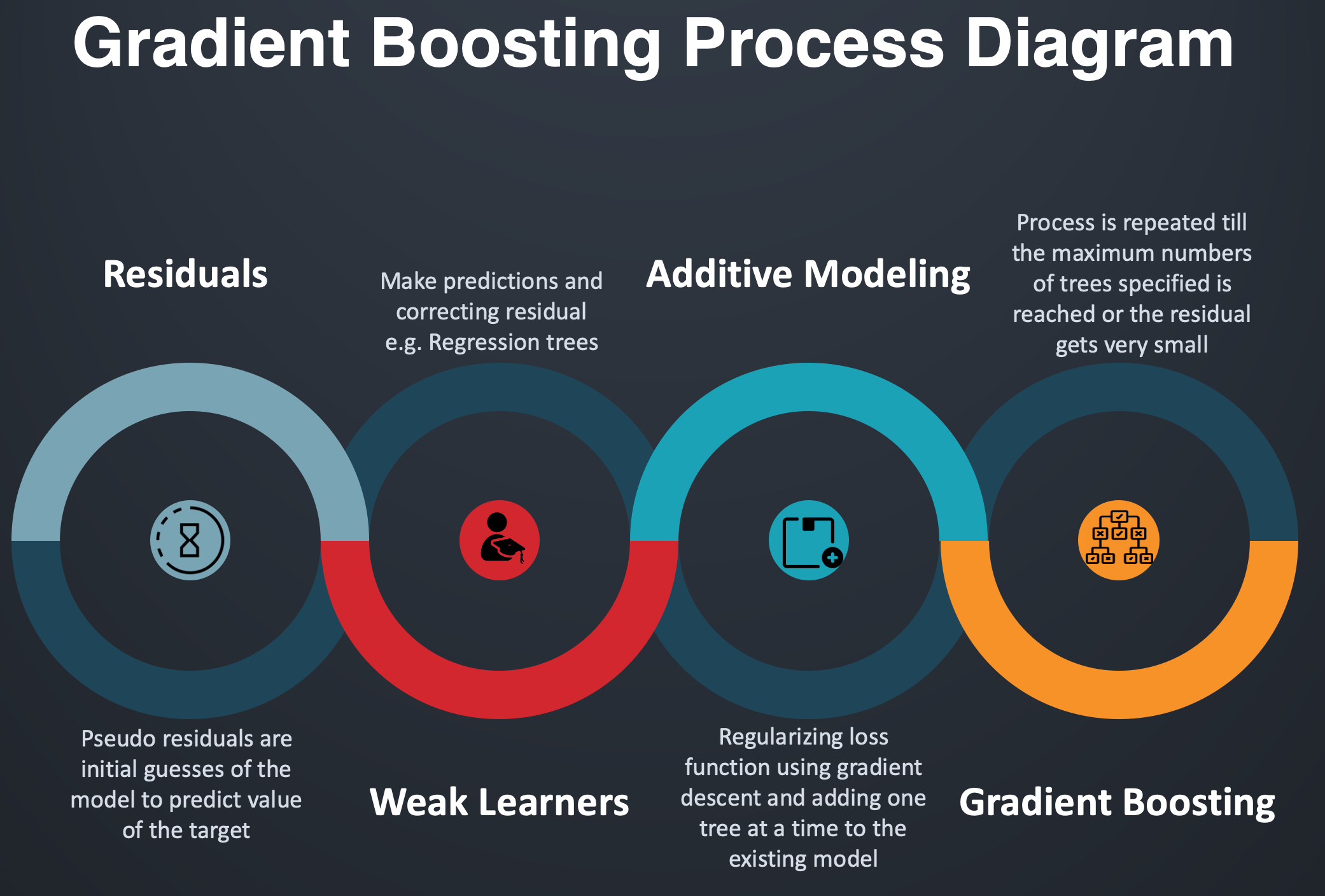
梯度提升的过程流
渐变提升使用附加建模,其中一次向模型添加新决策树一个,使用梯度下降将损失降至最低。模型中的现有树保持不变,从而减慢了过度拟合的速度。新树的输出与现有树的输出相结合,直到损失最小化到阈值或达到指定的树限制。
数学中的增增建模是函数细分为 N 子函数的添加。在统计方面,它可以被看作是一个回归模型,其中响应y是预测变量x的个体效应的算术总和。
XGBOOST 在行动!
是什么让 XGBoost 成为赢得机器学习和卡格尔竞赛的算法?
在ML中,我们尽量最小化作为损耗函数和正则化术语组合的客观函数。 2.自定义评估指标– 这是用于监视模型验证数据准确性的指标。 XGBoost 使用内置的交叉验证函数 cv():
01, 1.01, 0.01, 使用网格搜索输出 使用随机搜索输出 网格搜索的总配置 = 2⁄4*1*3*3 = 72
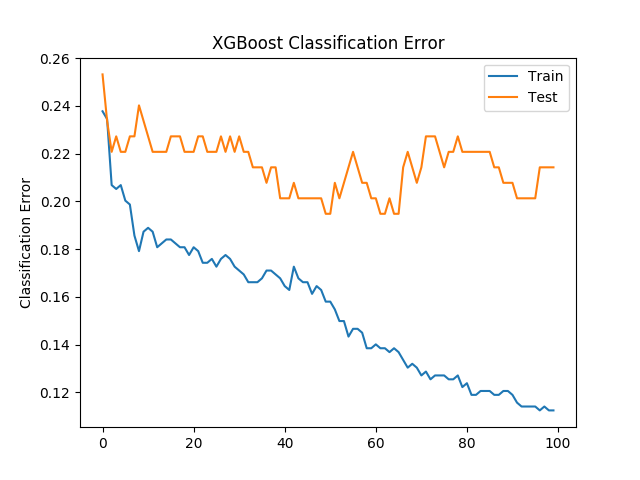
• 将数据拆分为 X 和 y • 潜入火车和测试 • XGB 分类器 • 使分类器适合训练集 • 预测测试集的标签:预置 • 计算精度:准确性 • 绘图分类错误 xgboost 分类精度 分类错误 2. 使用 XGBoost 回归: 2.1. 决策树基学习
9896px;"> xgboost 回归的方差,决策树作为基础学员 使用决策树(XGB 回归器)的树图 2.2. 线性基础学习
XGBoost 库提供内置功能,用于绘制按其重要性排序的要素。函数为plot_importance(模型),并将训练的模型作为其参数。该函数提供了一个信息丰富的条形图,表示每个要素的重要性,并根据数据集中的索引命名它们。重要性是根据采用参数的importance_type变量计算的 外壳数据集的功能重要性分析 感谢您阅读本文! 合著者 – 罗汉·哈罗德,阿卡什·辛格·昆瓦尔 [1] https://arxiv.org/abs/1603.02754
算法增强功能:
系统增强功能:
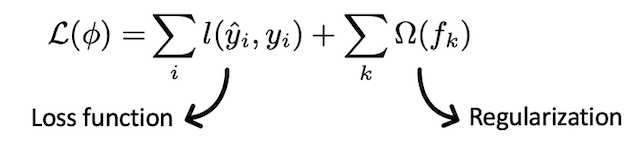
L(Φ) is objective function
交叉验证:
xgb.cv() 想弄湿你的脚吗?(这是编码时间)
xxxxxxx
• XGBOOST 模型调优
将xgboost导入 xgbxgb
导入数字为np
从sklearn.model_selection导入网格搜索CV
从sklearn.model_selection导入随机搜索CV
Xyload_boston(return_X_y=真实)
dmatrixxgb.DMatrix(数据=X标签=y)
• 网格搜索参数
"colsample_bytree": [0.30.7],
'learning_rate': [0.010.10.20.5],
"n_estimators": [100],
"子样本": [0.20.50.8],
'max_depth': [235]
}
grid网格网格搜索CV(估计器=xg_grid_regparam_gridparam_grid=grid_search_params评分="neg_mean_squared_error",
cv=4详细=1iid=真实)
网格。适合(Xy)
打印("找到的最佳参数:"网格grid。best_params_)
打印("最低 RMSE 发现:"npnp。平方(np.abs(网格.best_score_)))
• 随机搜索参数
params_random_search |
"learning_rate"np
'n_estimators': [200],
'max_depth'范围(212)
"子样本"npnp。范围(0.021.020.02)
}
XGB回归器(目标= "reg:平方错误")
randomized_mse随机搜索CV(param_distributions=params_random_search估计器=xg_random_reg,
评分="neg_mean_squared_error"n_itern_iter=5cv=4详细=1iid=真)
randomized_mse.适合(Xy)
打印("找到最佳参数:"randomized_mse。randomized_msebest_params_)
打印("最低 RMSE 发现:"npnp。平方(np.abs(randomized_mse。best_score_)))


随机搜索的总配置 = 100*1*10*50 = 50000
可伸缩性:
X = df_:, 0:8]
y = df_:, 8]
X_train、X_test、y_train、y_test = train_test_split(X、y、test_size=0.2、random_state=123)
xg_cl = xgb。XGB类分类器(目标='二进制:物流',n_estimators=100,种子=123)
eval_set [ [(X_train、y_train)、(X_test、y_test)]
xg_cl.fit(X_train、y_train、eval_metric="错误"*,eval_set=eval_set,详细=真实)
结果 = xg_cl.evals_result()
预测 = xg_cl.预测(X_test)
精度 = 浮点(np.sum(预测 = y_test))/y_test.shape{0}
打印("精度:%f" % (精度=100))
纪元 = len(结果[validation_0]"错误"*
x_axis = 范围(0,纪元)
无花果、斧头 = 图。子图()
ax.plot(x_axis,结果[validation_0'"错误",标签['火车')
ax.plot(x_axis,结果[validation_1'"错误",标签='测试')"数据-朗="文本/x-python"*xxxxxxx
导入数字为np
从数字进口负载txt
将xgboost导入 xgbxgb
从垫图利布导入pyplot
从sklearn.model_selection导入train_test_split
dfloadtxt('./数据集.csv'分隔符=",)
• 将数据拆分为 X 和 y
Xdf0:8|
ydf8|
X_trainX_testX_testy_trainy_testy_testtrain_test_splity_testtrain_test_split(Xytest_size=0.2random_state=123)
• XGB 分类器
xg_clxgb。XGBClassififs(目标='二进制:物流'n_estimators=100种子=123)
eval_set [(X_trainy_trainy_train) (X_testy_testy_test) ]
xg_cl。拟合(X_trainy_traineval_metricy_traineval_metric="错误"eval_seteval_set=eval_set详细=真实)
结果xg_cl。evals_result()
• 预测测试集的标签:预置
预测xg_cl。预测(X_test)
精度浮点(np.总和(预测y_test)/y_test。/y_test形状[0]
打印("精度:%f"% % (精度=100))
• 绘图分类错误
纪元len(结果='validation_0]="错误"*)
无花果axpyplot.子图()
ax.绘图(x_axis结果="validation_0"="错误"标签="培训"
ax.绘图(x_axis结果="validation_1"="错误"标签="测试"

xxxxxxx
# XGBOOST 回归 - 基于决策树
将xgboost导入 xgbxgb
进口熊猫作为pd
从sklearn.model_selection导入train_test_split
从sklearn.指标导入explained_variance_score
• KC 房屋数据
dfpd.read_csv('/kc_house_data.csv)
df_traindf="卧室""浴室""sqft_living""地板""海滨""查看""等级""拉特"yr_built"sqft_living15"]]'yr_built''sqft_living15'
Xdf_train。值
ydf.价格.值
X_trainX_testX_testy_trainy_testy_testtrain_test_splity_testtrain_test_split(Xytest_size=0.2random_state=123)
• 拟合 XGB 回归模型和默认基础学员是决策树
xgb_regxgb。XGB 再向器(目标="reg:线性"n_estimators=75子样本=0.75max_depth=7)
xgb_reg。适合(X_trainy_train)
预测xgb_reg。预测(X_test)
• Variance_score
打印((explained_variance_score(预测predictionsy_test))
• 将数据表转换为矩阵
kc_dmatrixxgb
• 创建参数字典:参数
参数= "目标""reg:线性""max_depth"2|
• 训练模型:xg_reg
xg_regxgb.火车(参数=参数dtrain=kc_dmatrixnum_boost_roundnum_boost_round=10)
xgb.plot_tree(xg_regnum_treesnum_trees=0)
xgb.plot_importance(xg_reg)
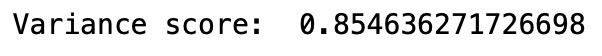
xxxxxxx
# XGBOOST 回归线性基础学习
导入数字为np
将xgboost导入 xgbxgb
从sklearn.数据集导入load_boston
从sklearn.指标导入mean_squared_error
• 线性基础学员
Xyload_boston(return_X_y=真实)
• 训练和测试拆分
X_trainX_testX_testy_trainy_testy_testtrain_test_splity_testtrain_test_split(Xytest_size=0.2random_state=123)
• 将训练和测试集转换为 DMatrix
boston_trainxgb.DMatrix(数据=X_train标签=y_train)
boston_testxgb。DMatrix(数据=X_test标签=y_test)
• 具有助推器的参数为线性基础学员的 gb 线性
参数= "助推器""gb线性""目标""reg:线性"|
• 训练模型:xg_reg
xg_regxgb.火车(参数=参数dtrain=boston_trainnum_boost_roundnum_boost_round=5)
• 进行预测
预测xg_reg。预测(boston_test)
• 计算 RMSE
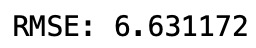 使用 xgboost 回归与线性基础学习者的 rmse
使用 xgboost 回归与线性基础学习者的 rmse
绘制重要性模块:
权重(默认) = 告诉要素在树中显示的时间
增益 = 是使用功能时获得的平均训练损失
"覆盖" - 它告诉拆分的覆盖范围,即要素使用的次数由该分支中的总训练点加权。xgb.plot_importance(model)
引用
[2] https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/
[3] https://explained.ai/gradient-boosting/index.html
[4] https://github.com/dmlc/xgboost
[5] https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205