

亚马逊红移是 (大部分) 数据仓库作为一种服务, 没有必要提供硬件, 安装数据库或补丁, 只有很少的选项来调整系统。虽然很少有可用于优化或自定义数据库的选项, 但正确设计物理表布局以最大化性能是绝对关键的。
系统体系结构
在深入研究细节之前, 我们应该概述一下红移是如何内部架构的。下图说明了如何将每个查询提交给负责分析查询、确定最佳执行计划以及协调和聚合结果的领导节点。

在加载数据时, 它将在群集中的每个计算节点上分布为一系列切片, 其中每个切片对应于 CPU 核心、内存分配和磁盘空间。此方法最大化并行执行, 并支持可伸缩性, 因为系统可以迁移到具有附加节点的较大群集。
执行查询时,引线节点将任务分解为多个并行步骤, 由实际存储数据的计算节点执行, 并执行重举。这意味着任何给定的查询都可以在多个内核并行执行, 以读取多个磁盘, 从而最大限度地提高吞吐量。
当然, 查询切片可以并行运行的程度取决于工作负载的平衡程度, 本文的其余部分将解释如何使用排序键和分发键来实现这一点. .
排序键和索引
自从拜耳和 McCreight在1972年首次提出了 B 树指数以来, 它一直是几乎每个数据库使用的主要索引方法, 尽管数据库设计者必须仔细权衡更好的读取性能和写入吞吐量的权衡。.
虽然 B 树支持直接查找和扫描操作的快速访问, 但在大容量加载数据时锁定争用问题的主要原因可能导致性能问题。即使是专门为分析查询性能设计的位图索引, 也会在多个编写器维护时导致严重的并发问题, 并且通常在大容量加载操作之前被禁用。
的解决方案
在红移方面, 不需要设计索引策略, 也不必在批处理 ETL 负载周围删除和重建索引, 因为红移不支持传统索引。而是物理地存储数据, 以便使用排序密钥最大化查询性能。
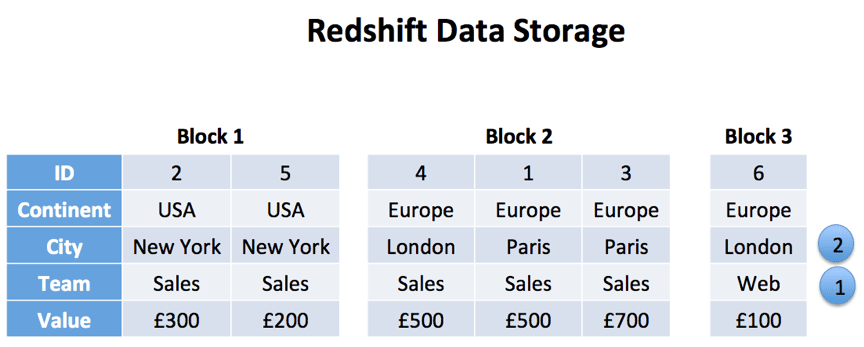
上面的图说明了红移所使用的方法, 它是在负载过程中对数据进行排序以最大化读取性能, 在这种情况下由团队, 然后是城市。
在加载数据时, 它按排序键排序, 并且记录每个1Mb 块的最小和最大值。优化器使用此方法在基于查询 where 子句的基础上跳过块。例如, 在上面的表中, 按团队的查询筛选 = ‘ Web ‘ 只读取块 3, 因为所有其他的都被自动删除
如果没有排序密钥, 同一查询可能会读取整个表中的每个块 (可能有上百万行), 从而对性能产生影响。
在某些数据库系统中 (例如,Oracle) 这是通过在表上声明一个分区和子分区来实现的, 其效果是相同的-通过分区消除来改进查询性能。
为了证明潜在的收益, 我们在 8 dc2 的集群上运行了一个简单的基准摘要查询, 在10亿行上进行了一个小的节点, 简单地添加排序键 (不带任何筛选器) 意味着按查询分组的计数运行速度两次。包括在查询where子句中的筛选器, 生成了子第二个结果。

排序关键字可提高性能:
- 通过使用查询where子句在筛选数据时跳过块来减少磁盘 i/o。
- 通过减少按操作按顺序或按组对数据进行物理排序的需要。
- 通过促进合并联接-红移所支持的三连接方法中最快的一个。
排序关键字的类型
当前有两种类型的排序键:
- 复合材料:可以包含多个列的默认值, 并且必须以优先级顺序定义, 并且最常从第一个开始查询的列。
- 交错:对每个排序列都具有相同的优先级。最适合用于不经常更新的大型表, 而不频繁地筛选单个列。
默认情况下, 复合键可能会提供更好的查询性能, 但一定要正确排列列以最大限度地消除行。
交错键应考虑为相对静态的大表, 其中单列显示为高度选择性谓词, 但不经常使用单个列来筛选结果。对于时间序列的事实表, 应该避免它们, 因为它们可能导致过度的真空工作。
需要真空
由于红移不会自动回收可用空间, 更新和删除操作通常会导致表增长。同样, 随着新条目的添加, 数据以排序的顺序保持, 这一点很重要。
“真空” 命令用于重新序列化数据, 并由于删除和更新操作而回收磁盘空间。虽然它不会阻止其他进程, 但它可以是资源密集型操作, 特别是对于使用交错排序键存储的数据。
它应该定期运行, 以确保性能一致并减少磁盘使用量。
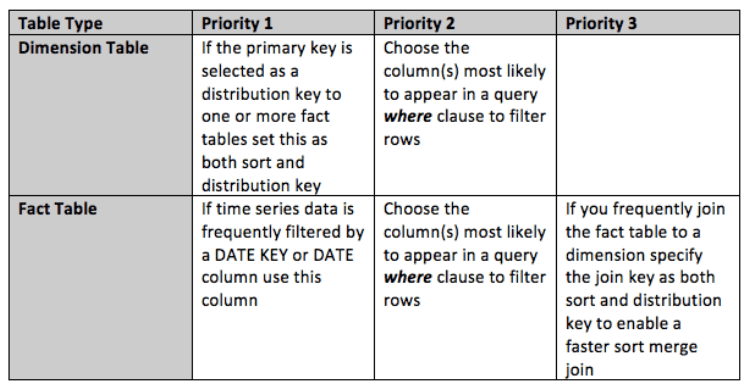
最佳实践
排序关键字的选择应基于对数据的了解, 以及值在查询where子句中如何显示为谓词。
- 所有表格:应该定义一个排序键。
- 使用复合键:基于对如何在查询中筛选数据的理解。如果您不理解数据查询模式, 则不要假定交错键工作得更好。
- 选择:最常用于 “where”、”分组 by” 和 “order by” 子句的列。
- 大型事实数据表:通常由日期或时间戳查询的表应定义为一个复合排序关键字, 以最大限度地消除数据。
- 分发密钥:作为分发键选择的列也是排序关键字的候选项。这改进了大事实和维度表之间的联接性能, 因为两个表都按相同的顺序排序, 并且联接成为简单的排序合并操作
如果使用复合排序密钥, 请确保第一列最常出现在 where 子句中以实现最大性能。
总而言之, 选择排序关键字的最佳做法包括:
分发密钥: 挑战
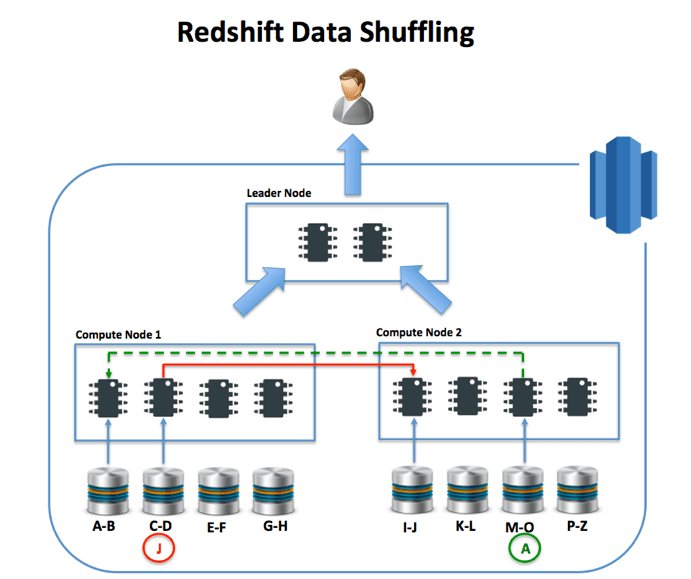
下图说明了在群集中的节点之间自动分布数据并在每个节点上并行执行查询的挑战。这很好地发挥了最大的性能, 除了表加入。如果相关数据保存在不同的节点上, 则会导致节点间数据传输, 从而显著影响性能。
在下面的示例中, 数据分布很差, 因此需要在节点之间传输以完成联接操作。
解决方案: 分发密钥
任何给定的表只能有一个分发密钥, 并且它确定数据在群集中的每个节点上的物理位置。选择合理的分发密钥的目的是平衡一些 (有时是冲突的) 优先级:
- 消除数据传输:联接在不同节点上的数据会导致数据在网络上被复制, 从而显著影响性能。
- 磁盘空间减少:为了避免数据传输, 可以在群集中的所有节点上复制数据, 但这会增加磁盘空间要求, 而且数据加载需要更长的时间, 因此必须将其复制到每台计算机上。此方法以牺牲磁盘空间和负载速率来提高查询性能。
- 确保工作负载平衡:一个选项是使用按键分配, 因为具有相同键的所有行都位于同一台计算机上。但是, 如果选择不当, 可能导致工作负载不平衡, 因为数据是倾斜的, 或者大多数查询都是在一台计算机上执行的。
有三个分发密钥选项, 如下图所示:
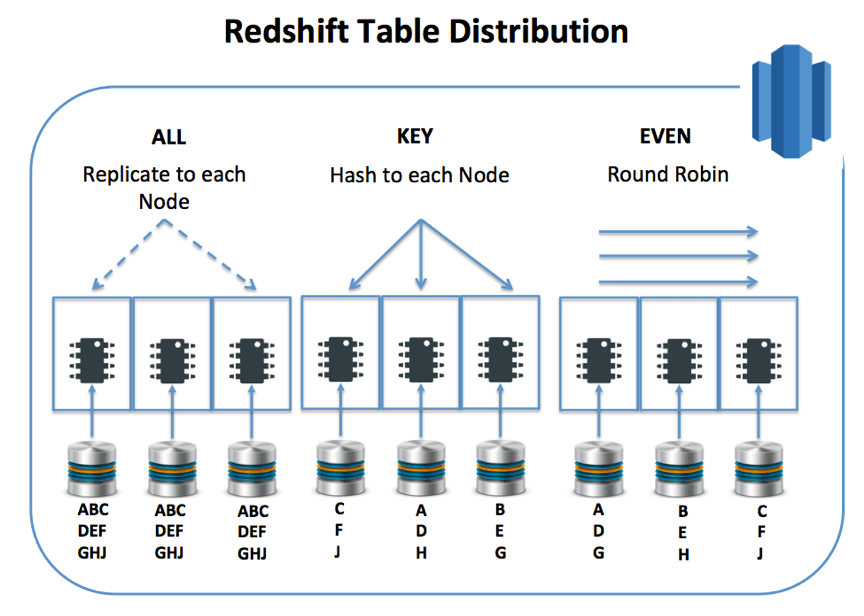
- 全部:在群集中的每个节点上复制数据。最好应用于相对较小的维度表, 这将使用更多的磁盘空间, 但确保每个连接操作在本地快速执行, 避免数据传输。它还增加了执行红移复制命令所需的时间, 最终可能需要更大的群集。将表复制到所有节点也会影响加载时间, 因为需要将任何更新写入群集中的所有节点。
- 键:将数据分布在节点上, 并确保每个具有相同键的行位于同一节点上。这意味着, 例如, 如果按状态分布, 仅限于少数状态的查询将在节点的子集上执行。但是, 对于非常大的状态, 有一个或多个节点超载的风险。一个潜在更好的用例是将大型销售事实数据表加入到同样大的客户维度表中。在这种情况下, 每个客户的销售额都物理地存储在同一节点上, 并且假设一个相对均匀的分布, 查询将在群集中的所有节点上执行。
- 甚至:以循环方式均匀分布行。这对桌子很管用 (例如。审核日志) 由于查询是在群集中的所有节点并行执行的, 因此很少与其他成员联接。
推荐: 极端护理设计

必须注意就数据分发战略达成协议, 如下所示:
- 小尺寸表:应在群集中的所有节点上复制。复制在联接操作中出现的维度表是减少节点间数据传输的一个很好的方法, 其代价是磁盘空间和负载率。
- 事实数据表:那些纯连接到具有分布类型的维度表的那些应该使用偶数方法进行分发。这确保了均衡分布, 以支持快速插入和查询, 同时避免数据传输。
- 大尺寸表:密钥分发的候选项, 但必须与事实数据表一起仔细选择联接键, 因为每个表只能有一个分发键。例如, 一个大型客户表可以通过 CUSTOMER_ID 和销售表一起分发, 而必须使用相同的密钥分发。这可确保同一客户的销售数据位于同一台计算机上。假设所有其他维度都使用所有方法进行分发, 这将确保所有联接都在本地执行。
- 与关键维度联接的事实数据表:必须与相应的维度表具有相同的键分布。
如果大型事实数据表连接到多个非常大的维度表, 则设计器必须确定平衡冲突需求的最佳方法。选择了密钥维度后, 剩余的维度必须根据磁盘空间、数据加载速率和查询性能的平衡来分配。
谢谢
谢谢你读了这么远。 如果您发现此帮助, 您可以在我的网站 www.Analytics.Today 上查看有关大数据、云计算、数据库体系结构和数据仓库的未来的更多文章 。