
这是我职业生涯中最具挑战性和最有趣的时期之一, 因为在分析和数据仓库行业工作的时机从来没有这么好过。
这篇文章将提出一个愿望清单。一套理想的数据仓库分析平台的要求, 并揭示了一个新的和高度创新的解决方案如何提供一个独特的架构, 以满足我理想愿望列表中的每个要求。
我们在努力解决什么问题?
当被召集到设计评审会议时, 我最喜欢的一句话 “我们想解决什么问题”不可避免的是, 当你在会议室里得到一个经验丰富的解决方案架构师团队时, 他们会立即开始提出解决方案, 并经常在最佳方法上意见不一。这有点像你在一个房间里有三个经济学家, 得到四个意见。
在数据仓库中, 我们真正想解决的问题是什么?以下是我对潜在的需求愿望清单的想法。
所需资源
- 工作负载分离:解决方案架构师今天面临的最大挑战之一是为许多相互竞争的用户组保持计算资源的平衡。最明显的是需要提取、转换、清理和聚合数据的 eltx-etl 加载过程, 以及希望分析结果以提取价值的最终用户。谁应该得到优先考虑?下图说明了这两个竞争组的巨大不同工作负载。elt 处理的过程可能具有多个并行进程, 从而导致100% 的 cpu 使用率, 并且分析人员的工作负载要不规则得多。此要求是分离这些工作负载, 并消除用户组之间的争用。

- 最大限度地提高数据加载吞吐量:如上所述, 我们需要快速提取、加载和转换数据, 这意味着我们需要最大限度地提高吞吐量-完成的工作总量, 而不是任何单个查询的性能。为了实现这一目标, 我们通常需要运行多个并行负载流, cpu 使用率接近 100%, 这在需要平衡这些需求和需要高水平的最终用户并发性的同时也具有挑战性。
- 最大化并发性:一个典型的分析平台有许多忙碌的用户, 他们只想完成自己的工作。他们希望尽快取得自己的成果, 但他们经常与其他人一起争夺机器资源。总之, 我们需要最大限度地提高并发性。同时处理来自多个用户的大量查询的能力。几乎每个数据仓库, 无论是内部部署还是基于云的数据仓库, 都是建立在一个单一的原则之上的: 最大工作量的大小和对最佳的希望。虽然像 google bigquery 和 amazon redshift 这样的解决方案提供了一定的灵活性, 但它们和每个内部部署平台一样, 最终会受到平台大小的限制。对大多数用户来说, 现实是查询性能往往很差, 在月或年底, 及时交付结果变得很困难。在理想的环境中, 数据仓库将自动横向扩展, 以便根据需要动态添加其他计算资源。硬件资源将只是增长 (和收缩), 以满足需求, 用户将被计费的实际计算时间, 他们使用-不是单一的投资每五年与卓越的性能承诺-在一段时间内。
- 最大限度地降低延迟–最大速度:c-suite 高管和前台交易员希望在他们的仪表板上获得次秒的响应时间。他们不关心 etl 吞吐量或批处理报告性能-他们希望仪表板查询的延迟极低
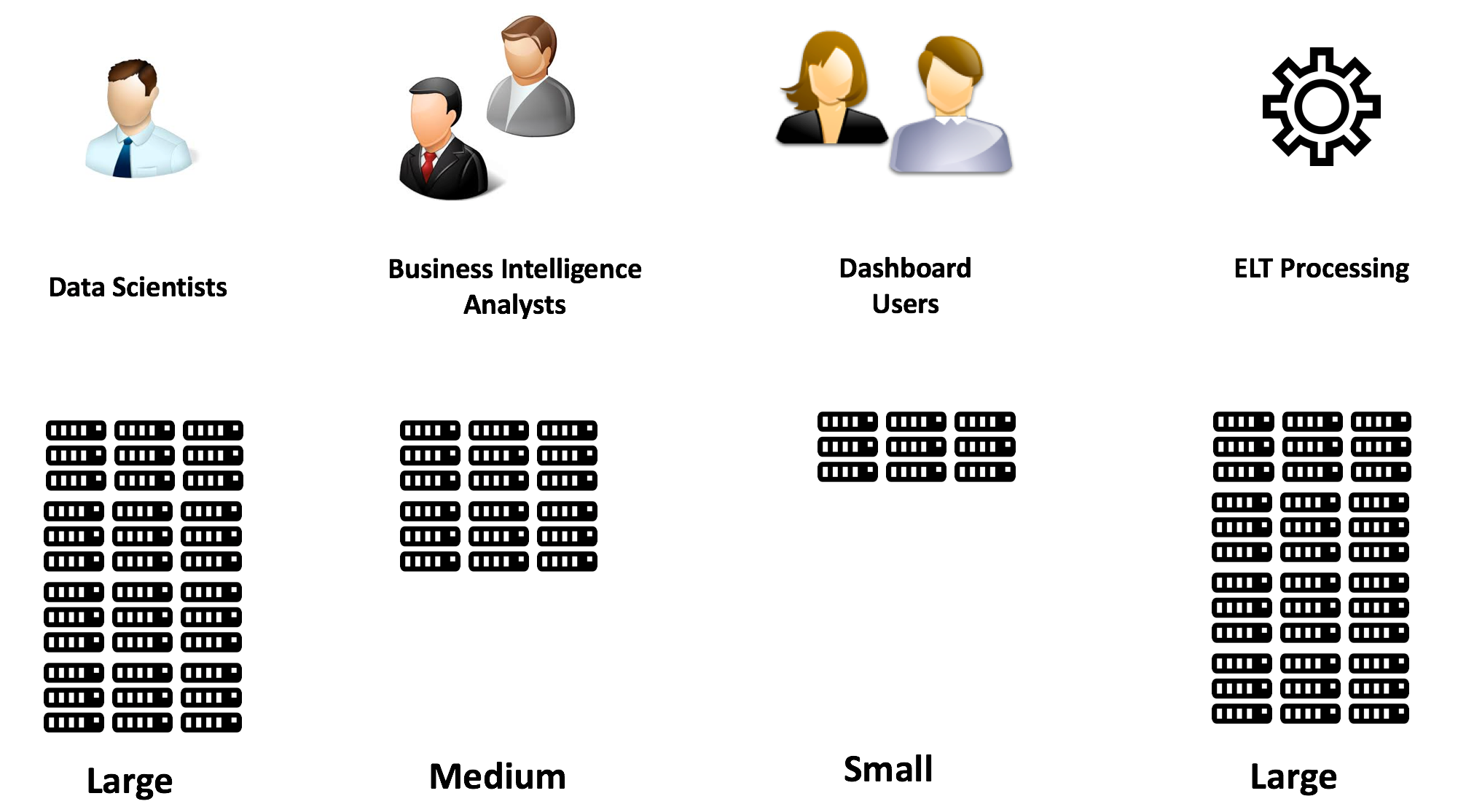
传统上, 保证部门用户组性能的唯一方法是投资和维护自己的硬件, 但将其称为数据集市, 以隐藏它实际上是另一个数据筒仓的事实。这导致不一致, 因为数据是从多个来源汇总和报告的, 没有两份报告与结果一致每个用户组都有自己独立大小的计算机, 每个用户组都可以适当调整大小。
当然, 每个数据集市 (数据仓) 理论上都可以独立调整大小, 但理想情况下, 我们希望所有用户都能访问所有数据。为什么要提取、转换数据并将其复制到其他位置?每个部门都应该能够透明地访问整个企业的所有数据 (受授权), 但每个部门都可以独立地完成手头的任务。
“一旦复制, 数据就会出现分歧”–数据孤岛定律。
- 低入口点:每个多 tb 的数据仓库都从一个需求、一个事实表 (也许是一个报表) 开始。如果成功, 平台会增长, 但重要的是 (特别是对中小型创业企业), 要有一个较低的切入点。数据仓库过去是大型跨国公司的领域, 但业务洞察力是任何企业, 无论大小, 都是至关重要的要求。
- 可快速扩展:系统必须具有增量可扩展性, 可能从千兆字节到千兆字节, 甚至是多个 pb。必须能够根据需要添加额外的计算和存储资源, 理想情况下不需要任何停机或计算密集型数据重组或分发。简而言之, 必须能够添加额外的计算和存储资源, 以增加并发性 (更多用户) 或处理 (更快地交付巨大的工作负载), 而不会导致停机或服务中断。
- 价格低廉:解决办法不应涉及前期资本支出或承诺, 并应以符合使用情况的成本进行廉价操作。直到最近, 构建分析平台的唯一选项还涉及到昂贵的硬件和数据库许可证的巨额资本支出。一旦分析查询需求和数据量超过多 tb 级别, 我们通常需要一个冗长而昂贵的迁移项目来迁移到更大、更昂贵的系统。这已不再是一个可行的策略, 理想的解决方案应使用灵活的现收现付模式, 并根据使用情况降低成本。
- 弹性:这与上面的廉价需求密切相关, 这意味着解决方案需要动态匹配计算资源需求。应该可以快速增加可用资源, 以匹配常规或意外的查询工作负载, 也许可以处理月底的报告或大规模的数据处理任务。同样, 在任务完成时, 应该很容易缩减处理资源, 其成本应与使用情况保持一致, 理想情况下, 整个过程对用户应该是透明的。最后, 在不需要时, 应该可以挂起计算资源来控制成本, 并可以选择在需要时在几秒钟内自动恢复处理。
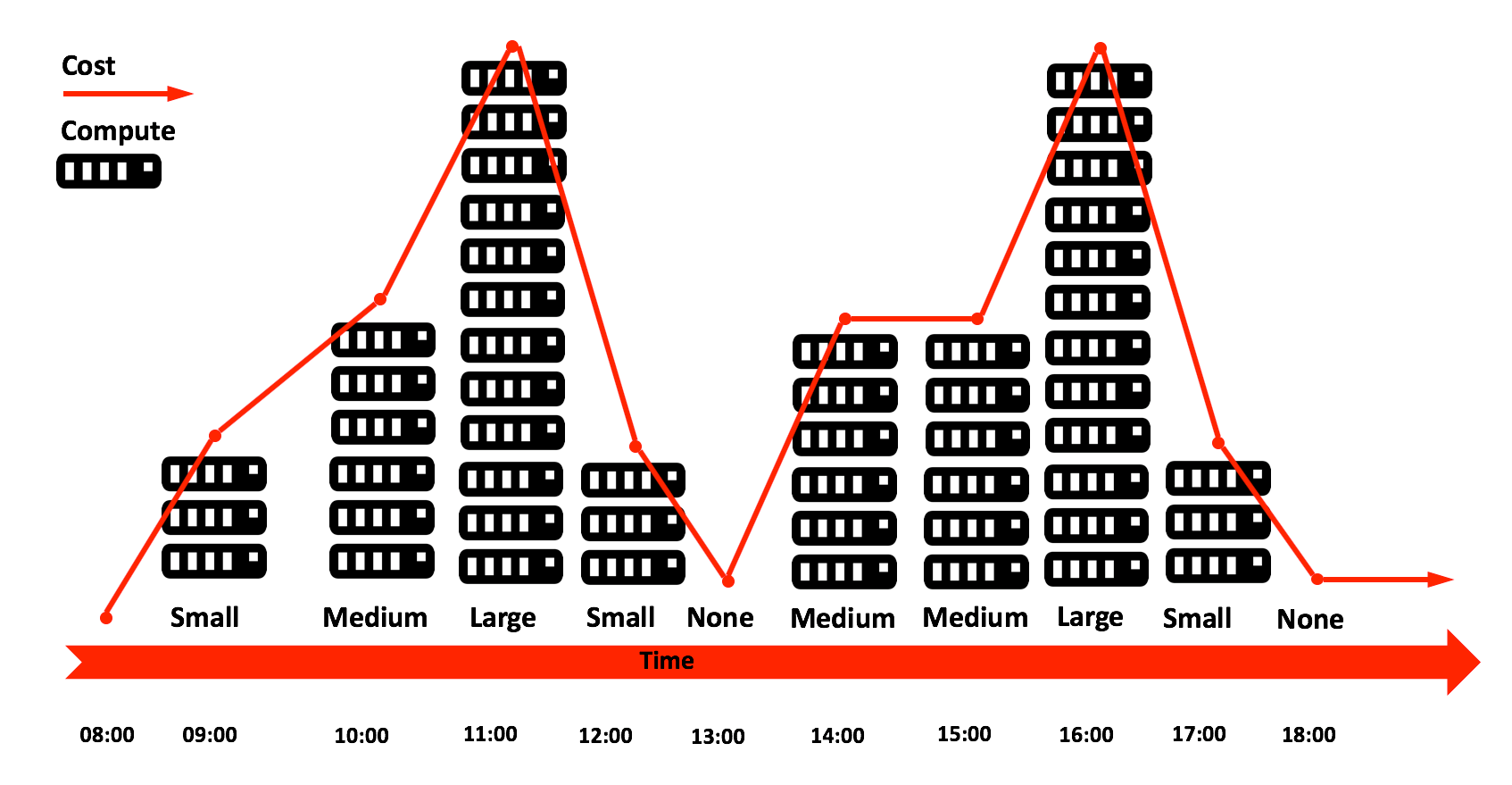
- 合并时间:许多数据仓库计划导致不同数量的独立加载的数据集市。除了出现不一致的风险外, 还有一个问题是时间交付, 因为结果未能在同一时刻一致地传递给所有的集市。在一个项目中, 用户经常抱怨两个系统的销售数字不一致, 这两个系统 (具有讽刺意味的是) 来自相同的原始数据。此要求意味着所有数据都应合并到一个数据存储中, 并可供所有用户访问。同样, 该解决方案应支持对结构化和半结构化数据的查询, 以避免关系、nosql 和 hadoop 数据存储等技术的传播。
- 低管理负担:oracle 支持14种类型的索引, 包括 b 树、位图、分区、群集和索引组织表, 并且在许多情况下禁用索引, 可能导致异常或失败
同样, 即使有 cloudera、hortonworks 或 mapr 的专业支持, 部署和维护 hadoop 集群也非常困难, gartner 估计, 大约85% 的大数据计划无法投入生产。理想的分析解决方案应该很简单, 几乎没有发生重大错误的机会。总之, 它应该只是工作。
 此要求是指与业务合作伙伴、供应商或子公司安全共享数据访问权限的能力。传统的方法包括构建昂贵的 etl 管道以提取数据并将其传递给合作伙伴, 或者提供一个预定义的分析仪表板, 该仪表板要么构建和维护成本很高, 要么 (在预构建的仪表板的情况下) 限制可用的分析选项。理想的分析平台将允许安全地访问世界上任何地方的任何授权客户端, 以运行自己的报告和分析。这样, 随着数据的变化, 不需要提取和传输数据的变化, 就只需在适当的位置进行查询即可。
此要求是指与业务合作伙伴、供应商或子公司安全共享数据访问权限的能力。传统的方法包括构建昂贵的 etl 管道以提取数据并将其传递给合作伙伴, 或者提供一个预定义的分析仪表板, 该仪表板要么构建和维护成本很高, 要么 (在预构建的仪表板的情况下) 限制可用的分析选项。理想的分析平台将允许安全地访问世界上任何地方的任何授权客户端, 以运行自己的报告和分析。这样, 随着数据的变化, 不需要提取和传输数据的变化, 就只需在适当的位置进行查询即可。“一切都应该尽可能简单, 但不应该简单。
总结
我希望很多阅读这篇文章的人对提供满足上述所有要求的解决方案是否遥不可及持高度怀疑态度, 就在几年前, 我还会同意。然而。雪花计算 (成立于 2012年) 是由一个由前甲骨文数据库专家组成的团队建立的, 他们已经实现了这一点。

在我的下一篇文章中, 我将详细解释雪花如何提供一个独特和创新的体系结构, 支持多个不同大小的工作负载, 没有任何争用。每个都可以调整到特定的问题, 甚至会随着额外用户对系统提出额外的要求而自动扩展。作为一个完全符合 acid 事务的 sql 数据库, 它非常容易维护, 几乎没有调整和配置的选项-它只是工作。
最重要的是, 它是唯一完全为云构建的数据仓库, 具有无限存储的所有优势, 几乎是无限的按需计算资源这将是巨大的破坏性。我们将运行数据库系统, 在那里我们运行一百万个节点。
“-迈克·斯托内布拉克教授 (麻省理工学院)
免责声明:我在文章中表达的观点是我自己的, 不一定能反映我的雇主 (过去或现在) 或我曾经合作过的任何客户的观点。
注意: 这篇文章最早出现在我的个人博客上。