
软件工程师在这个世界上占据着令人兴奋的地位。无论技术堆栈或行业如何,我们的任务都是解决直接有助于实现雇主目标的问题。作为奖励,我们可以利用技术来缓解我们遇到的任何挑战。
对于这个例子,我想重点关注 pgvector(Postgres 的开源矢量相似性搜索)如何实现用于识别企业数据中存在的数据相似性。
一个简单的用例
举一个简单的例子,我们假设营销部门需要为他们计划发起的活动提供帮助。目标是覆盖与软件行业密切相关的行业中的所有 Salesforce 帐户。
最后,他们希望重点关注前三个最相似行业的客户,以便将来能够使用此工具来查找其他行业的相似之处。如果可能的话,他们希望能够提供所需数量的匹配行业,而不是总是返回前三名。
高级设计
此用例以执行相似性搜索为中心。虽然可以手动完成此练习,但我会想到 Wikipedia2Vec 工具,因为已经预先训练好的嵌入为多种语言创建。词嵌入(也称为向量)是包含句法和语义信息的词的数字表示。通过将单词表示为向量,我们可以从数学上确定哪些单词在语义上与其他单词“更接近”。
在我们的示例中,我们还可以编写一个简单的 Python 程序来为 Salesforce 中配置的每个行业创建词向量。
pgvector 扩展需要 Postgres 数据库。但是,我们示例的企业数据当前驻留在 Salesforce 中。幸运的是,Heroku Connect 提供了一种将 Salesforce 帐户与 Heroku Postgres 同步的简单方法,将其存储在名为 <代码> salesforce.account 。然后,我们将有另一个名为 salesforce.industries 的表,其中包含 Salesforce 中的每个行业(作为 VARCHAR 键)及其关联的词向量。
借助 Postgres 中的 Salesforce 数据和词向量,我们将使用 Java 和 Spring Boot 创建一个 RESTful API。该服务将执行必要的查询,并以 JSON 格式返回结果。
我们可以这样说明解决方案的高级视图:

源代码将驻留在 GitLab 中。发出 git push heroku 命令将触发 Heroku 中的部署,从而引入营销团队可以轻松使用的 RESTful API。
构建解决方案
高层设计到位后,我们就可以开始构建解决方案了。使用 Salesforce 登录,我能够导航到帐户屏幕来查看此练习的数据。以下是企业数据首页的示例:
创建 Heroku 应用程序
为此,我计划使用 Heroku 来解决营销团队的请求。我登录到 Heroku 帐户并使用创建新应用程序按钮建立一个名为 similarity-search-sfdc 的新应用程序:
创建应用程序后,我导航到资源选项卡以查找 Heroku Postgres 插件。我在附加组件搜索字段中输入了“Postgres”。
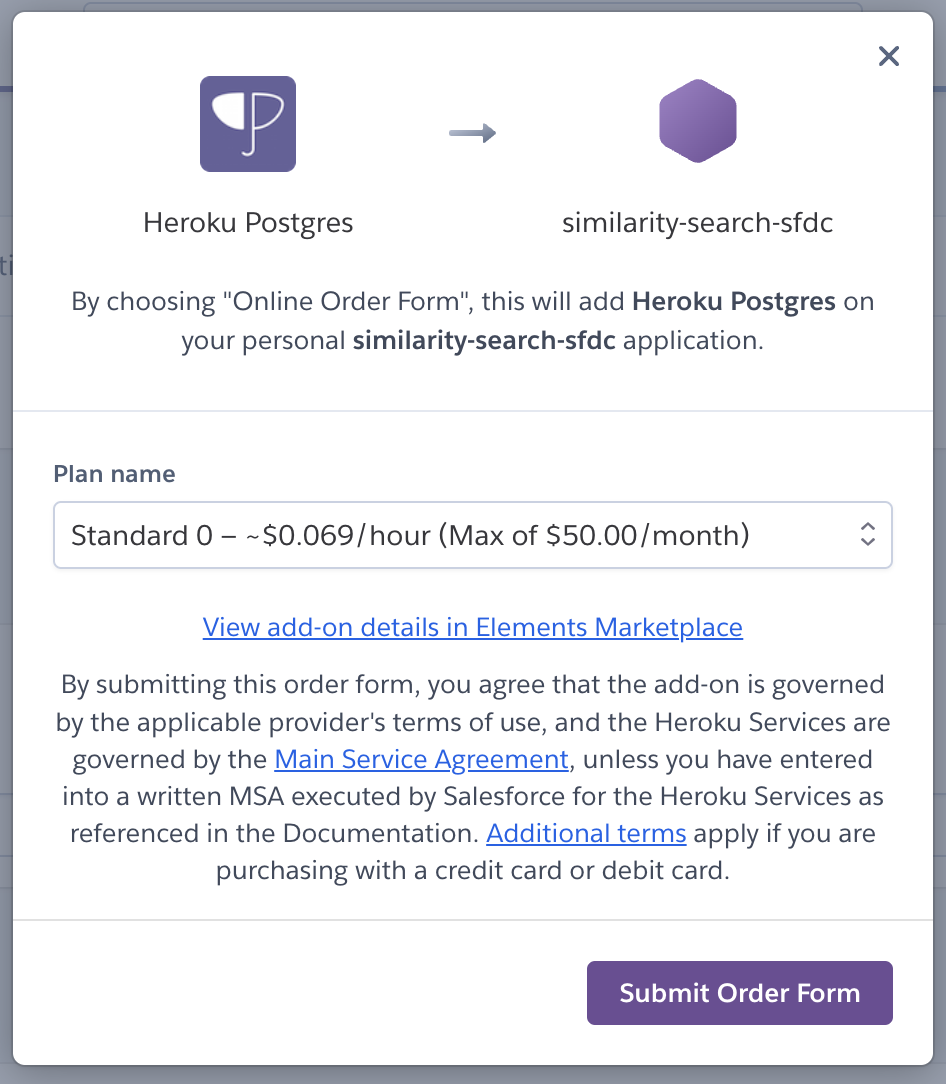
从列表中选择Heroku Postgres后,我选择了Standard 0计划,但pgvector是可在运行 PostgreSQL 15 或 beta Essential 层数据库的标准层(或更高)数据库产品上使用。
当我确认该附加组件时,Heroku 生成并提供了一个 DATABASE_URL 连接字符串。我在应用程序的设置选项卡的配置变量部分中找到了它。我使用此信息连接到我的数据库并启用 pgvector 扩展,如下所示:
创建扩展向量;接下来,我搜索并找到了 Heroku Connect 插件。我知道这将为我提供一种连接到 Salesforce 中的企业数据的简单方法。
对于本练习,免费的演示版计划效果很好。
此时,similarity-search-sfdc 应用的资源选项卡如下所示:
我按照“设置 Heroku Connect”说明链接了我的Heroku Connect 的 Salesforce 帐户。然后,我选择了 Account 对象进行同步。完成后,我能够在 Heroku Connect 和底层 Postgres 数据库中看到相同的 Salesforce 帐户数据。
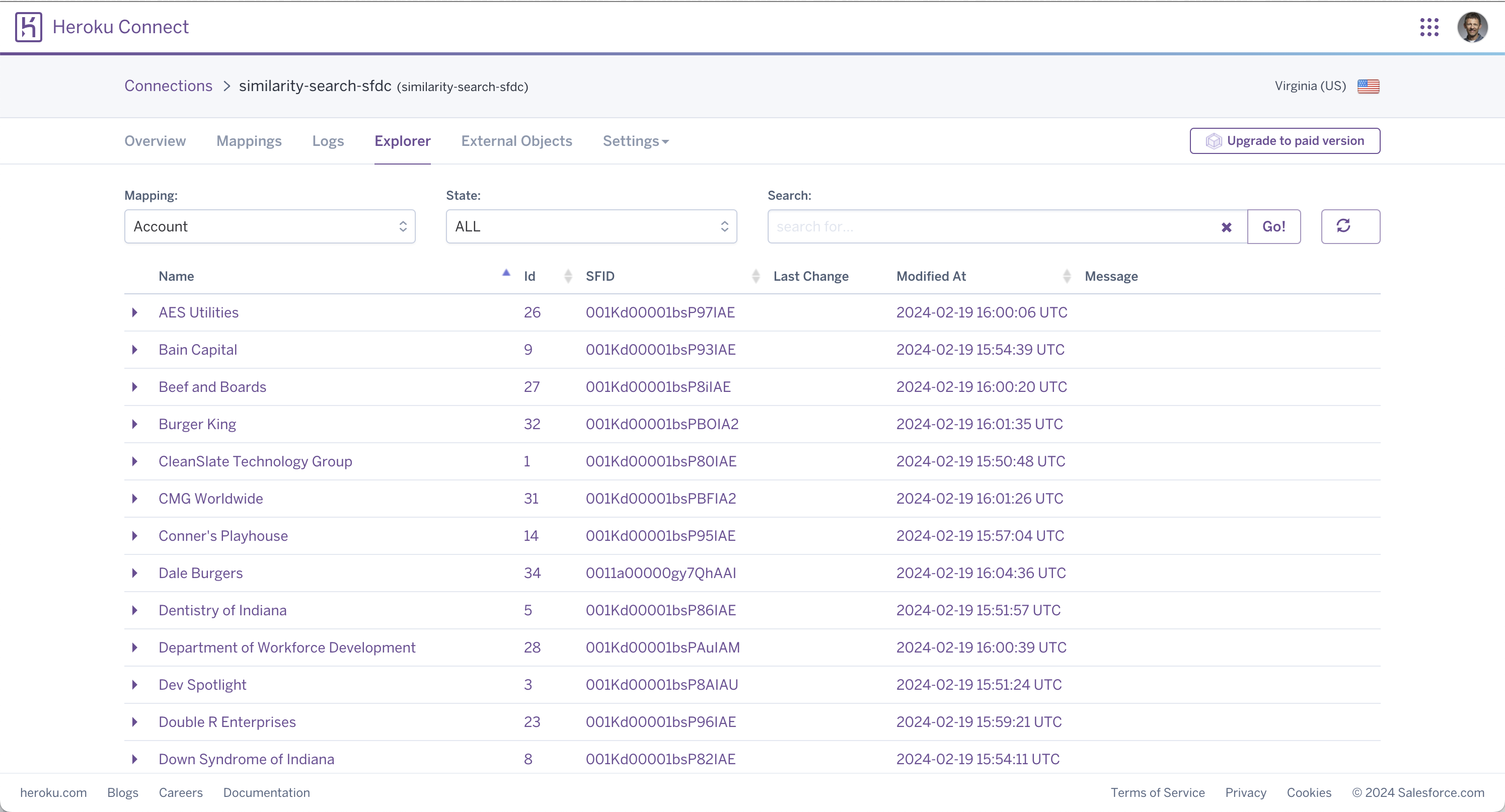
从 SQL 角度来看,我所做的结果是创建了一个具有以下设计的 salesforce.account 表:
创建表 salesforce.account
(
创建日期时间戳,
已删除布尔值,
名称 varchar(255),
systemmodstamp 时间戳,
帐号 varchar(40),
行业 varchar(255),
sfid varchar(18),
序列号
首要的关键,
_hc_lastop varchar(32),
_hc_err 文本
);生成向量
为了使相似性搜索按预期运行,我需要为每个 Salesforce 帐户行业生成词向量:
- 服装
- 银行业务
- 生物技术
- 施工
- 教育
- 电子产品
- 工程
- 娱乐
- 食品和饮料
- 财务
- 政府
- 医疗保健
- 热情好客
- 保险
- 媒体
- 非营利性
- 其他
- 休闲
- 零售
- 运送
- 技术
- 电信
- 交通
- 实用程序
由于主要用例表明需要找到软件行业的相似之处,因此我们也需要为该行业生成一个词向量。
为了使本练习保持简单,我使用 Python 3.9 和一个名为 embed.py 的文件手动执行此任务,如下所示:
从 wikipedia2vec 导入 Wikipedia2Vec
wiki2vec = Wikipedia2Vec.load('enwiki_20180420_100d.pkl')
print(wiki2vec.get_word_vector('软件').tolist())请注意 – get_word_vector() 方法需要使用小写字母表示行业。
运行 python embed.py 为 software 单词生成以下单词向量:
[-0.40402618050575256、0.5711150765419006、-0.7885153293609619、-0.15960034728050232、-0.5692323446273804、
0.005377458408474922、-0.1315757781267166、-0.16840921342372894、0.6626015305519104、-0.26056772470474243、
0.3681095242500305、-0.453583300113678、0.004738557618111372、-0.4111144244670868、-0.1817493587732315、
-0.9268549680709839、0.07973367720842361、-0.17835664749145508、-0.2949991524219513、-0.5533796548843384、
0.04348105192184448, -0.028855713084340096, -0.13867013156414032, -0.6649054884910583, 0.03129105269908905,
-0.24817068874835968、0.05968991294503212、-0.24743635952472687、0.20582349598407745、0.6240783929824829、
0.3214546740055084、-0.14210252463817596、0.3178422152996063、0.7693028450012207、0.2426985204219818、
-0.6515568494796753、-0.2868216037750244、0.3189859390258789、0.5168254971504211、0.11008890718221664、
0.3537853956222534、-0.713259220123291、-0.4132286608219147、-0.026366405189037323、0.003034653142094612、
-0.5275223851203918、-0.018167126923799515、0.23878540098667145、-0.6077089905738831、0.5368344187736511、
-0.1210874393582344、0.26415619254112244、-0.3066694438457489、0.1471938043832779、0.04954215884208679、
0.2045321762561798、0.1391817331314087、0.5286830067634583、0.5764685273170471、0.1882934868335724、
-0.30167853832244873、-0.2122340053319931、-0.45651525259017944、-0.016777794808149338、0.45624101161956787、
-0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0.5830298066139221,
-0.01255014631897211、0.21600870788097382、-0.18419665098190308、0.1754663586616516、-0.1499166339635849、
-0.1916201263666153、-0.22884036600589752、0.17280352115631104、0.25274306535720825、0.3511175513267517、
-0.20270302891731262、-0.6383468508720398、0.43260180950164795、-0.21136239171028137、-0.05920517444610596、
0.7145522832870483、0.7626600861549377、-0.5473887920379639、0.4523043632507324、-0.1723199188709259、
-0.10209759324789047、-0.5577948093414307、-0.10156919807195663、0.31126976013183594、0.3604489266872406、
-0.13295558094978333、0.2473849356174469、0.278846800327301、-0.28618067502975464、0.00527254119515419]创建行业表
为了存储词向量,我们需要使用以下 SQL 命令向 Postgres 数据库添加一个 industries 表:
创建表 salesforce.industries
(
name varchar not null 约束 Industries_pk 主键,
嵌入向量(100)不为空
);创建industries表后,我们将插入每个生成的词向量。我们使用类似于以下的 SQL 语句来执行此操作:
插入 salesforce.industries
(名称、嵌入)
价值观
('软件','[-0.40402618050575256, 0.5711150765419006, -0.7885153293609619, -0.15960034728050232, -0.5692323446273804, 0.00537745840 8474922, -0.1315757781267166, -0.16840921342372894, 0.6626015305519104, -0.26056772470474243, 0.3681095242500305, -0.453583300113 678, 0.004738557618111372, -0.4111144244670868, -0.1817493587732315, -0.9268549680709839, 0.07973367720842361, -0.17835664749145508, -0.2949991524219513, -0.5533796548843384, 0.04348105192184448, -0.028855713084340096 , -0.13867013156414032, -0.6649054884910583, 0.03129105269908905, -0.24817068874835968, 0.05968991294503212, -0.24743635952472687 , 0.20582349598407745, 0.6240783929824829, 0.3214546740055084, -0.14210252463817596, 0.3178422152996063, 0.7693028450012207, 0 .2426985204219818,-0.6515568494796753, -0.2868216037750244、0.3189859390258789、0.5168254971504211、0.11008890718221664、0.3537853956222534、-0.713259220123291、-0.4 132286608219147, -0.026366405189037323, 0.003034653142094612, -0.5275223851203918, -0.018167126923799515, 0.23878540098667145, -0 .6077089905738831, 0.5368344187736511, -0.1210874393582344, 0.26415619254112244, -0.3066694438457489, 0.1471938043832779, 0.049 54215884208679, 0.2045321762561798, 0.1391817331314087 , 0.5286830067634583, 0.5764685273170471, 0.1882934868335724, -0.30167853832244873, -0.2122340053319931, -0.45651525259017944, -0.016777794808149338, 0.45624101161956787, -0.0438646525144577, -0.992512047290802, -0.3771328926086426, 0.04916151612997055, -0 .5830298066139221, -0.01255014631897211, 0.21600870788097382, -0.18419665098190308, 0.1754663586616516, -0.1499166339635849, -0.1 916201263666153 , -0.22884036600589752, 0.17280352115631104, 0.25274306535720825, 0.3511175513267517, -0.20270302891731262, -0.638346850872039 8, 0.43260180950164795, -0.21136239171028137, -0.05920517444610596, 0.7145522832870483, 0.7626600861549377, -0.5473887920379639, 0.4523043632507324, -0.1723199188709259, -0.10209759324789047, -0.5577948093414307, -0.10156919807195663, 0.31126976013183594, 0 .3604489266872406,- 0.13295558094978333、0.2473849356174469、0.278846800327301、-0.28618067502975464、0.00527254119515419]
');请注意 – 虽然我们使用小写代表软件行业(软件)创建了词向量,但 industries.name 列需要与大写行业相匹配名称(软件)。
将所有生成的词向量添加到 industries 表后,我们就可以将重点转向引入 RESTful API。
引入 Spring Boot 服务
此时,我作为一名软件工程师的热情开始高涨,因为我已经做好了一切准备来解决眼前的挑战。
接下来,使用 Spring Boot 3.2.2 和 Java (temurin) 17,我在 IntelliJ IDEA 中创建了 similarity-search-sfdc 项目,并具有以下 Maven 依赖项:
我为 Account 对象和 Industry(嵌入)对象创建了简化的实体,这些实体与之前创建的 Postgres 数据库表对齐。
@AllArgsConstructor
@NoArgs构造函数
@数据
@实体
@Table(名称=“帐户”,模式=“销售人员”)
公开课账户{
@ID
@Column(名称=“sfid”)
私有字符串 ID;
私有字符串名称;
私营弦产业;
}
@AllArgsConstructor
@NoArgs构造函数
@数据
@实体
@Table(名称=“行业”,模式=“销售人员”)
公开课行业{
@ID
私有字符串名称;
}使用 JpaRepository 接口,我添加了以下扩展以允许轻松访问 Postgres 表:
来自 salesforce.industries
WHERE 名称 = ‘软件’)
限制 3)
按名称排序;” data-lang=”text/x-sql”>
SELECT sfid、名称、行业
来自 salesforce.account
哪里的行业
输入(选择名称
来自 salesforce.industries
WHERE 名称 != '软件'
按嵌入排序
<->(选择嵌入
来自 salesforce.industries
WHERE 名称 = '软件')
限制 3)
按名称排序;从那里,我构建了 AccountsService 类来与 JPA 存储库交互:
最后,我让 AccountsController 类提供 RESTful 入口点并连接到 AccountsService:
curl --location 'https://HEROKU-APP-ROOT-URL/accounts/similarities?industry=Software&limit=3'RESTful API 返回 200 OK HTTP 响应状态以及以下负载:
[
{
“id”:“001Kd00001bsP80IAE”,
"name": "CleanSlate 科技集团",
“行业”:“技术”
},
{
“id”:“001Kd00001bsPBFIA2”,
“名称”:“CMG 全球”,
“行业”:“媒体”
},
{
“id”:“001Kd00001bsP8AIAU”,
"name": "开发者聚光灯",
“行业”:“技术”
},
{
“id”:“001Kd00001bsP8hIAE”,
"name": "蛋头",
“行业”:“电子”
},
{
“id”:“001Kd00001bsP85IAE”,
“名称”:“Marqeta”,
“行业”:“技术”
}
]因此,技术、媒体和电子行业是与最接近的行业本例中的软件行业。
现在,营销部门有了一份可以联系以开展下一次营销活动的帐户列表。
结论
几年前,我花在玩军团要塞 2多人视频游戏上的时间比我愿意承认的还要多。这是 2012 年一次非常有趣的活动的屏幕截图:

那些熟悉我生活这方面的人可能会告诉你,我默认选择的玩家职业是士兵。这是因为士兵的生命值、移动力、速度和火力具有最佳的平衡。
我觉得软件工程师就是现实世界中的“士兵阶层”,因为我们可以适应任何情况,专注于高效地提供满足期望的解决方案。
几年来,我一直专注于以下使命宣言,我认为它可以适用于任何 IT 专业人员:
<块引用>
“将时间集中在提供可扩展知识产权价值的特性/功能上。利用框架、产品和服务来完成其他一切。”
– J.维斯特
在本文的示例中,我们能够利用 Heroku Connect 将企业数据与 Postgres 数据库同步。安装 pgvector 扩展后,我们从这些 Salesforce 帐户中为每个独特的行业创建了词向量。最后,我们引入了 Spring Boot 服务,该服务简化了查找行业与另一个行业最接近的 Salesforce 帐户的过程。
我们利用现有的开源技术、添加的小型 Spring Boot 服务和 Heroku PaaS 快速解决了这个用例 – 完全遵循我的使命宣言。我无法想象如果没有这些框架、产品和服务,需要多少时间。
如果您有兴趣,可以在 GitLab。
祝你有美好的一天!