
Apache Kafka 添加了分层存储来分离计算和存储。该功能可实现更具可扩展性、更可靠且更具成本效益的企业架构。这篇博文探讨了在 Kafka 提交日志中存储 PB 级数据的架构、用例、优点和案例研究。最后讨论了为什么分层存储不会取代其他数据库,以及 Apache Iceberg 如何进一步改变未来的 Kafka 架构。

计算与存储与分层存储
让我们定义术语“计算”、“存储”和“分层存储”,以便在数据流平台 Apache Kafka 的上下文中探索这些术语时具有相同的理解。
计算和存储
计算系统的两个基本组件是计算和存储。它们在信息处理中具有不同的目的。
计算是指计算机系统执行任务、执行指令和进行计算的处理能力和能力。计算组件包括CPU(中央处理单元)和GPU(图形处理单元)。
存储是指长期存储和检索数据的组件和系统。这是持久维护数据以供以后使用的地方。存储包括硬盘驱动器 (HDD)、固态驱动器 (SSD) 和其他类型的非易失性存储器(例如即使在电源关闭时也能保留数据的数据库)等设备。
分层存储
分层存储是指根据数据的访问模式、性能要求和成本考虑,使用不同类别或存储层(例如 S3 上的对象存储)来高效管理和存储数据的存储架构。
分层存储的目标是根据数据的特性和组织的策略将数据放置在最合适的存储介质上,从而优化存储资源的使用,平衡性能和成本。
这些层之间的数据放置和移动可以根据分析使用模式、访问频率和其他因素的策略和算法实现自动化。这可以确保最关键和最频繁访问的数据位于高性能存储中,而不太重要或不经常访问的数据则转移到成本较低、性能较低的存储中。
Apache Kafka 中的长期存储
Apache Kafka 是一个开源分布式流平台,用于构建实时数据管道和流应用程序。 Kafka 是数据流的既定事实上的标准。事件流平台可处理大量数据,提供可扩展且容错的架构。
应用程序和数据存储使用 Kafka 来摄取、存储和处理实时数据流,使其成为构建需要处理连续数据流的事件驱动架构和系统的基本组件。此外,许多用例不仅利用 Kafka 来获取实时数据,还确保实时、批处理和请求响应 API 之间的数据一致性。
Apache Kafka 作为存储系统的用例
虽然大多数人将 Kafka 视为消息代理、实时分析平台或大数据摄取系统,但具有排序保证和时间戳的分布式提交日志支持大量用例,用于在数据创建后很长时间内访问数据或重放历史数据数据。
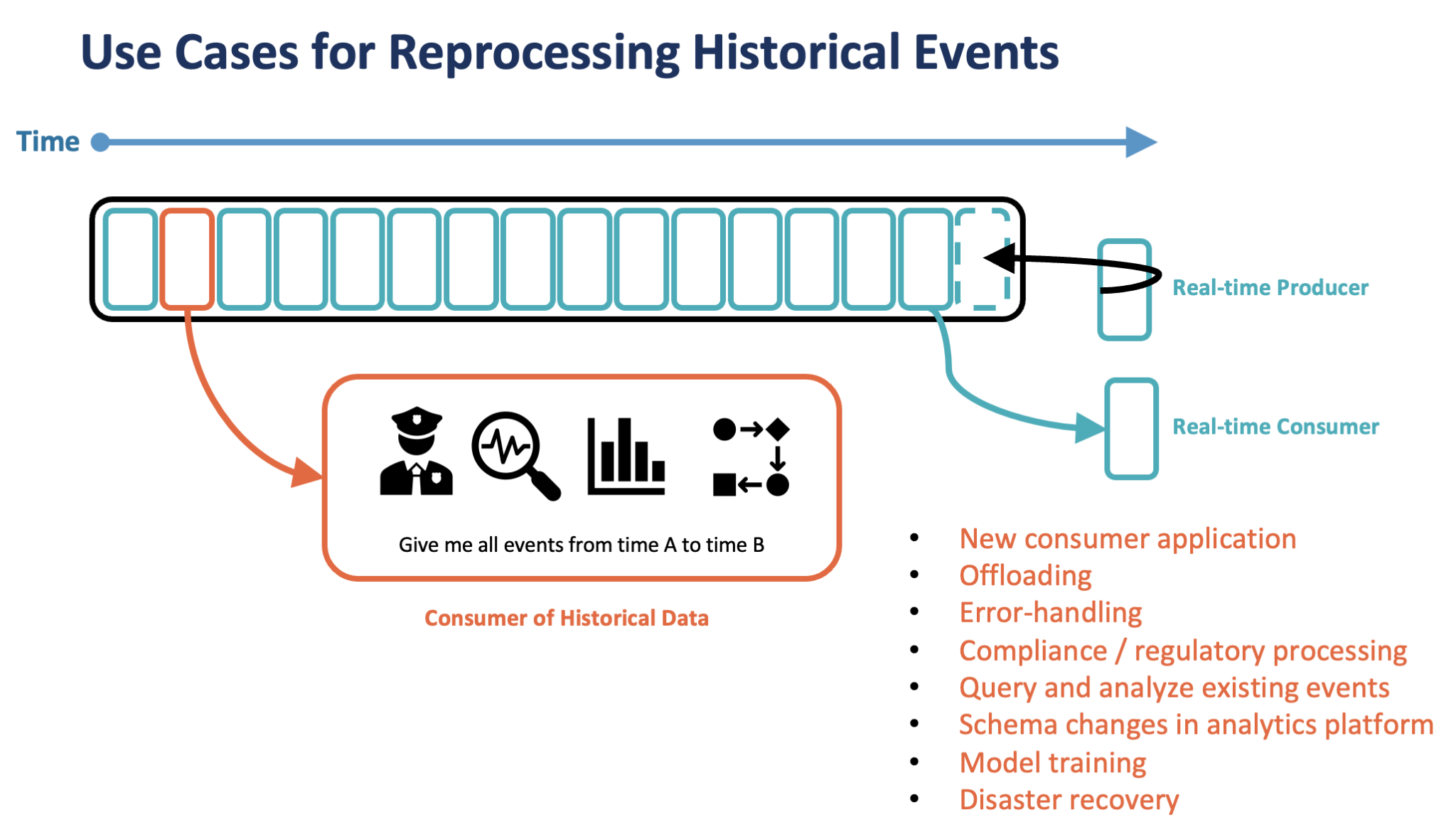
以下是利用 Kafka 中数据长期存储的一些用例示例:
- 新使用者:部署新的应用程序/数据库/数据仓库、数据湖,并同步业务对象的状态。
- 卸载:不再从昂贵或不可扩展的系统(例如大型机和 MIPS)中反复消耗资源,从而显着降低成本
- 错误处理:修复业务逻辑中的问题后重新处理历史数据。
- 合规/监管处理:重播历史数据以分析事件。
- 查询和分析现有事件:使用笔记本中的数据进行数据工程、分析或报告。
- 分析平台中的架构更改:更新数据合约后重新处理数据。
- 模型训练:批量摄取到 AI 框架中以应用机器学习算法
- 灾难恢复:发生故障时,操作数据存储会再次从持久提交日志中重放数据。
反对在 Kafka 中长期存储数据
在 Kafka 中长期存储数据有一些缺点。以下论点是有效的担忧:
- 成本:在附加磁盘上存储大量数据比对象存储等外部存储系统昂贵得多。
- 可扩展性:操作具有大量数据(例如数 GB、甚至 TB 等)的 Kafka 代理具有挑战性,尤其是在需要重新平衡分区时发生故障的情况下。
- 风险:如果操作处理大量数据或需要迁移硬件,就会发生停机或数据不一致。
因此,如果没有分层存储,您不应该将大数据集存储在 Kafka 中!考虑到这一点,我们来探讨一下 Kafka 分层存储如何解决这些问题。
引入 Apache Kafka 分层存储
Apache Kafka 的后端是一个运行 Kafka 代理的分布式系统。每个 Kafka Broker 都具有处理和存储能力。
应用程序是事件的生产者和消费者。许多接口与 Kafka 代理进行通信:
- 使用 Java、Python、C++、Go 或任何其他编程语言编写的应用
- 连接到 IBM MQ、Spark、Snowflake 或任何其他数据存储或 SaaS 应用程序的 Kafka Connect 源或接收器连接器
- 使用 Kafka 原生 Kafka Streams、KSQL 或 Apache Flink 等外部基础设施构建的流处理器
- 任何其他端点,例如 HTTP 接口或其他中间件或数据平台的开箱即用集成
什么是 Kafka 分层存储?
Apache Kafka 的分层存储是指根据 Kafka 代理中存储的数据的访问模式和要求配置不同的存储层来优化存储基础设施的能力。
Kafka集群将数据存储在Kafka Topics中。这些主题在重要性、访问频率和保留策略方面可能具有不同的特征。
这个概念就像存储系统中分层存储的一般概念,但它适应了 Kafka 的特定需求。分层存储是Kafka架构云原生的关键因素之一。
没有分层存储的Kafka架构
Kafka 应用程序与逻辑 Kafka 主题进行通信,以向分区生成消息或使用来自分区的消息:
存储是连接到代理的磁盘。这可以是本地 HDD 或 SDD 磁盘,也可以是 AWS 云上的 EBS 卷。
具有分层存储的Kafka架构
Kafka 分层存储不会改变应用程序与 Kafka 代理通信的方式。分层存储是一个实现细节:
除了连接到代理的磁盘之外,Kafka将数据卸载到外部存储。大多数情况下,这是对象存储,例如 Amazon S3、Azure Blog Storage、Google Cloud Storage 或 MinIO for Kubernetes。
无服务器云产品为运营商处理卸载。自我管理的解决方案允许操作员为每个 Kafka Topic 配置热存储和冷存储持续时间。
Apache Kafka 分层存储的优势
让我们回顾一下上面讨论的在 Kafka 中长期存储大数据集的反对意见以及分层存储如何提供帮助:
- 降低成本:大多数数据都转移到外部存储。这显着降低了存储成本。
- 提高可扩展性:只需重新平衡附加到 Kafka 代理的磁盘上的数据。由于大多数数据都已卸载,因此即使外部存储节省了 PB,重新平衡也只需几秒钟或几分钟。
- 降低风险:更好的可扩展性以及计算与存储的分离使操作变得更加轻松,并显着降低了停机或数据不一致的风险。
Apache Kafka分层存储的实现
Apache Kafka 的分层存储现已推出。但是,请注意,不同的实现具有不同的功能、成熟度和支持级别。
而开源的Apache Kafka只提供了分层存储的接口。您必须选择开源实现,构建自己的与外部存储系统的集成,或者利用将分层存储嵌入到其产品中的商业产品或云服务。
请记住,仅靠界面是没有帮助的。实施需要经过实战检验,并保证代理上的热存储和外部存储中的冷存储之间的数据一致性,即使在出现故障、网络问题等情况下也是如此。
Kafka消费者看不到Kafka分层存储的实现细节。他们只是消费,就好像没有分层存储实现一样(并且仍然期望相同的行为)。 Kafka 客户端应用程序不需要更改 API 或代码。因此,您可以利用分层存储轻松将现有部署迁移到 Kafka 集群。
很多人询问分层存储对 Kafka 的性能影响。简短的回答:对于大多数场景来说,不会产生性能影响。实时消费者像以前一样从内存/页面缓存中消费。并且从事件日志中重放历史数据与本地磁盘或远程对象存储没有太大区别。
AK 3.6 版本提供分层存储
撰写本博文时(2023 年 12 月),KIP-405:Kafka 分层存储可在 Apache Kafka 3.6 中作为早期访问。此版本向 Kafka 引入了分层存储。此版本仅适用于非生产环境(请参阅早期访问注释以获取更多信息)。
此功能的正式发布只是一个可以预见的时间问题。 KIP-405 的大部分内容是 3.6 版本中抢先体验的一部分。但 3.7 中还有一些额外的功能。 GA 可能会在 3.8+ 之后出现。
KIP-405 提供用于分层的可插拔存储 API
KIP-405 将 Kafka 代理中的计算和存储分开,以便在 Kafka 分层存储中本地实现可插拔存储分层,从而以最小的操作更改为远程对象带来无缝存储扩展。
Apache Kafka 的 LocalTieredStorage 默认实现是基于本地文件的 RemoteStorageManager。 LocalTieredStorage 有助于在测试期间在受控和隔离的环境中模拟远程存储行为。这不适用于生产用例!企业需要编写自己的实现,嵌入开源替代方案,或者信任软件供应商或云服务。
Confluence、Uber 和其他公司如何使用分层存储
KIP-405 仅在 Kafka 3.6 预览版中可用。然而,一些专有的实现已经在生产中存在多年。这也有助于根据在生产环境中使用分层存储运行 Kafka 的经验教训来定义 KIP。
Kafka 分层存储的实现细节各不相同,并且可能有不同的方法或工具可用于实现此目的,具体取决于所使用的特定 Kafka 发行版或存储基础设施。组织还可以使用外部系统或云存储解决方案来实施 Kafka 的分层存储策略。
Confluence 开创了 Kafka 分层存储的先河,并已提供该功能多年。它可用于 AWS、Azure 和 GCP 中的自我管理 Confluence 平台和完全托管的 Confluence 云。 Confluence 选择 S3 接口来为云提供商(AWS、Azure、GCP)和多个本地解决方案(例如 PureStorage Flash Blade、Nutanix Objects、Netapp 对象存储、Dell EMC ECS、Hitachi Content Platform 对象存储或 MinIO)实现存储支持对于 Kubernetes。
Uber 率先在开源 Apache Kafka 中实现了 KIP-405,并针对 HDFS 运行其分层存储。 Confluence 和 AWS 为重构、最佳实践和性能/集成测试做出了贡献。 Uber 数据和流基础设施技术主管 Satish Duggana 在 Current 2023 演讲。
其他供应商(例如 AWS、MSK 和 Aiven)正在采用 KIP-405 并提供自己的分层存储实现。
案例研究:KOR Financial 在 Kafka 中存储 160 PB 数据用于监管报告
KOR 是全球贸易存储库和监管报告服务的云原生系列,它采用了 Confluence Cloud 和数据流架构来改进合规流程。
监管报告显然是 Kafka 中的分层存储重播历史数据的完美用例。由于 Kafka 日志提供有保证的排序和时间戳,因此除了 Kafka 之外不需要其他数据库或数据湖。
Daan Gerits,KOR Financial 首席数据官,在 Diginomica 解释道:“在 KOR Financial,我们正在努力解决一个非常具体的问题,那就是为监管机构收集交易信息。我们决定这样做它的方式与大多数人的方式完全不同。其他人会使用数据存储或大数据技术,我们决定全力以赴使用 Kafka。我们正在构建我们的系统,在 Confluence Cloud 中存储 160 PB,然后在此基础上工作。我们没有任何其他数据库。所以这是一个长期保留用例。”
Kafka 不是数据库(替代品)
Apache Kafka 是一个数据库。它提供 ACID 保证。数百家公司部署 Kafka 进行关键任务部署,包括事务工作负载。然而,大多数时候,Kafka 与其他数据库没有竞争力。

Kafka 是一个事件流平台,用于实时大规模消息传递、存储、处理和集成,实现零停机和零数据丢失。几乎所有部署都将 Kafka 连接到数据库源和接收器,以实现数据集成、解耦和数据一致性,其中云原生企业架构的核心是实时、可扩展和可靠。
Apache Kafka 是对数据库、数据仓库、数据湖和 Lakehouse 架构的补充。
未来:Kafka 的 Apache Iceberg?
Apache Kafka 分层存储的采用才刚刚开始。许多团队将在 Kafka 中存储(某些)数据更长时间,以便从昂贵的系统中卸载数据或重放历史数据,而无需另一个数据库。
但是,大多数分析平台不使用 Kafka 协议来消费和查询数据。大多数数据平台的趋势都是将 Apache Iceberg 作为标准化抽象层,用于在对象存储或其他存储中存储和查询(非实时)数据。
Apache Iceberg 是一个开源的大数据表格式和处理框架。它旨在提供两全其美的功能:传统表格式的性能和读取模式方法的灵活性。 Iceberg 提出了在分布式存储环境中管理大规模且不断变化的数据集的解决方案。
Apache Iceberg 支持流行的数据处理框架,例如 Apache Spark、Apache Flink、Apache Hive、Presto 等。借助 Kafka 的分层存储,尤其是一些供应商对 S3 的支持,我可以看到这如何成为一个完整的游戏规则改变者,用于使用 Kafka 协议或其他分析引擎和数据库近乎实时地实时存储和处理事件或批次。
未来将向我们展示。现在,让我们对 Kafka 的分层存储如何成为数据流领域的下一个重大事件感到兴奋。
分层存储使 Kafka 更具可扩展性、成本效益和可靠性
Apache Kafka 的分层存储使事件驱动的架构更具可扩展性、成本效益和可靠性。它支持过去需要另一个数据库或数据湖的新用例。
但是,Kafka 的目标仍然不是取代其他数据和分析平台。微服务和数据网格等设计模式实现了应用程序和数据存储的真正解耦。 Kafka 提供了这种解耦。考虑到各种用例(例如卸载、新消费者或错误处理)的分层存储,您可以考虑针对云原生企业架构的新方法。
您对 Apache Kafka 的分层存储感到兴奋吗?你将如何使用它?或者您是否已经使用现有的实现,例如 Confluence Cloud?让我们在 LinkedIn 上联系并进行讨论!加入数据流社区并通过订阅我的时事通讯.




