
随着会话语言接口开始主导客户服务,对聊天机器人的反弹也越来越大。Forrester去年预测,2019年将是对低效聊天机器人的反弹的一年,看起来他们是对的。例如,一项由开放软件服务公司Acquia委托进行的一项调查发现,45%的消费者认为聊天机器人”令人讨厌”。
同时,对话性 AI 在当今业务中的重要性怎么估计也不过分。如果做对了,对话式 AI 能够显著提高您的竞争优势,并从根本上改变业务与客户互动的性质。
根据Gartner 的数据,到 2021 年,超过 50% 的企业每年在机器人和聊天机器人创建方面的支出将超过传统的移动应用开发。到 2022 年,聊天机器人预计将减少 80 亿美元的业务成本,到 2023 年,企业和消费者都将通过使用聊天机器人节省 25 亿小时。
到 2024 年,全球聊天机器人的总市场规模预计将超过 13 亿美元。
那么,消费者对聊天机器人的不满情绪日益高涨的原因是什么?
有些原因很简单,众所周知。例如,许多公司依赖聊天机器人做太多,而未能提供人类的”安全网”(即,在需要时向现场代理移交的快速而高效的方法)。一些聊天机器人反应太慢(有些不自然快)。在其他情况下,聊天机器人的个性与品牌的声音完全不一致。一些企业部署了半生不熟的聊天机器人,最终对其客户进行培训,这往往最终成为一个致命的错误artificial-solutions.com/chatbots#3″rel=”不跟随”目标=”_blank”,聊天机器人未能交付只是手头任务的复杂性。我们与技术的互动中渗透的交谈 AI 越多,人们就越希望这些交互类似于自然的人类对话,期望对自然表达的问题和请求做出明智的响应。但问题是,一旦你离开简单的命令-响应交互,你最终就进入人类语言极其复杂的地形。我们完全想当然地认为(说话),甚至一个三岁的人类孩子也能做到,这是令人难以置信的困难,教机器做。
以下是我们每次张开嘴说话时都无需思考地使用人类语言的一些常见特征,但许多聊天机器人很难掌握。
习语
有时我们使用具有其预期含义的词,但在许多情况下,我们使用它们作为成语。成语是一组单词,其意义不能从单个单词的含义中推断出来,而必须记住。
在下面的错误中,Siri 从字面上解释成语”做笔记”,从单个单词的含义推断出来,而这个人实际上是使用它作为表示”记住某事”的表达方式:
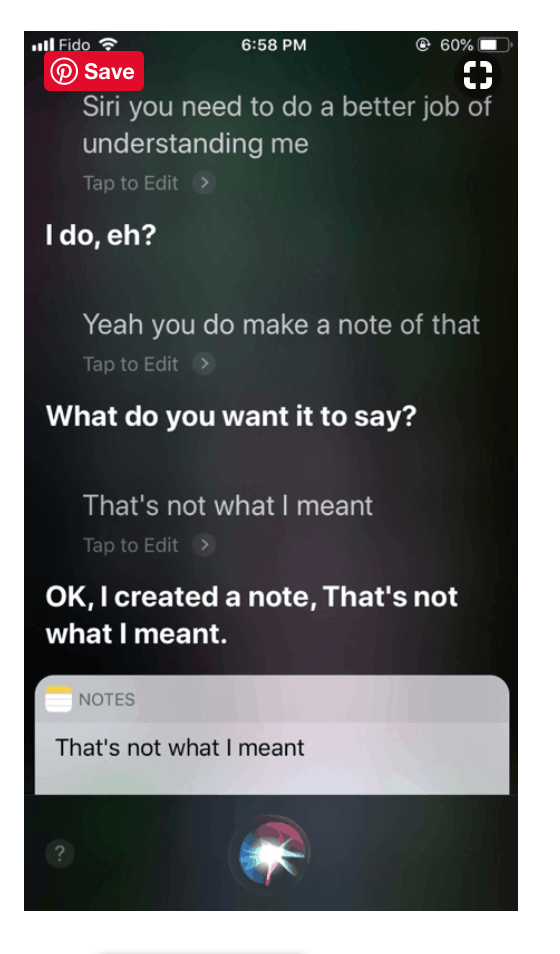
虽然人类依靠上下文和其他线索来确定这些单词是否被用作成语,但许多聊天机器人却不能轻易这样做。你只能想象当聊天机器人从字面上解释其他习语时,会出现尴尬的互动。例如,”煮血”是指”让别人生气”(医疗聊天机器人会引导你出现症状和原因吗?)、”打定主意”、”让你的一天”,”下雨的猫和狗”,”断腿”,”在空中”和”一块蛋糕”。
代词
可以教授名词、动词和其他词汇项的含义。但代词是棘手的,因为它们指的是前面提到的上下文。每个代词都需要一个先验,即它所指的实体或个人,前面在上下文中提到。但在某些情况下,有不止一个可能的前兆,听者的工作是基于上下文选择正确的。
因此,假设您刚刚离开家上班,并且正在联系您的数字助理,并提出以下请求:
人:关掉客厅的灯,关掉咖啡壶
机器人: 好
人类:今天下午6点重新打开
这里第二句中的”它”模棱两可,因为它可以指咖啡壶或客厅的灯光
另一个示例:
“詹妮弗邀请阿曼达来访,她给了她一she顿丰盛的晚餐。
一个人可能会从背景中找出,”她”在这里最有可能提到詹妮弗,而”她”阿曼达,只是因为我们知道,这是更有可能的人谁延长邀请提供晚餐。
现在考虑一下:
“珍妮弗邀请阿曼达参观,她给了她一条漂亮的项链。
谁把项链给了谁?与赠送项链相关的社交习俗比晚餐服务少,因此即使人类也不确定这里的意图。
“珍妮弗邀请阿曼达参观,但她告诉她,她要出城。
詹妮弗邀请阿曼达来访,并立即让她知道她那天的旅行计划,这很奇怪。这就是我们知道的是阿曼达即将出城,因此不能接受邀请。
再次,只有背景和社会规范的知识,让我们找出正确的含义,你的会话AI需要足够先进,以便能够学习它。
现在,考虑在任何特定上下文中可以具有的代词可能有多少可能。
“安娜告诉布赖恩,她决定在英国花一年时间学习创造性写作。
“这将是她一生的工作。(即=创造性写作)
“她这样做后,她会回来和他住在一起。(那一年在英国度过)
“这就是她整个星期的想法”(那 = 决定)
“这开始了两个小时的战斗。(告诉布赖恩)
现在,你如何教普通聊天机器人之类的东西?
结构模糊性
有些模棱两可是结构性的。例如,”鸡已经准备好吃”一语可能意味着鸡肉在桌子上,或者你需要喂你的宠物鸡。聊天机器人需要被教导很多关于世界和个人情况的背景(例如,你个人没有宠物鸡,或者鸡是受欢迎的菜,但不是受欢迎的宠物,或者相反,你是一个素食主义者,有宠物鸡)以正确解释它。
当句子包含一个时间副词和多个动词时,副词修饰的动词并不总是很清楚
同样,在自然对话中,人类要么有足够的上下文来确定使用什么含义,要么知道提出澄清的问题,但大多数聊天机器人在出现时无法辨别结构模糊性。
省略
在口头非正式对话中,我们经常忽略我们知道对方可以根据上下文轻松填写的信息。例如,我们可以说”我对乳制品过敏。鱼” – 它会理解,你对鱼和乳制品过敏,而不是鱼是过敏乳制品。
有时省略号会导致歧义。例如:
- 迈克也爱他的母亲,比尔也爱。(比尔喜欢迈克的妈妈还是他自己的妈妈?
- 安娜在她的房间里,简也是。(简是在安娜的房间还是她自己吗?
更多歧义
在某些情况下,在言语中,我们也许能够借助亲音提示(语调、音调、音调等)找出模棱两可的句子的确切含义。
例如,他们煮苹果的句子可以意味着两件事:
- 他们(即有些人)在煮苹果。
- 这些苹果是做饭的。
人类依靠上下文和语调来正确解释句子,但许多聊天机器人无法访问这些句子。
修辞问题和讽刺
并不是每个问题都需要答案。有些问题是修辞性的,只是传达演讲者的情绪状态,而不是寻求答案。
例如,”你知道什么时候?
“你说我们会在11:00前到达那里!你知道什么时候吗?
如果您的聊天机器人以”上午 11:30″回答了这个问题,则没有理由不将其标记为”讨厌”。
此外,如果聊天机器人无法理解客户何时受到讽刺,则互动将不顺利。例如,假设在回应聊天机器人的不满意的回答时,客户说:”这正是我需要的。我该怎么处理这个?如果您的聊天机器人没有检测到讽刺的语气,但回答”欢迎你”或试图回答这个问题,这个聊天机器人将被视为非常恼人。
幽默中的模糊性
最后,幽默可能是让聊天机器人像人类一样互动是多么困难的最好例子。在以下幽默中,英国喜剧演员吉米·卡尔(Jimmy Carr)用被问到的问题的模糊性和模糊性来创造一种荒谬的幽默互动:
“一位女士与剪贴板停止我在街上,有一天
‘”
如何避免虚张声势
如今,大多数标准聊天机器人的问题在于,他们出售”AI”的承诺,即”机器学习”作为银弹。但是,仅基于机器学习的聊天机器人本质上是黑盒系统,如果没有大量的精心策划的培训数据,它们就无法工作。如果他们不能立即理解你期望他们做什么,开发人员不能轻易调整或充实他们。让他们”改变主意”的唯一方法是添加更多数据。
这些数据不仅需要大量提供,还需要准确、分类且机器可读且相关。公司很少会为每种语言的所有必要功能勾选所有这些框。
幸运的是,有一个解决方案。人工解决方案的 Teneo 平台采用混合方法,依赖于机器学习和语言学习的组合。
也就是说,它利用确实存在的数据,而无需完全依赖它。语言学习的使用统计数据的方式与机器学习系统不同。相反,它是一个基于规则的系统,允许人类监督和微调规则和响应。因此,它允许对如何理解问题和回答进行更多的控制。在语言学习中,如果您希望聊天机器人以不同的方式解释特定句子,只需重新编程规则即可将其告知(而在机器学习中,需要说服系统通过显示该句子来以不同的方式解释该句子。大量的反例)。
简而言之,Teneo 的语言能力允许开发人员直接教授系统正确的响应,然后使其能够使用机器学习来优化其性能。正是这种灵活的混合方法使企业能够创建可靠的对话式 AI 解决方案,帮助他们建立和改善与客户的关系,而不是破坏这种关系。您将如何构建一个不被贴上”讨厌”标签的聊天机器人?