在本文中,我们将致力于让您更好地了解使用 Flink 自下而上的流处理;云服务和其他平台提供流处理解决方案(对于某些平台,Flink 集成在引擎盖下)。如果您错过了基础知识,本指南是为您介绍的。
我们的单体解决方案无法应对传入数据增加的负载,因此必须不断发展。现在是我们下一代产品的时候了。与迄今为止实现的批处理相比,流处理是新的数据引入范例。
因此,我的团队开始使用 Flink 处理信息。有很多关于Flink的功能和好处的文章。Cloudera 分享了一张关于 Flink 的优秀幻灯片;本文是一个实用的实践指南,了解如何从基础知识构建一个简单的流处理应用程序。
阿帕奇Flink在短
Apache Flink 是一个可扩展的分布式流处理框架,这意味着它能够处理连续的数据流。此框架提供多种功能:源、流转换、并行处理、调度、资源分配和广泛的目标。它的一些连接器是HDFS,卡夫卡,亚马逊基尼塞,兔子MQ和卡桑德拉。
Flink 以其高吞吐量和低延迟而闻名,支持一致性(所有数据一次处理,无需重复),并且还支持高可用性。与任何其他成功的开源产品一样,它具有广泛的社区来培养和扩展其功能。
Flink 可以处理不确定的数据流或明确的数据集。此博客将侧重于前者(使用 DataStream 对象)。
流处理 :挑战
如今,当物联网设备和其他传感器无处不在时,数据会源源不断地流动。这种无休止的数据流迫使传统的批处理计算适应。
- 此数据是无界的;没有开始和结束。
- 新数据的不可预测和不一致的时间间隔
由于这些独特的特点,处理和查询数据是复杂的任务。结果变化迅速,几乎不可能得出明确的结论;有时,当尝试生成有效结果时,计算可能会受到阻碍。此外,结果不可重复,因为数据不断变化。最后,延迟是一个因素,因为它会影响结果的准确性。
Apache Flink 基于传入数据源中的时间戳进行处理,从而解决这些问题。在应用处理执行之前,它有一种机制来根据事件的时间戳来累积事件。它消除了微批次的使用,并因此提高了结果的准确性。
Flink 完全实现一次一致性,这可确保计算的正确性,而无需开发人员编程。
基础 : 链接包构建基块
Flink 主要从各种来源引入流。基本对象是 DataStream<T> ,它表示相同类型的元素流;其元素的类型是通过设置泛型类型 T(在此处阅读有关DataStream 对象)在编译时定义的。
DataStream 对象包含许多用于转换、拆分和筛选其数据的有用方法[1]。熟悉方法映射、减少和筛选是一个良好的开端;这些是主要的转换方法:
映射:接收 T 对象并返回 R 类型对象的结果;Map函数在 DataStream 对象的每个元素上仅应用一次。
单输出流操作员地图(T减少:接收两个连续值,并在将它们合并到同一对象类型后返回一个对象;此方法在组中的所有值上运行,直到仅保留一个值。
T reduce(T value1, T value2)筛选器: 接收 T 对象并返回 T 对象的流;此方法在 DataStream 中的每个元素上运行,但仅返回函数返回 true 的元素。
单输出流操作员<T> 过滤器(过滤器功能<T> 过滤器)数据接收器
除了转换数据外,Flink 的主要目的是在将流处理到不同的目的地后引导它们。这些目的地称为"接收器"。Flink 具有内置接收器(文本、CSV、套接字),以及与其他系统(如 Apache Kafka)的开箱即用连接器[2]定义时间戳有三个选项:
处理时间 (默认选项):是指执行流处理操作的计算机的系统时间,因此它是最简单的时间概念;它不需要流和计算机之间的任何协调。由于它基于计算机的时间,因此可提供最佳性能和最低的延迟。
在分布式和异步环境中,使用处理时间的缺点是显著的,因为它不是确定性方法。如果计算机时钟之间存在间隙,则流事件的时间戳可能会不同步;网络延迟还会在事件离开一台计算机到达另一台计算机的时间之间产生间隙。
Java
xxxxxxx11流恩夫。设置流时间特征(时间特征.处理时间;事件时间:指每个单个事件在输入 Flink 之前在其生成源上接收的时间。事件时间嵌入到事件本身中,可以提取,以便 Flink 可以正确处理它。
由于时间戳不是由 Flink 设置的,因此应该有一个机制来发出事件应处理或不处理的机制;此机制称为水印。本主题超出了此博客文章的范围(因为我想保持简洁);您可以在Flink 文档中找到更多信息。
Java
xxxxxxx1251流恩夫。设置流时间特征(时间特征.活动时间;3数据流<字符串>数据流4*流恩夫。读取文件(审核格式,5数据Dir ,// 事件的代名词6文件处理模式.PROCESS_CONTINUOUSLY,71000)。8新的时间戳提取器());1011// ...更多代码...1213定义类以从流事件中提取时间戳14公共类时间戳提取器实现15分配者具有周期性水印<字符串>|16公共水印获取电流水印() |18返回新的水印(系统.当前时间米 ()-最大时间帧);19}2021公共长提取时间戳(字符串str长l) |23返回输入数据。获取数据对象(str)1px;"> }
25}摄取时间:指事件进入Flink的时间;它在源处分配一次,因此被认为比处理时间更稳定,处理时间在开始过程时分配。
引入时间无法处理顺序外事件或延迟数据,因为时间戳是在引入开始后设置的,而不是具有标识延迟事件并根据水标记机制处理延迟事件的功能的事件时间。Java
xxxxxxx11流恩夫。设置流时间特征(时间特征.摄取时间;您可以在以下链接中阅读更多有关时间戳及其如何影响流处理。
窗口
顾名思义,流是无穷无尽的;因此,处理机制是通过定义帧(例如,基于时间的窗口)。这样,流将分为存储桶进行聚合和分析。窗口定义是
DataStream对象或其继承器的操作。有几个基于时间的窗口:
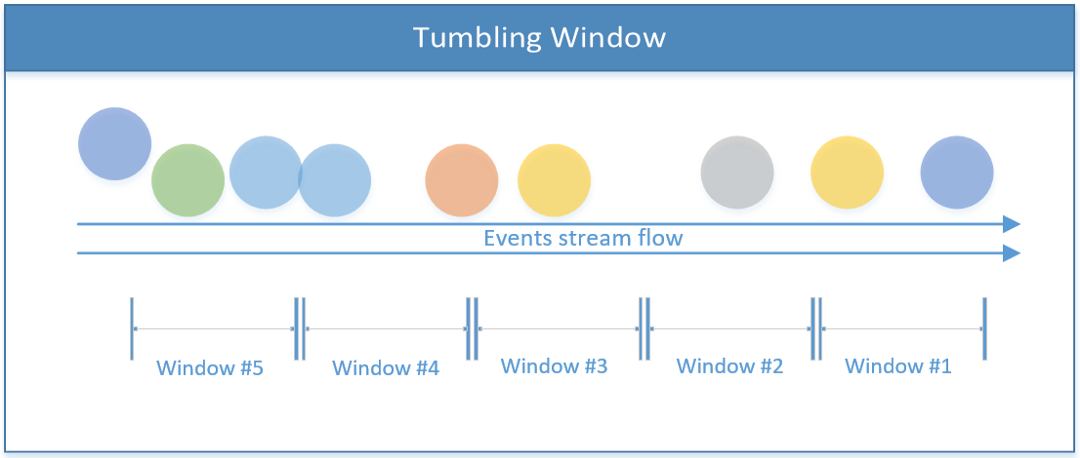
翻转窗口(默认配置)
流被划分为等效大小的窗口,没有任何重叠。只要流流,Flink 会基于此固定时间范围连续计算数据。翻滚窗口
代码实现:
Java
xxxxxxx11公共所有窗口流<T,时间窗口> 时间窗口全部(时间大小)3基于键的流的翻滚窗口4公共窗口流<T,键,时间窗口>时间窗口(时间大小)滑动窗口
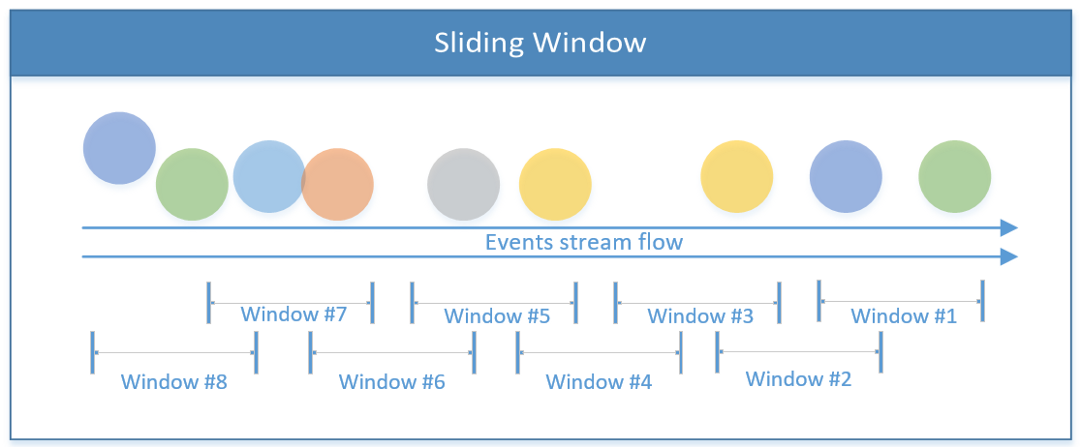
由窗口大小和偏移量(何时启动下一个窗口)组成的重叠窗口。这样,可以在给定时间内在多个窗口中处理事件。滑动窗口
这就是它在代码中的外观:
Java
xxxxxxx11滑动时间窗口长度为 1 分钟,触发间隔为 30 秒2数据流对象。时间窗口(时间.分钟(1次)。秒(30));会话窗口
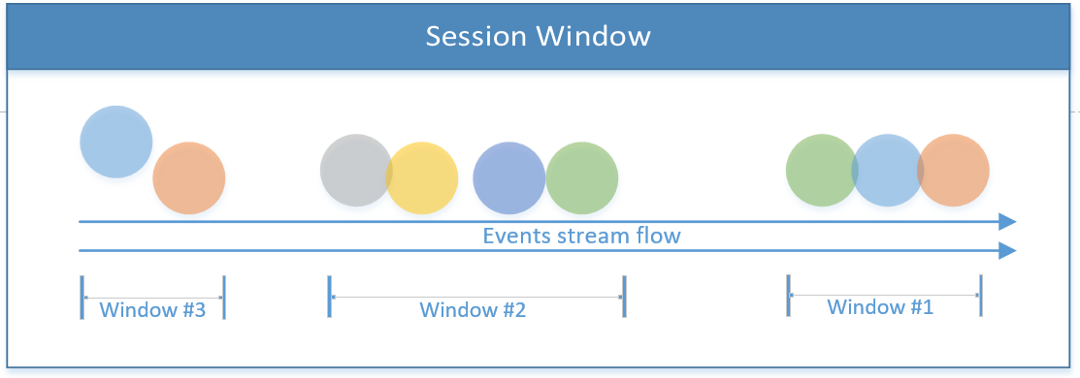
包括会话边界下的所有事件此时间范围可以基于已处理的事件进行固定或动态。从理论上讲,如果会话事件之间的间隙小于窗口的大小,则会话永远不会结束。会话窗口
下面的第一个代码段举例说明了基于时间的固定会话(2 秒)。第二个会话窗口实现一个动态窗口,该窗口基于流的事件。
Java
xxxxxxx11数据流对象。窗口(处理时间会话窗口)。与间隙(时间.秒(2));34定义动态窗口会话,该会话可以由流元素设置5数据流对象。窗口(事件时间会话窗口)。与动态差距(elem-> |6// 返回会话间隙,该间隙可以基于流的事件7}));全局窗口
将整个流视为单个窗口。全局窗口
Flink 还支持使用用户定义的逻辑实现自定义窗口,这将是另一个博客文章的主题。
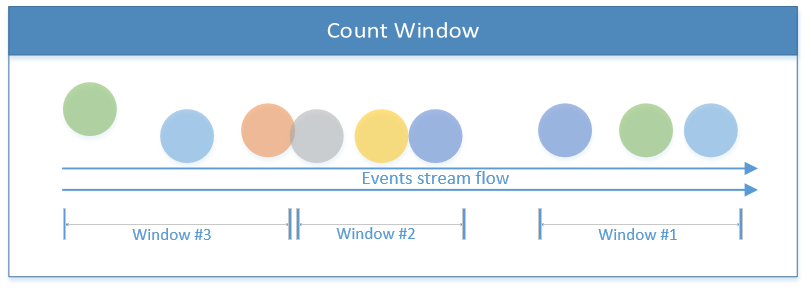
除了基于时间的窗口之外,还有其他窗口,如计数窗口,它几乎取决于传入事件的数量限制;达到 X 阈值后,Flink 将处理 X 事件。下图描述了三个元素的计数窗口:
计数窗口
在理论介绍之后,让我们深入了解一个实用的数据流。您可以找到有关 Apache Flink 和流进程的详细信息。
官方网站。蒸流描述
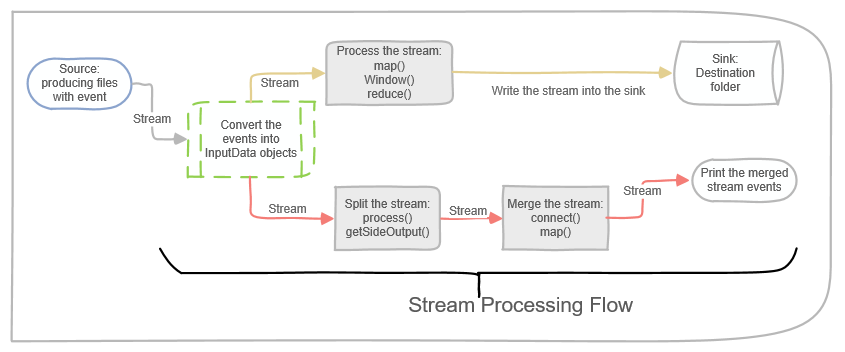
为了回顾一下理论部分,下图描绘了本博客文章中代码样本的主要数据流。下面的流从源开始(文件写入文件夹),并继续将事件处理到对象中。
下面描述的实现由两个处理轨道组成。顶部的流将流拆分为两个侧流,然后合并它们以形成第三种类型的流。底部的方案处理流,然后将结果传输到接收器中。
流处理工作流
下一部分旨在将理论流处理转化为实际实践;您可以找到完整的源代码
基本流处理(示例#1)
从基本应用程序开始更容易理解Flink的概念。在此应用程序中,生产者将文件写入一个文件夹,该文件夹模拟流动流。Flink 从该文件夹中读取文件,处理这些文件,并将摘要写入目标文件夹;这是水槽。
现在,让我们关注流程部分:
1. 将原始数据转换为对象:
Java
xxxxxxx11数据流<输入数据> 输入数据对象流3•数据流4.地图(地图功能<字符串输入数据>输入Str-> |5在反转到对象之前,先对原始数据进行浏览6系统。出。println("---接收事件 :"=输入斯特);7返回输入数据1px;"> });
2. 下面的代码示例将流对象 (InputData) 转换为字符串和整数的元数。它仅从对象流中提取某些字段,在两秒内按一个字段进行分组。
Java
xxxxxxx1151数据流<Tuple2<字符串,整数>> 用户计数3•输入数据对象流4.地图(新的地图功能<输入数据,Tuple2<字符串,整数>>() |56公共图普尔2<字符串,整数>映射(输入数据项) |8获取名称() ,项目.获取分数() ;9}10})11.返回(类型。图普尔(类型.字符串类型。INT))12.键由(0) // 返回键控流<T, Tuple> 基于第一个项目 ('名称' 字段)13//.timeWindowAll(时间.秒(窗口间隔))//不要将时间窗口全部用于基于键的流14时间窗口(时间.秒(2 )//返回窗口流<T, 键, 时间窗口>15.减少(x,y->新的Tuple2<字符串,整数>x.f0="-"=y。f0x.f1=y。f1);
3. 为流创建目标(实现数据接收器): Java
xxxxxxx1211定义时间窗口并计算记录数2数据流<Tuple2<字符串,整数>>输入计数摘要3.地图(项目)5->新的图普尔2<字符串,整数>6(字符串。值(系统。当前时间米(),1))17.返回(类型。图普尔(类型.STRING ,类型。INT))8.时间窗口所有(时间.秒(窗口间隔// 一个通布窗口9减少(x,y) -> // 和数字,直到达到单个结果10(新图普尔2<字符串整数>(x。f0x.f1=y。f1)););1112// 将流式处理文件接收器设置为输出目录13最终流文件沉没 <Tuple2<字符串,整数>>计数Sink14.forRowFormat(新路径(输出 Dir)16新的简单字符串编码器<Tuple2<字符串,整数>>17("UTF-8"))18.生成();1920// 将接收器文件流添加到 DataStream;这样,输入计数摘要将写入 countSink 路径21添加 Sink(计数 Sink);拆分流(示例#2)
在此示例中,我们将演示如何在使用边输出流时拆分主流。Flink 能够从主 生成多个侧流
DataStream。驻留在每个端流中的数据类型可能因主流和每个端流而异。因此,使用边输出流可以在一次拍摄中杀死两个鸟:拆分流并将流类型转换为多种数据类型(对于每个端输出流来说可能是唯一的)。
下面的代码示例调用
ProcessFunction,该示例基于输入的属性将流拆分为两个侧流。为了获得相同的结果,我们应该多次使用函数filter。将
ProcessFunction某些对象(基于条件)收集到主输出收集器(在 中捕获SingleOutputStreamOperator),同时向端输出添加其他事件。DataStream垂直拆分并发布不同的格式。请注意,侧输出流定义基于唯一的输出标记(
OutputTag对象)。Java
使用名称和计数创建输出元组
ctx.输出(歌手塔格,
新的图普尔2<斯特林,Integer>
(输入数据.getName()、输入数据.getScore());
断裂;
案例"玩家":
使用名称和类型创建输出元组;
如果新创建的元组与播放器 Tag 类型不匹配,则会引发编译错误("方法输出不能应用于给定类型")
ctx.输出(播放器标签,
新的图普尔2<弦,弦>
(输入数据.getName()、输入数据.getType());
断裂;
默认:
将主输出收集为输入数据对象
输入数据.收集(输入数据);
断裂;
}
}
\"数据朗="文本/x-java"|xxxxxxx1471最终输出标签<Tuple2<字符串,字符串>> > 播放器标签3•新的输出标签<Tuple2<字符串,字符串>>("播放器")*;45// 为歌手定义单独的流6最终输出标签<Tuple2<字符串,整数>>歌手标签7// 将每个记录转换为 InputData 对象,并将主流拆分为两个侧流。10单输出流运算符<输入数据>输入数据主11•输入流12.进程(新进程函数<字符串输入数据>() |1314公共无效过程元素(16字符串输入Str,17上下文ctx,18收集器<输入数据>collInput数据) |1920乌蒂尔斯。打印(Utils。COLOR_CYAN"收到记录"=+输入斯特尔;21// 将字符串转换为输入数据对象23输入数据输入数据=输入数据。获取数据对象(输入Str);2425开关(输入数据)。获取类型())26{27案例"歌手":28//创建具有名称和计数的输出元数30ctx.输出(歌手Tag,31新的图普尔2<字符串,整数>32(输入数据.获取名称输入数据。获得分数());33断裂;34// 使用名称和类型创建输出元数;36// 如果新创建的元组与播放器 Tag 类型不匹配,则会引发编译错误("方法输出不能应用于给定类型")37ctx.输出(播放器标签,38新的图普尔2<字符串String>39(输入数据.获取名称输入数据。获取类型());40默认值:42// 将主输出 收集为输入数据对象43collInput数据。收集(输入数据);44断裂;45}46}47合并流是通过调用 方法connect,然后在每个单个流中的每个元素上定义映射操作来完成的。结果是合并的流。Java
xxxxxxx1281互联流<Tuple2<字符串,整数>, Tuple2<字符串,字符串>> 合并流3•歌手流4.连接(播放器流);567数据流<Tuple4<字符串String字符串整数>>组合流8地图(新的 CoMap 函数<9元数2<字符串整数>//流 110元数2<字符串String>//流 211元数4<String字符串字符串整数>//输出12>() |1314公共图普尔4<字符串,字符串,字符串,整数> //进程流 116地图1(图普尔2<字符串整数>歌手抛出异常|17返回新的图普尔4<字符串字符串String整数>18(来源:歌手流)歌手。f0""歌手singer。f1;19}2022公共图普尔4<字符串String字符串整数>//进程流 223地图2(图普尔2<字符串String>玩家抛出异常|24返回新的图普尔4<字符串字符串String整数>25(来源:玩家流)球员。f0播放器。f10);26});28构建可行的项目
综合起来:我把一个演示项目上传到GitHub。您可以按照有关如何生成和编译它的说明进行操作。这是一个良好的开端,发挥与弗林克。
我希望你觉得这个回购有用。如果您有任何问题,请随时与我联系。
外卖
本文重点介绍了构建基于 Flink 的工作流处理应用程序的基本基础。其目的是提供对流处理挑战的基本了解,并为构建独立的 Flink 应用程序奠定基础。
由于流处理具有许多方面和复杂性,因此未涵盖许多主题。例如,Flink 执行和任务管理、使用水印将事件时间设置为流事件、在流的事件中种植状态、运行流迭代、在流上执行类似 SQL 的查询等等。我希望在后续文章中介绍其中一些主题。
然而,我希望这个博客为您配备必要的信息,开始使用Flink。
继续编码!
• Lior
资源
[1] 数据流操作:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/index.html
[2] 数据接收器:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html#data-sinks