
您如何管理企业数据以跟踪它并能够构建和操作有用的应用程序?这是所有数据管理系统都试图解决的一个关键问题,知识图、图形数据库和图形分析也不例外。知识图的不同是,它们实际上可能是管理企业领域知识的最详细和整体的方式。
对于那些已经进入知识图或本体的人来说,就像他们最初的名字一样,这是老新闻。新的是,今天越来越多的人似乎在倾听,而不是认为本体论过于复杂、不现实、学术等。在过去的几个月里,我们已经看到了所有这些技术上的一系列活动。从组织文化和采用到活动、研究和教程,一切都在这里。
您可能还喜欢:
初学者图形数据库:其他图形技术
那么,谁害怕”O”字呢?也许你需要的是本体论?摩根斯坦利的马克·霍尔这样认为。Hall 描绘了一幅非常生动的企业数据管理景观图,并解释了为什么本体论长期被忽视。相关方面:《福布斯》杂志的库尔特·卡格尔讨论了知识库。
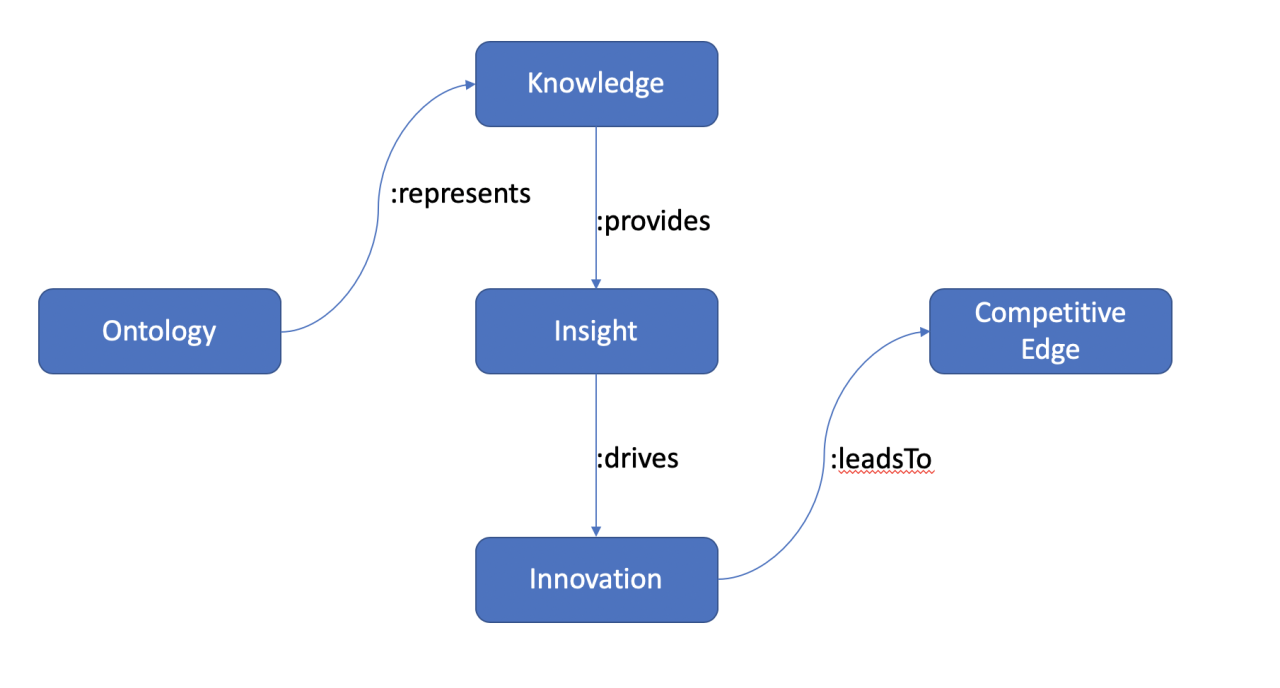
你知道你真正需要的是什么是本体论吗?
构建您自己的企业知识库,并辅以强大的表示数据模型,将为您提供自我确定的构建基块,让您深入了解您的数据,而不是看管他人的创新能力。你需要的是本体论。
一个例子:百事可乐和荷兰卡达斯特的本体图和知识图的一些用例cgiar.org/blog-post/agricultural-ontologies-in-use-new-crops-and-traits-in-the-crop-ontology/”rel=”nofollow”目标=”_blank”
农业本体在使用中:作物本体学中的新作物和特性
百事公司与NIAB的合作者合作,创立了一种新的燕麦本体。他们一直在努力将这种新的本体学纳入作物本体论,以便所有与燕麦一起工作的人有机会利用一致的命名法和标准。
对于图形数据库来说,这是一个多事的时间段。Neo4j推出了Aura,其数据库作为一种服务产品,它说,这将真正带来图形数据库的大众市场。其 GraphDB 产品的开源部分。亚马逊的海王星,微软的宇宙DB和阿兰戈DB增加了新的功能,Redis在谷歌云上首次亮相,阿帕奇里亚毕业到一个顶级项目。

大众市场图表:Neo4j 在谷歌云上推出光环
Neo4j Aura,一个完全托管的本机图形数据库即服务(DBaaS)刚刚发布。Neo4j 强调的关于 Aura 的要点是始终可用的可用性、按需可扩展性和开发人员优先方法。通过 Aura、Neo4j 和图形数据库,进入云时代。
图形数据库、知识图和 AI。这些是一些工具,为那些谁使用关系,意义和上下文的数据,以实现伟大的事情Keynotes on the Search for the Universal Data Model by Uber Research Scientist and Apache Tinkerpop co-founder Joshua Shinavier and the Biggest Knowledge Graph at work ever created by Microsoft AI Manager David Gorena, and a who is who of graph databases, analytics,AI 和知识图。如果您错过了,下面是一个简短的回顾,其中带有指向事件亮点的指针。

互联数据伦敦 2019: 共同学习和成长
顶级演讲者和赞助商,一个充满活力和敬业的社区,以及组织者谁是社区的积极部分。这就是互联数据伦敦成为它:为实践者、思想领袖和 II、知识图、图形数据库、链接数据和语义技术令人兴奋的交汇点提供共享的学习体验。
这一领域的另一个重要事件是ISWC,其中许多新的研究,后来发现它的方式进入知识图应用程序首先看到光,以及使用案例,如博世和普利特。有关更多详细信息,前往救援的行程回顾。这是一个来自数据.世界的胡安·塞奎达和一个从W3C的阿敏·哈勒。Sequeda还重点指出,提出了知识图的简要历史,以及设计和构建知识图的即用即付方法。在OlafHartig的主旨演讲中,重点是优化基于Web场景的响应时间的查询处理,这是实现数据分散网络的关键。Hartig 在 10 年前开始这一研究,并为此获得 ISWC 奖。
设计和构建知识图的即用即付方法
尽管研究和行业界提供了语义技术在现实世界中有效的证据,但我们的经验是,仍然存在一个重大挑战:包含包含数万个属性的数千个表的企业数据库的本体和映射的工程
一种新方法,通过使长格式问题回答 (QA) 系统能够更有效地搜索相关文本,从而提高其性能。此方法基于 Facebook AI 在长格式 QA 上的工作,即自然语言处理 (NLP) 研究任务,其中模型必须回答自然语言问题,例如使用前 100 个 Web 搜索结果回答”阿尔伯特·爱因斯坦以什么闻名?
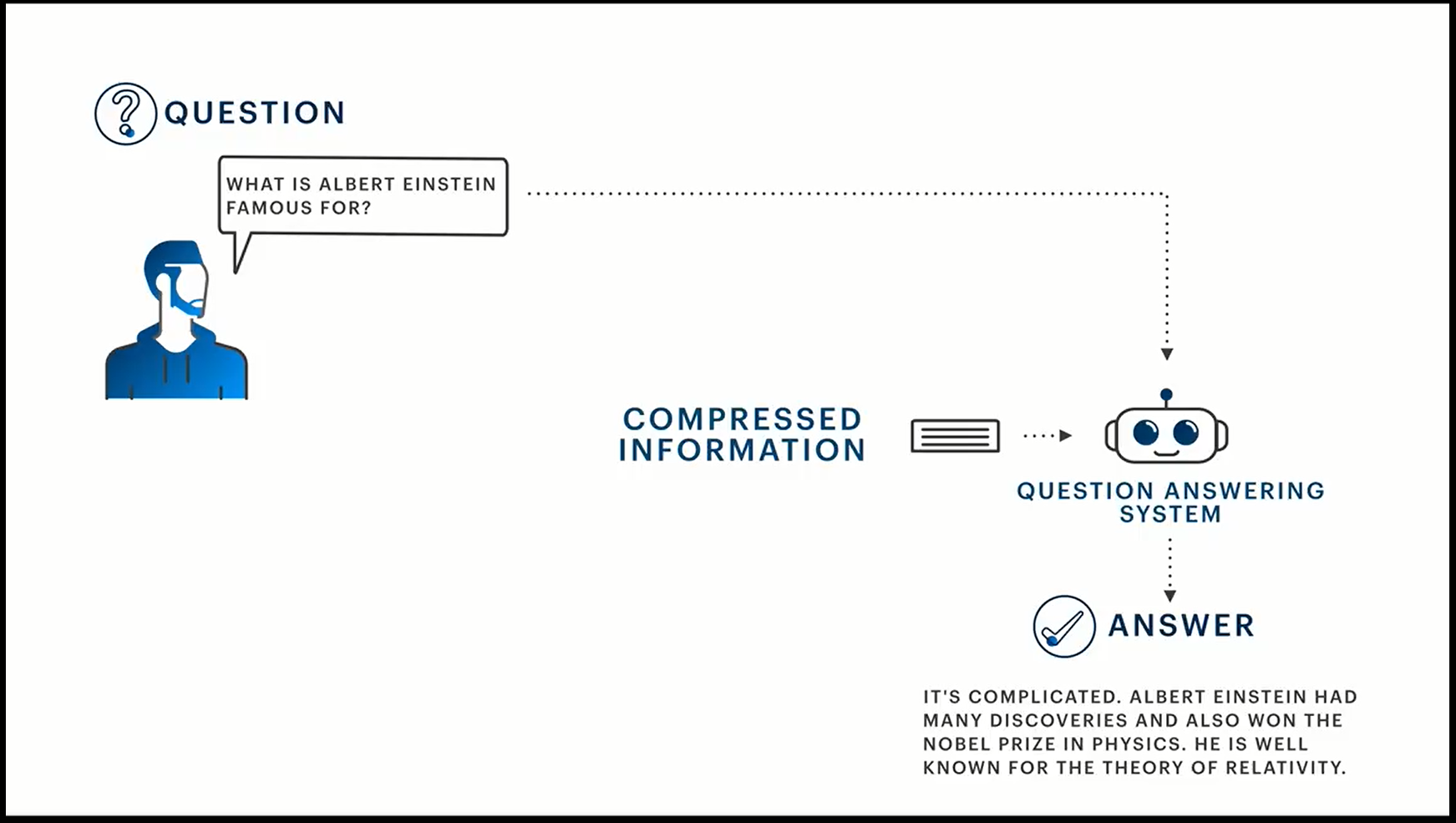
通过压缩搜索结果改进长格式问题解答
尽管答案通常存在于结果中,但序列到序列 (seq2seq) 模型很难分析如此大量的数据,这需要处理数十万字。通过将文本压缩到知识图中并引入更细粒度的注意机制,此技术允许模型使用整个 Web 搜索结果来解释相关信息。
微软也在其”点燃”活动中发表了与知识图相关的公告:项目 Cortex,一种 Office 365 的知识管理服务。这项新的知识管理服务是微软自2017年以来推出的首款主要的微软365云服务。该服务旨在帮助组织在 SharePoint 中可访问的业务内容,并主动向用户提供。

满足项目 Cortex,Office 365 知识管理服务
项目 Cortex 将创建和更新新的主题页面和知识中心,这些页面和知识中心旨在像 wiki 一样工作。Outlook、团队和 Office 中的用户可以使用主题卡。Cortex 建立在 Microsoft 图像和文本识别、表单处理和机器教学的认知服务之上。
Gartner 刚刚发布了 2019 年元数据管理解决方案魔力象限。第一次,2个依赖于语义技术和知识图的供应商位于魔力象限:data.world和语义Web公司中。这凸显了该技术在现实世界中的适用性,我们期望看到更多这种技术gartner.com/en/documents/3970385″rel=”nofollow”目标=”_blank”]
元数据管理解决方案的魔力象限
各种数据和分析计划产生的需求推动了元数据管理解决方案的战略要求。此魔力象限将帮助数据和分析领导者找到最适合其组织需求的供应商和解决方案。
到2024年,图形分析市场价值25.22亿美元,复合年增长率为34.0%。处于一个良好的位置来解决这个市场听起来是个好主意。Nvidia说,它的任务是为十亿/万亿的比例图提供多GPU图形分析。Nvidia 正在其 cuGraph 开源库方面取得进展。下面是已交付的其中 4 种算法的示例。这些算法在单个 CPU 上工作,但 Nvidia 刚刚发布了单节点多 GPU 版本的 PageRank。
RAPIDS cugraph:多 GPU 页面排名
实验结果表明,在比较 300GB 数据集上的一个 DGX-2 与 100 个 Spark 节点时,涉及新多 GPU PageRank 的端到端管道平均比 Apache Spark 快 80 倍。在 CUDA 级别,在单个节点上以每秒 380 亿边缘的速度遍历此大小的图形。
总结一些教程和示例。将JSON转换为RDF,这凸显了RDF在数据集成方面的潜力。从Rstats内部查询维基数据(或任何其他链接数据终结点),并使用Jupyter笔记本。最后但并非最不重要的,

使用 Neo4j 和 Google 云对 Twitter 数据进行情绪分析
我们需要做的第一件事是设计一个数据模型来分析Twitter上用户的情绪和影响。此图是图形数据模型,我们将用于从 Twitter 导入、分析和查询数据。