
本文将详细介绍基于个性化一致性哈希的流量均衡方法。
目录
- 业务增长带来的流量均衡需求
- 基于一致性哈希的调度策略
- 个性化一致性哈希的负载均衡
- 流量均衡在Talos中的实现
前文《小米消息队列的实践》介绍了小米自研消息队列Talos的业务背景和关键问题。其中在网卡资源优化方面,Talos主要做了两方面工作:客户端寻址与基于流量的个性化一致性哈希。前者是通过客户端自寻址避免Server转发节省网卡资源,后者是通过优化一致性哈希的虚拟节点数配置,调整节点的流量分配情况。本文将详细介绍后者——基于个性化一致性哈希的流量均衡方法。 业务增长带来的流量均衡需求 Talos作为高吞吐型的消息队列服务,随着业务增长,带宽往往会成为瓶颈。如果网卡流量不均衡,就会产生集群网卡资源的木桶效应—— 当集群中使用网卡最多的机器达到资源瓶颈就要触发扩容,即便此时该集群其他节点网卡有大量富余,机器成本因此浪费。且随着业务量越来越多,集群规模不断变大,问题变得更加明显。以小米某线上集群为例,该集群150台机器,将各节点的日流量均值绘制成散点图以方便观察其流量均衡程度。其中最高流量324M,最低134M,相差两倍不止。
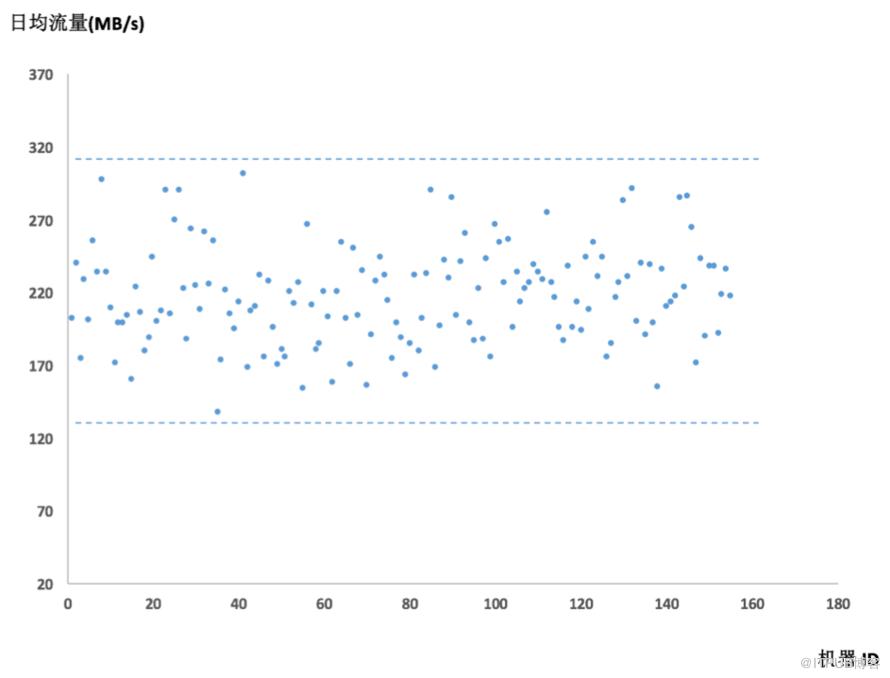
分析此问题,机器节点网卡流量的大小,和该节点所serve的所有Partition流量之和呈正相关。要解决节点间网卡负载不均衡的问题,需要调整Partition在各节点的分布情况(即改变Partition的调度关系)。下面我们将简单介绍下优化前Talos所使用的调度机制,再来分析如何做到这一点。 基于一致性哈希的调度策略 Talos使用一致性哈希来约定Partition调度关系。简单来讲,一致性哈希可以理解为一个函数,Y = ConsistentHash (X)。任意的X取值都能映射为一个固定区间内的唯一数值Y.举例说明,我们将10节点集群中各节点做映射,用下面的环状图表示。那么区间被分成了10份。同样将Partition映射也映射到环上,根据其位置区间,来决定由哪个节点所serve. 集群所有节点都遵从这个约定从而调度信息一致。实际上,为了使圆环划分的更加均匀和节点上下线更加稳定,每个机器节点将对应多个虚拟节点以力求平均。传统的一致性哈希,每个节点映射的虚拟节点个数是一致的。例如,Talos每个机器节点对应的虚拟节点个数都是2000个。
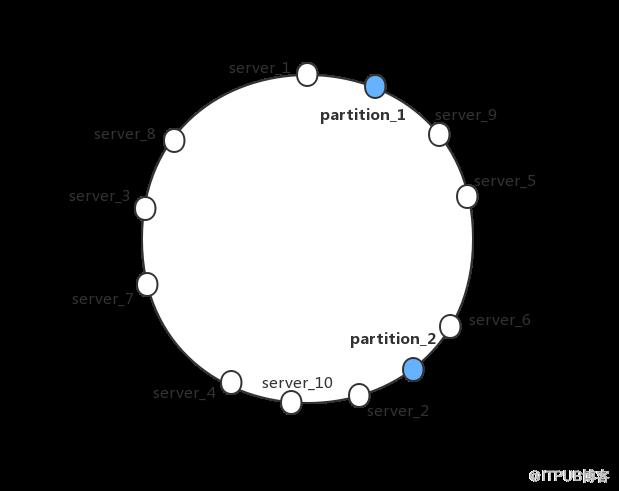
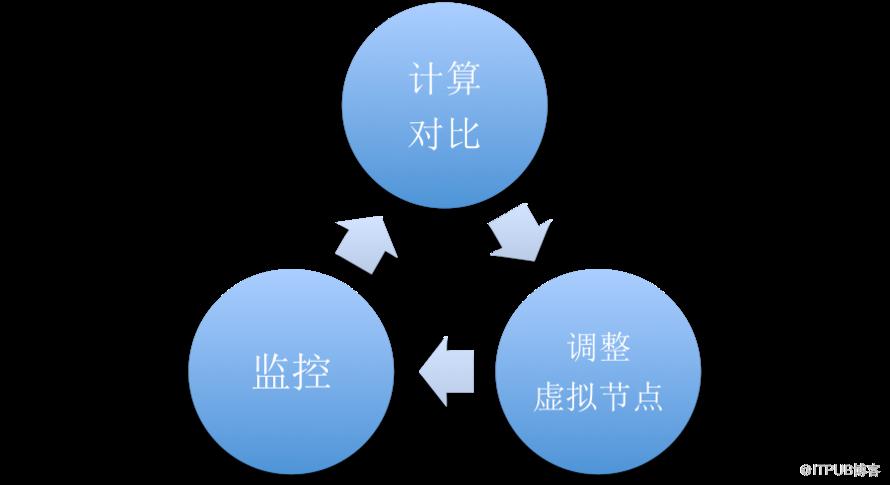
可以理解,使用一致性哈希的调度方式,力求的是Partition个数分布的尽量均衡,各Partition在调度中的权重是一样的,并不关心Partition其他指标(例如QPS和流量)的差异,且一致性哈希算法的映射关系我们无法干预和调节。 个性化一致性哈希的流量均衡 想要解决这个问题,我们需要引入流量信息参与Partition调度决策。通过在调度策略中引入流量反馈机制,调节一致性哈希虚拟节点个数,达到流量均衡。具体思路是,获得监控数据,对比节点的流量值与集群各节点流量均值。如果该节点流量值较大,则通过减少该节点的虚拟节点个数减少所serve的Partition个数;如果该节点流量值较小,则通过增多该节点的虚拟节点个数增多所serve的Partition个数,不断反馈。可以用下图表示。
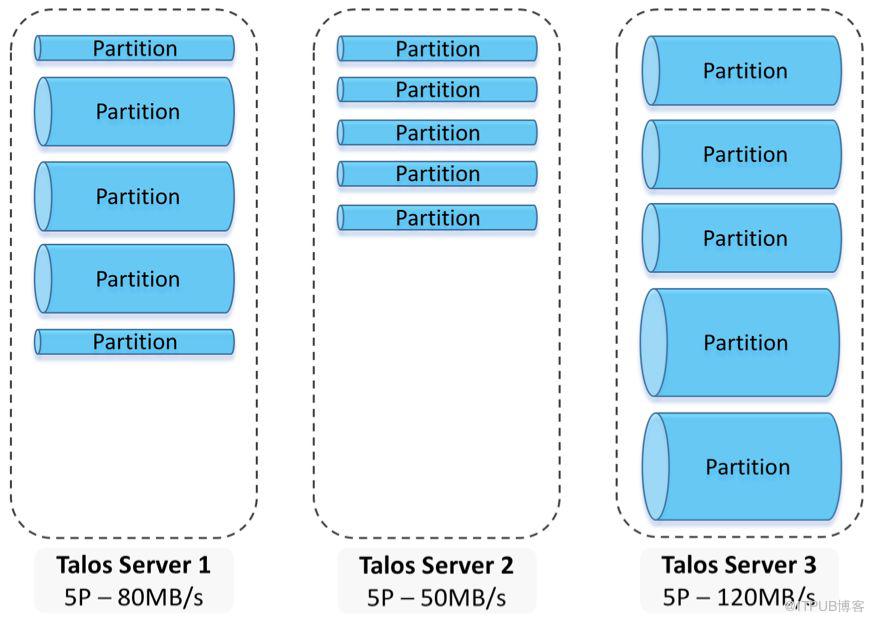
通过监控反馈和虚拟节点不断的调整,该方式最终可以找到符合各节点流量均衡分布的一致性哈希虚拟节点分布,下图简单解释下优化调度效果。优化前的调度:Partition个数大致均匀
优化后的调度:节点流量均匀
相比于引入一个中心节点来实现统一的定制的调度机制,这种方式对Talos原有架构来说改动较小,且不会引入复杂的中心节点可用性问题。 流量均衡在Talos中的实现 依据上述思想落地到Talos业务,需要考虑稳定性问题,分析影响稳定性的因素:
- 对Talos来说,Partition在节点间的迁移大约在7s左右可恢复服务。由于流量均衡过程中会产生Partition的迁移,如果短时间内大规模的Partition迁移,由于资源的集中调用,不仅会造成恢复时间增长,大规模的迁移还可能带来集群可用性抖动。
- 类似HDFS Balance,我们可以设定流量均衡的目标值,例如,设定目标值为10%,则目标是调整集群最大日均流量与最小日均流量在集群日均流量的10%范围内。有些情况下某些目标值我们是无法达到的,这时的调整最终就会变成来回震荡的状况。举个最简单的例子,A机器100M流量,B机器50M流量,单个Partition的流量值是50M,按照10%的目标去调整,结果就是会在A 50M and B 100M和A 100M and B 50M的情况之间来回震荡。不仅达不到目标,还白白带来迁移开销。
- 还有一些情况,会出现“往坏的方向调节”。依然以一个简单例子说明,A机器100M流量,B机器80M流量,调整目标10%,单个Partition的流量值是50M,一次调节后变成A 50M而B 130M,均衡度更差。2和3问题的出现,本质上都是由于我们调节的最小粒度是Partition。
为了避免这些问题,设定了以下机制:
- 通过监控数据模拟计算,模拟符合预期才触发调整。取得各Partition的流量监控数据,带入一致性哈希函数,模拟调整虚拟节点个数并计算各节点流量值;
- 控制每次迁移的Partition个数,保证集群整体稳定性;
- 计算方差决定是否调整,以防止无谓的震荡调整或往更坏的方向调整。方差能反应离散程度,只有当模拟调整后的方差变小才触发调整;
- 设定最大调节次数,以设定调整目标无法达到时的无限模拟计算。
最终的实现架构如下:
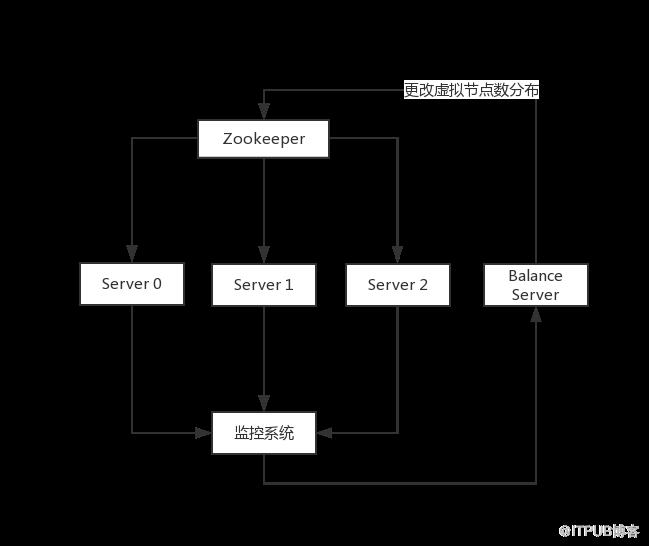
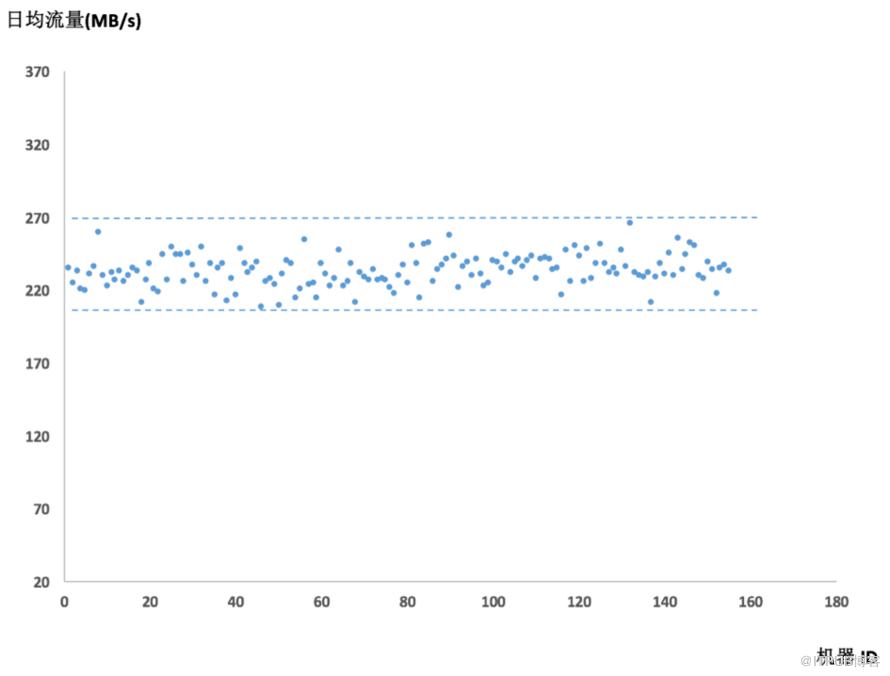
其中BalanceServer会负责完成根据阈值和监控值模拟计算,控制迁移量,按规定时间间隔触发等逻辑。集群的可用性不依赖BalanceServer,BalanceServer挂掉只是停止了集群的流量均衡调整,集群会继续按照当前的虚拟节点分布进行调度运行,即便出现了集群节点上下线也没关系。接下来展示下集群均衡的效果,依然以文章开头展示流量图的Talos集群为例,将调整后各节点的日流量均值制作成散点图,可以发现优化后各节点流量值明显聚合。经计算,此集群150台机器,可节省因网卡达到瓶颈而需要扩容的机器35台。
值得借鉴的是,通过改变BalanceServer引入的监控参数,此方法可以扩展到基于一致性哈希的分布式系统的QPS均衡、甚至CPU资源和内存资源均衡,只要找到本系统监控指标和均衡指标间的函数关系即可。后续Talos关键问题系列文章将持续更新,欢迎继续关注。