

如果已部署 IoT 解决方案,则必须决定在何处以及如何存储所有数据。至少从我的角度来看,存储传感器数据的最佳和最简单的地方,当然是InfluxDB。
我说这不能令你吃惊。您需要存储的其他数据呢?关于传感器的数据?诸如传感器制造商、投入使用日期、客户 ID、运行平台类型等。你知道,所有的传感器元数据。
您可能还喜欢:
旧通量,新通量
当然,一个解决方案是简单地将所有内容作为标签添加到 InfluxDB 中的传感器数据中,然后继续您的一天。是否要将所有传感器数据与每个数据点一起存储?当时很多事情似乎是个好主意,但当现实袭来时,事情很快就变成了一个可怕的想法。
由于大多数元数据不会经常更改,并且可能与客户信息相关联,因此在传统的 RDBMS 中,它的最佳位置很可能。很可能您已经有了一个包含客户数据的 RDBMS,那么为什么不继续利用该投资呢?
正如我反复说过的,这不是传感器数据的最佳位置。现在,您可以在两个不同的数据库中获得 IoT 数据。如何访问它,并将其合并到一个位置,在那里您可以看到它的所有?
通量是答案
告诉我你看到了你必须看到这一点。好吧,公平地说,你可能有,因为,毕竟,你将如何获得你的基于SQL的数据通过Flux?这就是Flux的美:它是可扩展的!
我们现在有一个扩展,允许您通过 Flux 从 MySQL、MariaDB 或 Postgres 读取数据。当我听说这个SQL连接器已经准备就绪时,我不得不尝试一下。我会告诉你我建的是什么,以及如何。
建立客户数据库
要做的第一件事是建立一个MySQL数据库与一些客户信息。我创建了一个新数据库, IoTMeta 调用该数据库,其中放置了一个带有一些传感器元数据的表。我还添加了另一个表,其中包含有关这些传感器的客户信息。

非常基本的表。Sensor_ID我填充的字段与 Sensor_id InfluxDB 实例中的标记对应的数据。我敢打赌,你看看我该去哪里了。我添加了一堆数据。


使用通量查询数据
首先,我在 Flux 中构建了一个查询来获取我的一些传感器数据,但我对传感器数据本身不感兴趣。我在寻找和识别标记值: Sensor_id 。这个查询看起来有点奇怪,但最后会有意义,我保证。
temperature = from(bucket: "telegraf") |> range(start: v.timeRangeStart,
stop: v.timeRangeStop) |> filter(fn: (r) => r._measurement == "temperature"
and (r._field == "temp_c")) |> last() |> map(fn: (r) => { return
{ query: r.Sensor_id } }) |> tableFind(fn: (key) => true) |> getRecord(idx: 0)它返回一个一行的表,然后拉出 Sensor_id 标签,在那里你可能会说”哇?请记住:Flux 返回表中的所有内容。我需要的基本上是该表中的标量值。在这种情况下,它是相关标记的字符串值。你就是怎么做的
接下来,我将获取 MySQL 数据库的用户名和密码,该数据库可以很方便地存储在 InfluxDB 机密存储中。
uname = secrets.get(key: "SQL_USER") pass = secrets.get(key: "SQL_PASSW")等等,我是如何将这些值放入此机密存储的?好,我们回来一分钟。
curl -XPATCH http://localhost:9999/api/v2/orgs/<org-id>/secrets -H
//'Authorization: Token <token>' -H 'Content-type: application/json'
//--data '{ "SQL_USER": "<username>" }'需要注意的一点是,您将它们从 <org-id> URL 中获取。它不是 InfluxDB 中组织的实际名称。 然后你为 SQL_PASSW 这个秘密做同样的事情。你可以叫他们任何你想要的。现在,您不必在查询中以纯文本形式输入用户名/密码。
接下来,我将使用所有这些来构建 SQL 查询:
sq = sql.from( driverName: "mysql", dataSourceName:
"${uname}:${pass}@tcp(localhost:3306)/IoTMeta",
query: "SELECT * FROM Sensor_data, Customer_Data WHERE
"Sensor_data.Sensor_ID = ${"\""+temperature.query+"\"
"AND Sensor_data.measurement = \"temperature\"
"AND Sensor_data.CustomerID = Customer_Data.Customer_ID"}"
//"SELECT * FROM Sensor_data WHERE Sensor_ID = ${"\""+temperature.query+"\"
//AND measurement = \"temperature\""}" //q // humidity.query //"SELECT *
//FROM Sensor_Data WHERE Sensor_ID = \"THPL001\""// humidity.query )您将看到我在 SQL 查询中使用第一个 Flux 查询中的值。酷!您可能还注意到,我正在执行 join 该 SQL 查询,以便可以从数据库中的两个表获取数据。这有多酷?接下来,我将格式化生成的表,以便只显示要显示的列:
fin = sq |> map(fn: (r) => ({Sensor_id: r.Sensor_ID,
Owner: r._Sensor_owner, Manufacturer: r.Sensor_mfg,
MCU_Class: r.MCU_class, MCU_Vendor: r.MCU_vendor,
我现在有一个表,其中包含有关我的传感器的所有元数据,以及有关该传感器的所有客户联系人数据influxdata.com/wp-content/uploads/Screen-Shot-2019-11-14-at-12.12.19-PM.png”rel=”不跟随”]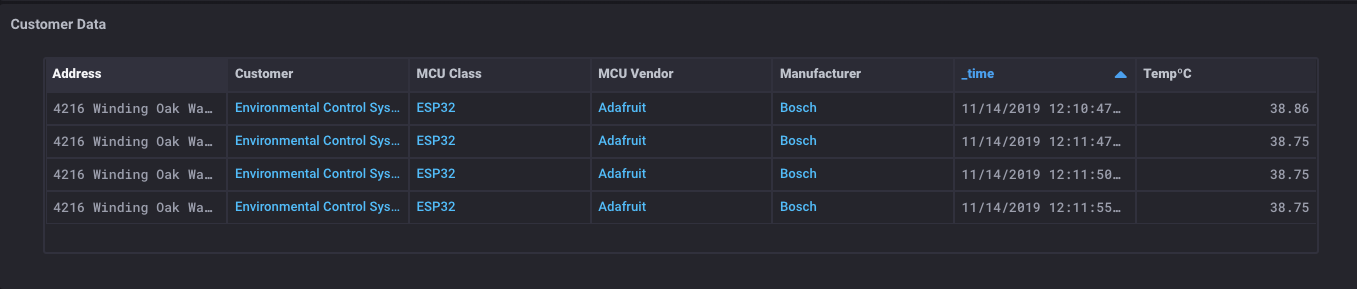
这个巫术是什么?我有一个表,包含有关传感器的所有元数据、一些客户数据和传感器读数?是的。我愿意。这里是真正的神奇之处:由于可以从SQL数据库和 InfluxDB存储桶中获取数据,因此还可以将数据一起联接到单个表中。
以下是我这样做的方式:
temp = from(bucket: "telegraf") |> range(start: v.timeRangeStart,
stop: v.timeRangeStop) |> filter(fn: (r) =>
r._measurement == "temperature" and (r._field == "temp_c"))给我一个传感器数据的表。我已经有一个来自 SQL 的元数据表。
j1 = join(tables: {temp: temp, fin: fin}, on: ["Sensor_id"] )
|> map(fn: (r) => ({_value: r._value, _time: r._time,
Owner: r.Owner, Manufacturer: r.Manufacturer, MCU_Class: r.MCU_Class,
MCU_Vendor: r.MCU_Vendor, Customer: r.Customer, Address: r.Address,
Phone: r.phone})) |> yield()我只是在一个公共元素(字段)上加入这两个表 Sensor_id ,我有一个表,它的所有内容都放在一个位置!
有几种方法可以使用此功能来合并来自不同源的数据。我很想听听您如何实施这样的功能,以便更好地了解您的传感器部署。
我已经使用 InfluxDB 2.0 的 Alpha18 版本完成了所有这些工作,这是我运行的 — 我从 中自定义构建我的版本, master 因为我对 Flux 有一些新增功能,但这就是另一个帖子。对于这些东西,OSS InfluxDB 2.0 的 Alpha 构建工作正常。你应该试试看!

/filters:no_upscale()/news/2026/02/mysql-foreign-keys/en/resources/1innodb-vs-sql-engine-foreign-key-cascade-1024x510-1770991931623.jpg "MySQL 9.6:对外键约束及级联操作的修改")