
啊, Lambda 体系结构。所以数据的速度越来越快, 实时流化?伟大!哦, 你的数据库不能接受连续的插入流, 同时也响应从用户在高规模的选择?看 Lambda 体系结构:
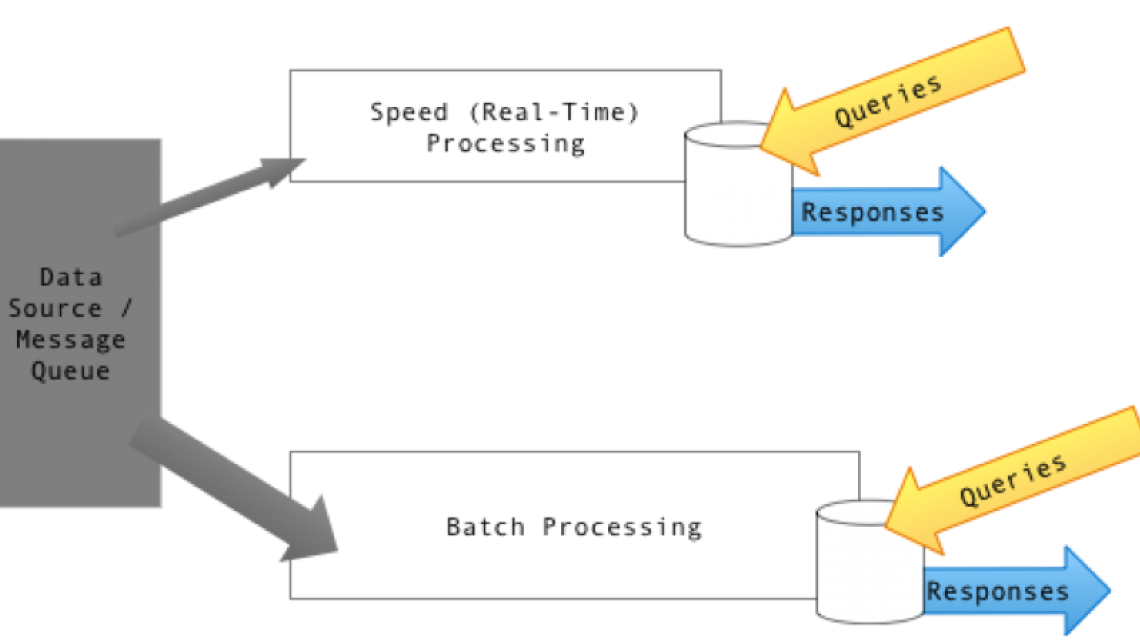
通过 Textractor 自己的工作, CC BY SA 4.0, https://commons.wikimedia.org/w/index.php?curid=34963985
基本上, 这个想法是保持快速的东西快, 慢的东西慢。14年前, 我写了一篇论文, 讨论实时数据仓储的挑战。幸运的是, 数据流、数据库和 BI 层自那时以来都有很大的发展, 现在有了数据库和其他数据存储引擎, 它们可以支持三位一体的功能, 这需要进行实时和历史分析对, 没有 Lambda 体系结构:
- 以高速率接受实时数据流。
- 同时响应大量查询, 包括最近添加的数据。
- 存储分析所需的所有历史记录。
我们称这些引擎为 “快速数据接收器”, 今天有四主要组:
- 内存中或 GPU 数据库: 诸如 SAP Hana、MemSQL 和 Kinetica 等数据库。
- 搜索引擎: Elasticsearch 和 Solr。
- 前沿 hadoop: Kudu, 在 Cloudera Hadoop 堆栈上运行的存储引擎。
- 一些云数据库: 谷歌 BigQuery, 雪花。
有些人尝试使用键值存储和文档数据存储, 如 MongoDB 和 HBase 的这种类型的用例, 它的工作在较低的规模, 但一旦数据和查询卷增加, 他们往往会变得太慢, 是有用的。
Zoomdata 与快速数据接收器一起运行, 以便在近乎实时的数据上实现交互性和可视化。流数据可以直接发送到快速数据接收器或 Zoomdata, 这会立即将其放入快速数据接收器中。
当用户实时可视化数据时, Zoomdata 会直接在快速数据接收器上运行大量的微小查询, 从而有效地 “跟踪” 数据。但这些查询通常包括少量的微聚合, 因此原始数据不需要通过 Zoomdata 引擎。这使我们能够利用快速数据接收器的强大功能, 而不是多次处理数据或将其存储在多个位置。
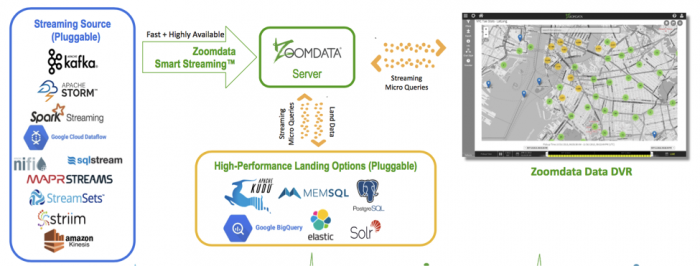
另一方面, Lambda 体系结构使实时数据与历史数据分离。这是唯一需要的, 如果他们不能保持在一起, 没有其他好处从分离 “现在” 从历史。理论认为, 一些分析需要在新数据上进行, 而其他可能更复杂的分析不需要最新的数据。 然而, 实际上, 您几乎总是想要最新鲜的数据, 即使您不分析最近几秒钟或几分钟内发生的情况, 您也一定希望您的分析包括最近更新或更正的任何历史数据
但是, 这种类型的工具级合并并没有发生, 即使是这样, 也不支持需要来自两个层的原始数据的某些类型的分析, 如不同的计数或直方图/分组类型操作。
所以网络是, 今天一些最新的数据库和数据系统能够满足上面列出的三个要求是一个快速的数据接收器。而且他们越来越便宜, 足以采购和部署, 他们可以被用来也拥有许多历史。因此, 实际上不再有理由考虑 Lambda 体系结构来处理实时数据。只要该平台可以充当快速数据接收器, 就可以在一个平台中完成此操作。

