
作者:jeromeliang,腾讯 PCG 应用研究员
为了提升用户在腾讯视频 app 的内容消费人数,消费次数,消费时长,我们需要定向精准的内容分发,让用户以较小的时间成本,较好的用户体验获取平台能够提供的感兴趣内容。因此,如何高效精准地实现个性化内容分发是我们面临的一个主要的挑战。
一.背景
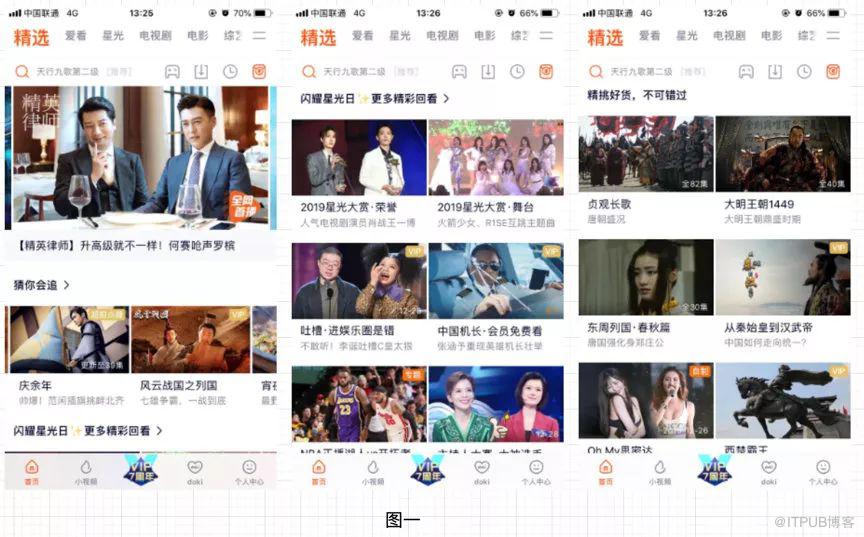
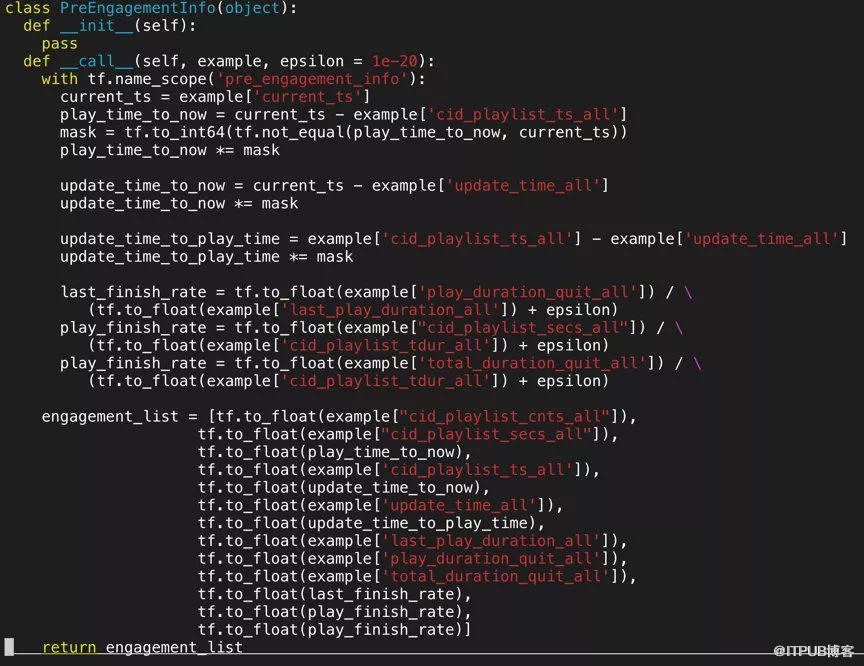
为了提升用户在腾讯视频 app 的内容消费人数,消费次数,消费时长,我们需要定向精准的内容分发,让用户以较小的时间成本,较好的用户体验获取平台能够提供的感兴趣内容。因此,如何高效精准地实现个性化内容分发是我们面临的一个主要的挑战。腾讯视频内容分发的主要场景如下图一所示,当前,长视频内容推荐系统通过召回,精排,重排等阶段从候选内容池子中实时返回每个用户在每次请求最可能感兴趣的内容。其中精排阶段起关键作用,它决定最后展示给用户的少数内容是否足够准确匹配用户实时的兴趣。为了在精排阶段实时精准的预测用户的兴趣,我们需要充分的挖掘用户在腾讯视频的兴趣反馈信号,并对根据数据特点进行建模,准确挖掘隐藏在反馈信号和用户感兴趣内容之间的模式。为此,我们收集用户的隐式反馈信号,并设计符合长视频特点的兴趣网络。
二.方案
1.用户隐式反馈信号
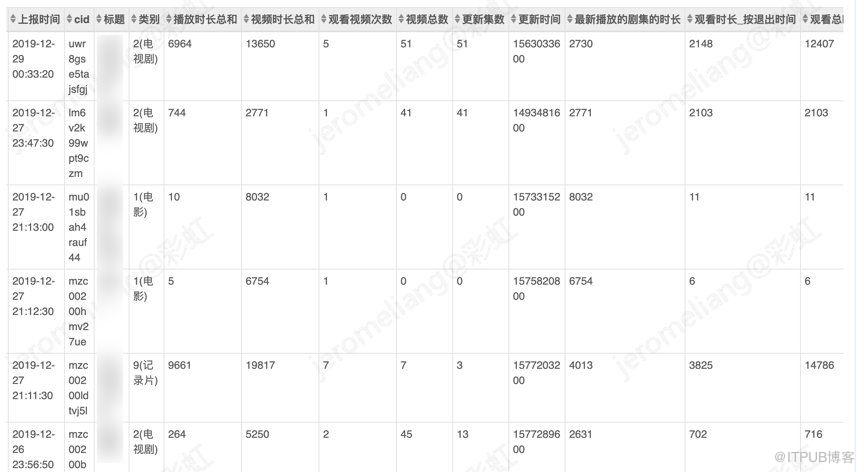
腾讯视频用户的反馈信号有显示反馈信号和隐式反馈信号两部分,由于点赞等显示反馈信号极其稀疏,我们主要使用用户播放行为反馈的隐式信号。目前已经收集的播放反馈信息主要有用户播放的视频专辑,播放时间,播放总时长,播放次数,最新一集剧集的播放时长,按照退出播放器计算的播放总时长,观看的最大集数等。用户反馈信号采用实时上报的方式,某个用户的反馈信息如下图所示:
2.长视频兴趣网络
2.1 深度神经网络总体结构
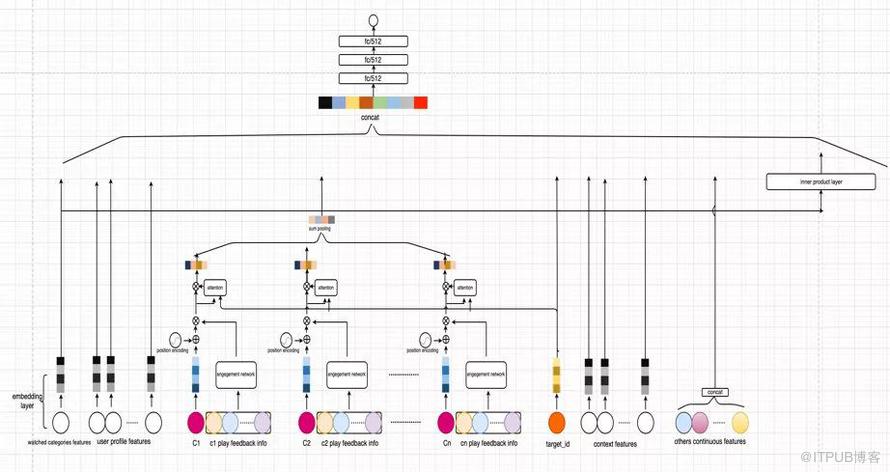
2.2 兴趣网络结构
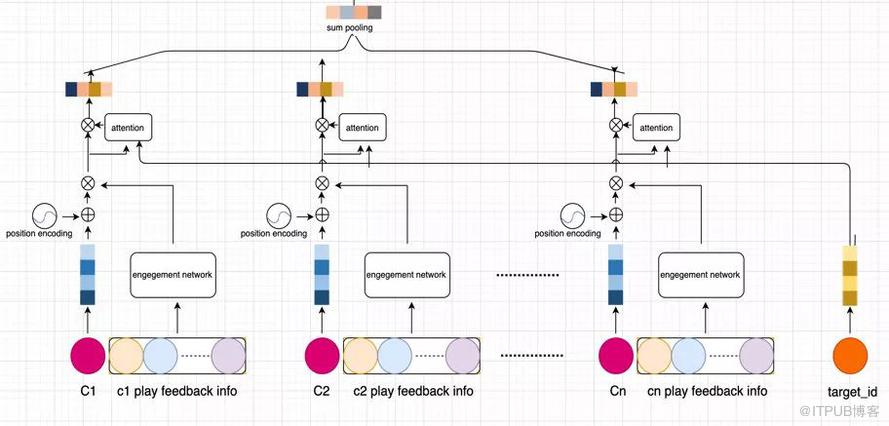
图中 ci 表示某个用户播放过的第 i 个视频专辑。Ci play feedback info 表示某个用户播放视频专辑 ci 的播放反馈信息。Target_id 表示需要预估的视频专辑。
首先,每个视频专辑经过 embedding 层,将专辑 id 映射层低维稠密的专辑 embedding,用 ei 表示。然后累加专辑在播放序列中的位置编码 encoding,加入位置信息。用户对每个专辑的播放反馈信息经过共享的 engagement network 输出 engagement weight 表征用户对该专辑的兴趣兴趣强度,并用 engagement weight activat ei,输出 di。
接着 Target embedding attente di 输出 content similar weight activate di 后输出 eout_i,最后 sum pooling 后输出低维稠密 embedding(size=128)用来表达用户在看到候选的 target 专辑后的兴趣。从物理意义上理解为,用户对内容兴趣具有多峰特点,用户在看到不同内容表现出不同的兴趣。兴趣网络部分实现如下图所示:
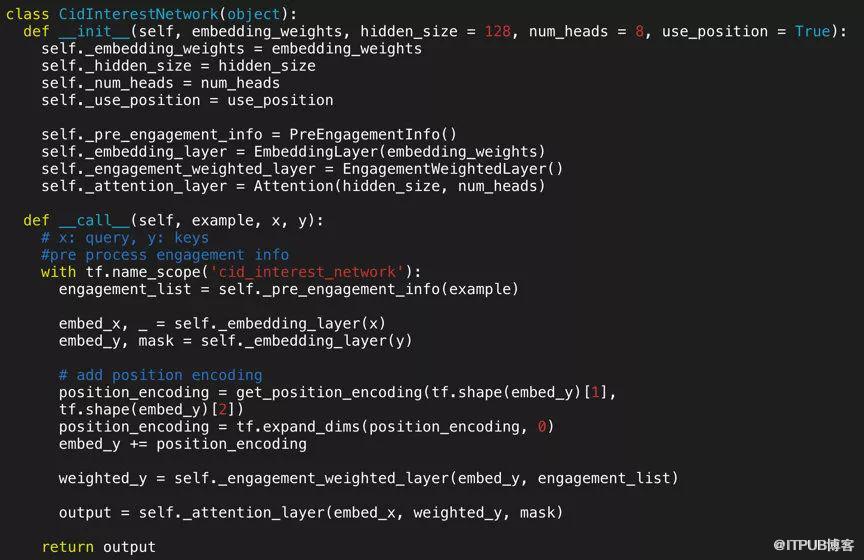
接下来分别介绍 engagement 网络模块,position encoding 模块,attention 模块。
2.2.1Engagement 网络模块结构
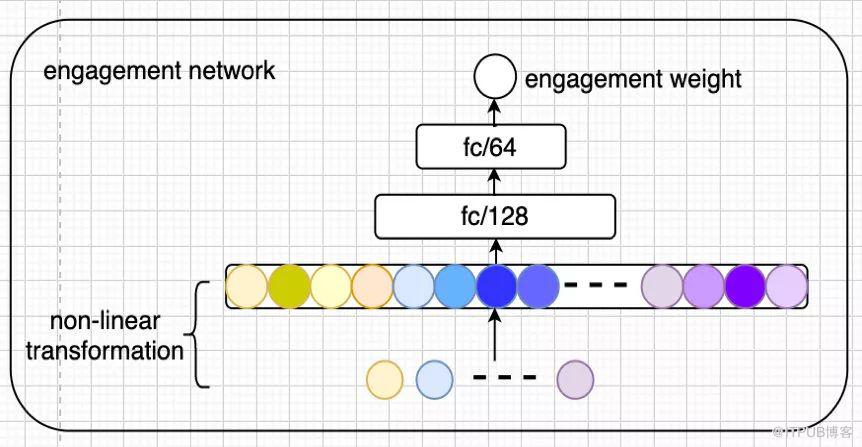
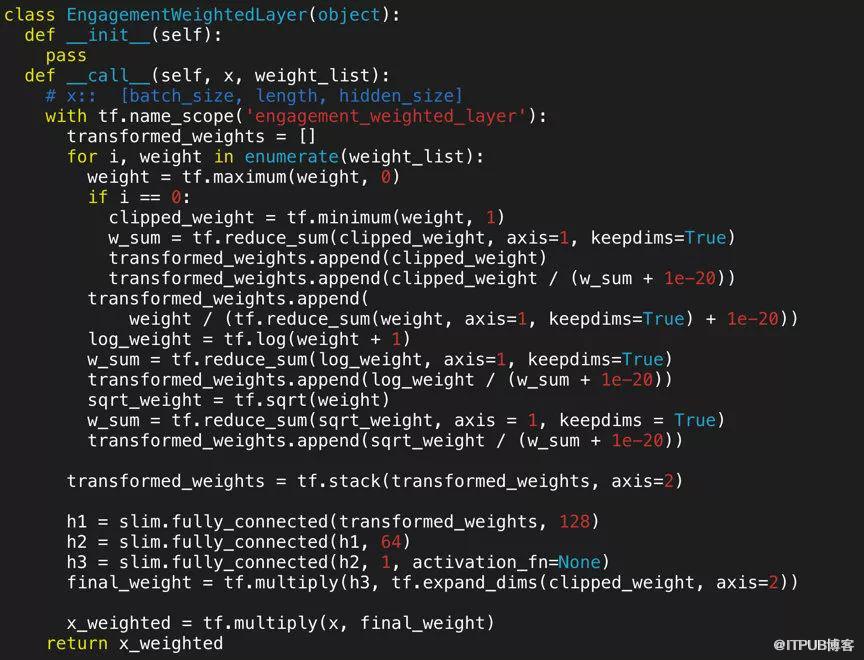
用来表示用户 engagement 信息(播放时间,播放总时长,播放次数,最新一集剧集的播放时长,按照退出播放器计算的播放总时长)的连续信号经过 log,sqrt 等非线性变换后 concat 原始信号输入到两层隐藏层的 engagement 网络,输出表达用户兴趣强度的数值。部分源码实现如下图所示:
2.2.2Position encoding 模块
我们认为,如果同一内容在播放序列中的不同位置,用户实时兴趣的会不同。因此,通过对专辑在播放序列的位置进行编码用来表达位置信息。我们采用 sin 和 cos 函数对位置编码。具体的位置编码方式如下:
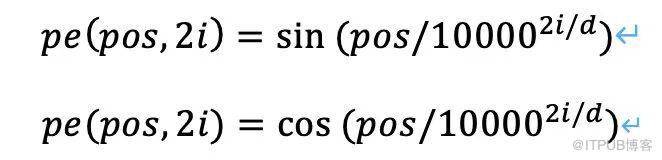
其中 pos 表示专辑的位置,d 表示编码的位置向量的长度,i 表示编码的向量维度的位置。具体实现如下图所示:
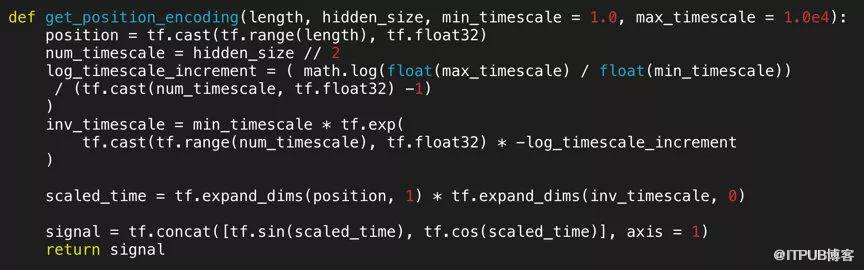
2.2.3Multi-heads attention 模块
为了表达用户在看到候选的预估内容的兴趣,我们使用 multi-heads scaled dot-product attention,对候选 target attente 用户历史的播放兴趣点,获得对每个兴趣点的兴趣强度,并分别对每个兴趣点加权,最后 sum pooling 后的 embedding 作为用户看到 target 的兴趣 embedding。具体的 attention 方式如下所示:
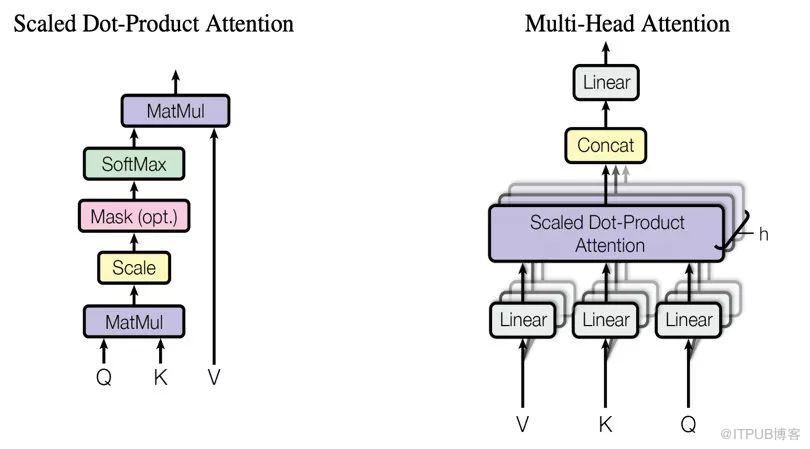
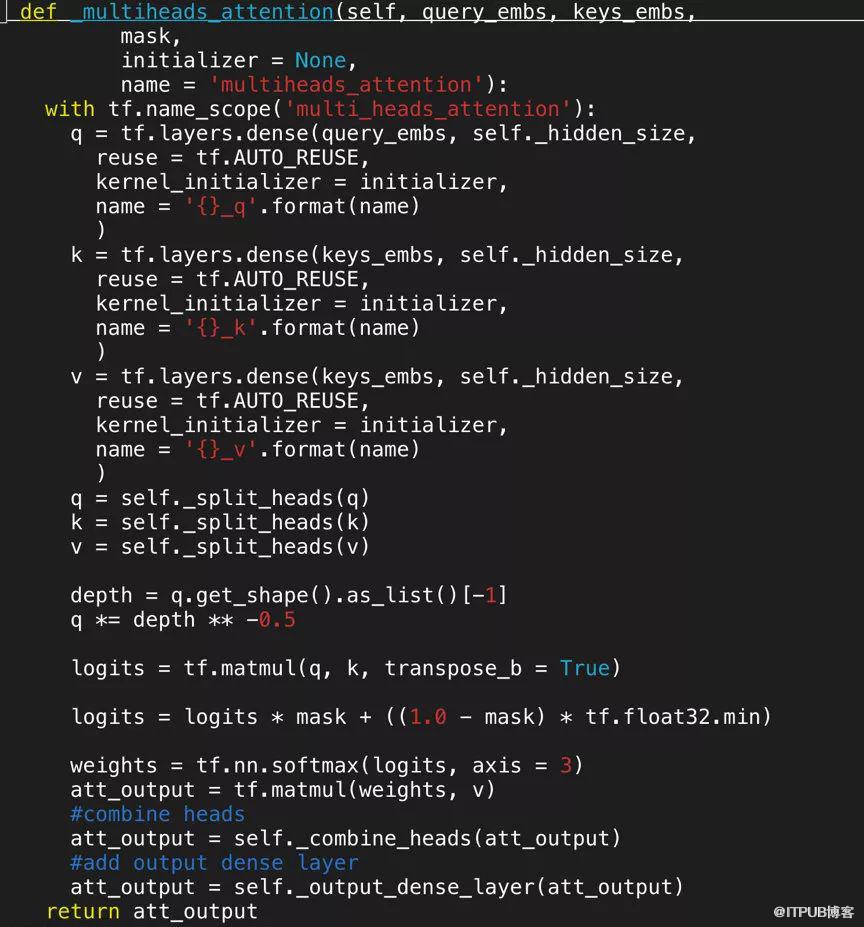
三.实验
3.1 离线实验
实验采用过去 7 天腾讯视频 app 线上真实用户反馈数据作为训练数据,训练样本规模在数十亿量级。线上随机划分的一个小分桶流量在第 8 天的反馈数据作为测试集,样本规模在 80-90 万之间。
离线评估指标分别是 auc,vv-auc,vt-auc,gauc,vv-gauc,vt-gauc,cg,vv-cg,vt-cg。Gauc 表示 group auc。本次实验采用请求 id 作为 group id,也即相同请求的曝光和播放反馈视为同一个 group,gauc 指标等于所有 group 内的 auc 的平均值。Cg,即 cumulative gain 表示累积收益,具体可参考 ndcg 指标。vv 表示播放次数,vt 表示 viewed time,即观看时长,上述 vv-auc,vt-auc,vv-gauc,vt-gauc,vv-cg,vt-cg 等指标均表示在 auc,guc,cg 等指标基础上进一步加权计算,考虑 vv,vt 等反馈收益。
离线实验分别与以播放量和播放时长为目标的排序模型作为 base 做对比实验。实验组和对照组(tf-dnn-base)的唯一区别是,实验组有长视频兴趣网络。具体离线实验结果如下:

vv-兴趣网络对比 vv-base,vv-auc 提升 4.08%,vv-guac 提升 3.78%,vv-cg 提升 8.57%。vt-兴趣网络对比 vt-base,vt-auc 提升 3.23%,vt-gauc 提升 3.02%,vt-cg 提升 7.19%。
3.2 在线实验
以播放量为目标的线上模型实验,vv-base:rank-1020,vv-兴趣网络:rank-1040,整体效果对比如下:
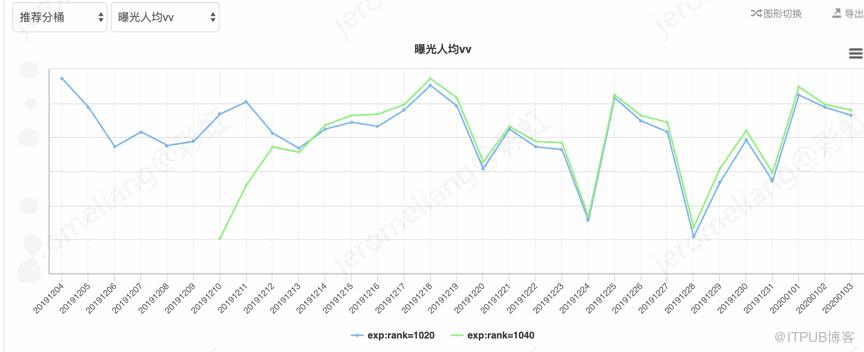
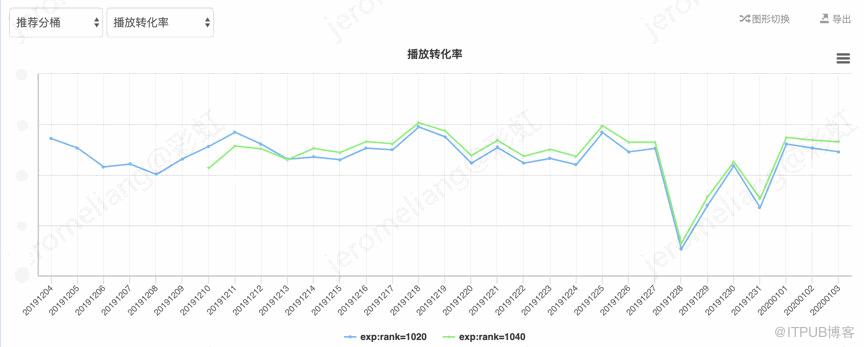
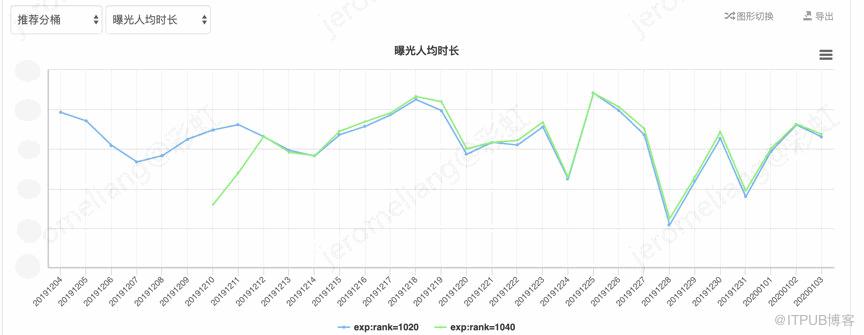
其中曝光人均 vv=总播放次数/曝光人数(去重),播放转化率=播放人数(去重)/曝光人数(去重),曝光人均时长=总时长/曝光人数(去重),下同。对比 vv-base,vv-兴趣网络平均曝光人均 vv 提升 1.55%,平均播放转化率提升 1.39%,平均播放时长提升 1.3%。
由于长视频具有头部内容重,即少数头部剧集占据大量的播放,平台用户具有明显的追剧倾向等特点。追剧模块的追剧推荐占据大量播放,且该模块的追剧推荐由于考虑平衡体验和效果而采用对用户潜在的追剧内容进行规则排序,不直接受到推荐模型的影响。因此接下来观察线上直接受到 ranking 模型影响的内容分发的效果,刨除规则追剧推荐数据后对比如下:
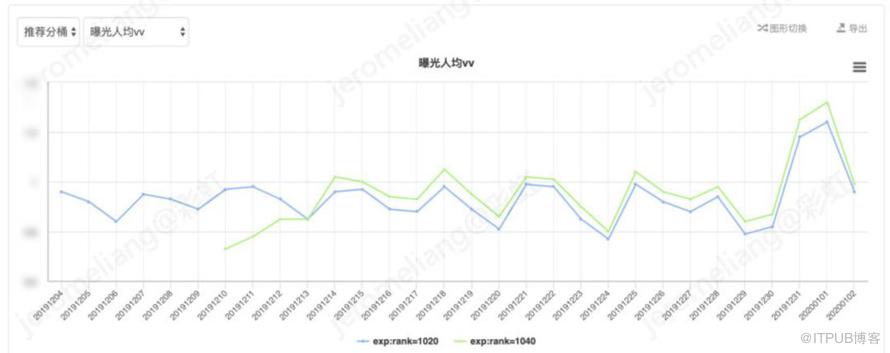
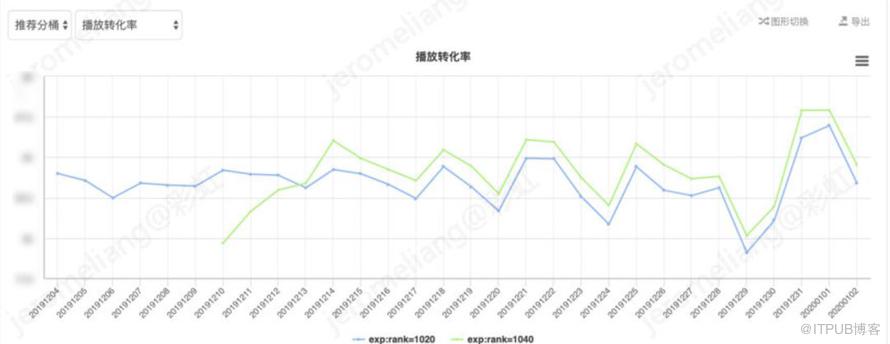
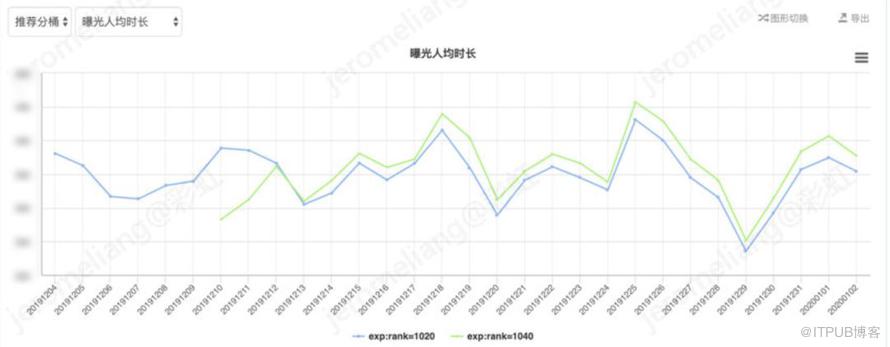
剔除规则追剧推荐部分,对比 vv-base,vv-兴趣网络的曝光人均 vv 提升 5.18%,播放转化率提升 4.95%,曝光人均时长提升 6.35%。
以时长为目标的线上模型实验,vt-base:rank-1012,vt-兴趣模型:rank-1039。线上可参考对比整体实验效果如下:
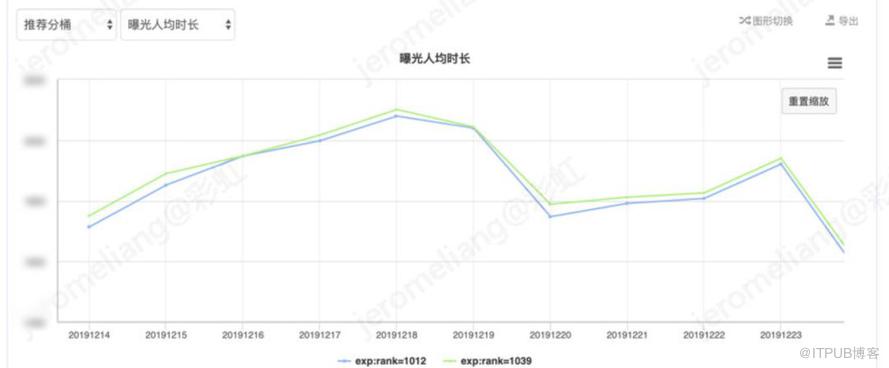
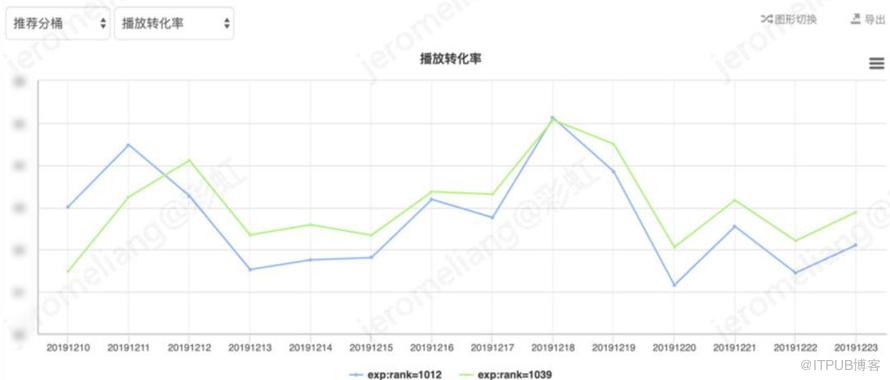
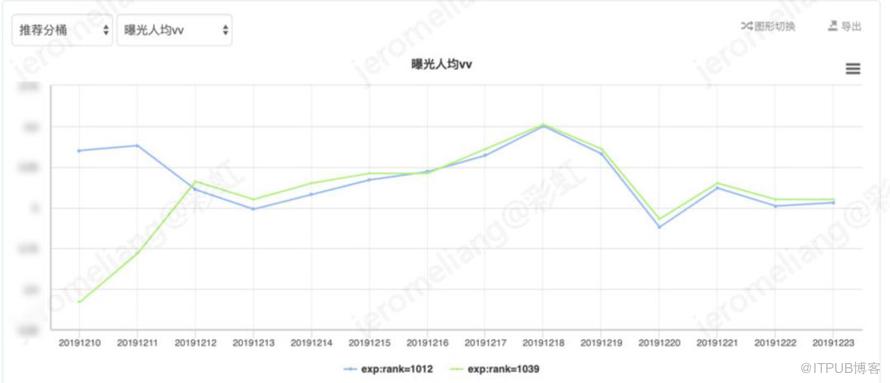
对比 vt-base,vt-兴趣网络整体平均曝光人均时长提升 1.28%,平均播放转化率提升 1.18%,平均曝光人均 vv 提升 1.12%。
剔除规则追剧推荐数据后对比如下:
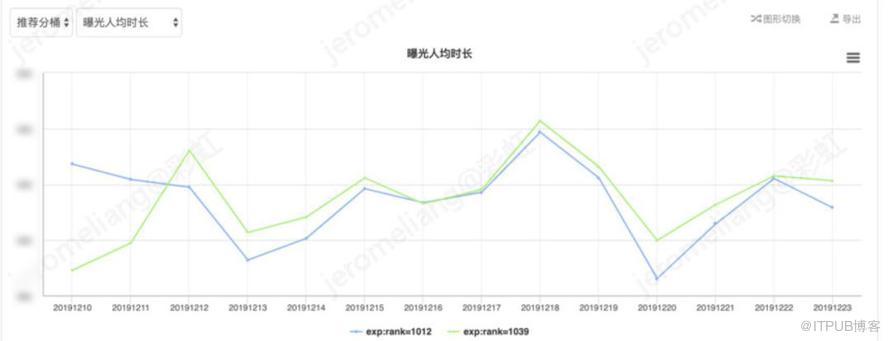
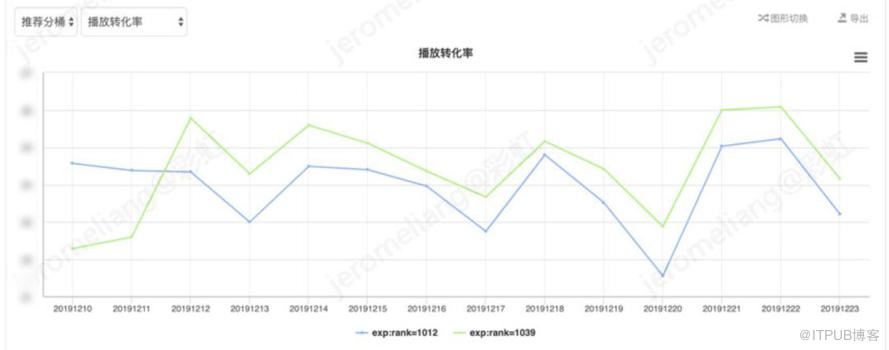
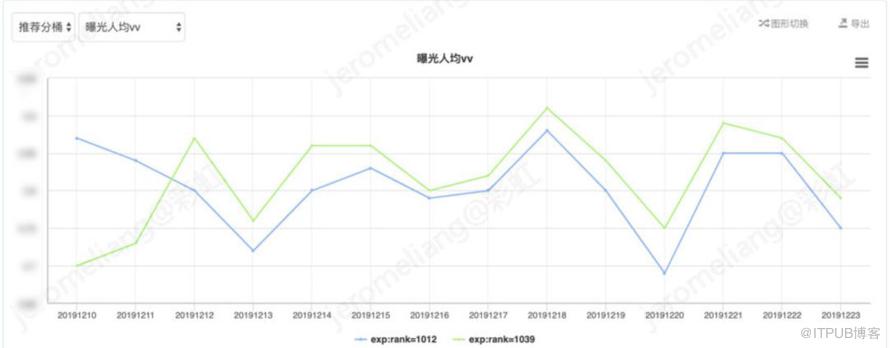
剔除按规则排序的追剧推荐部分,对比 vt-base,vt-兴趣网络的平均曝光人均时长提升 4.07%,平均播放转化率提升 3.91%,平均曝光人均 vv 提升 4.64%。
针对长视频内容的组织和分发特点设计的长视频兴趣网络能够有效挖掘用户的兴趣点,做到更加精准内容分发,从而带来更多的播放量,时长和播放人数等收益。但当前长视频兴趣模型仍然存在急待解决的问题,由于 offline 资源问题,模型延迟仍然较大,多数时候延迟在 24-35 小时之间。同时由于兴趣模型结构计算相对复杂,线上实时预估耗时比 base 明显偏高,线上打分失败的视频占比在 3%左右,越活跃用户特征越丰富,计算量越大,打分越容易失败。因此,有一部分潜在收益会被模型延迟和预估失败吃掉。
四.总结与展望
本文简单介绍了我们在腾讯视频个性化推荐业务中兴趣挖掘的初步探索。针对长视频内容的组织和分发特点,收集能够反映用户内容兴趣的隐式反馈信号,并基于数据的特点构建长视频内容兴趣网络,挖掘用户观看不同的内容表达出的不同兴趣点。后续,我们进一步根据数据的特点以及当前兴趣网络的缺点做进一步的改进优化。本文行文简单粗略,如有错漏,欢迎指正。
五.参考文献
- AttentionIsAllYouNeed
- Deepinterestnetworkforclick-throughrateprediction