
在过去几年中,Apache Kafka 已成为流数据的领先标准。快进到今天:Kafka 已经无处不在,被至少 80% 的财富 100 强企业采用。这种广泛的采用归功于 Kafka 的架构,它远远超出了基本消息传递的范围。 Kafka 的架构多功能性使其特别适合在巨大的“互联网”规模上传输数据,确保容错性和数据一致性对于支持关键任务应用程序至关重要。
Flink 是一个高吞吐量、统一的批处理和流处理引擎,以其大规模处理连续数据流的能力而闻名。它与 Kafka 无缝集成,并为一次性语义提供强大支持,确保每个事件精确处理一次,即使在系统故障时也是如此。 Flink 作为 Kafka 的流处理器是自然的选择。虽然 Apache Flink 作为实时数据处理工具取得了巨大的成功和受欢迎,但获取足够的资源和当前示例来学习 Flink 可能具有挑战性。
在本文中,我将引导您逐步完成将 Kafka 2.13-3.7.0 与 Flink 1.18.1 集成的过程,以消费来自主题的数据并在单节点集群上的 Flink 中处理它。集群中操作系统已使用Ubuntu-22.04 LTS。
假设
- 系统至少配备 8 GB RAM 和 250 GB SSD 以及 Ubuntu-22.04.2 amd64 作为操作系统。
- OpenJDK 11 是通过
JAVA_HOME环境变量配置安装的。 - 系统上提供 Python 3 或 Python 2 以及 Perl 5。
- 单节点 Apache Kafka-3.7.0 集群已与 Apache Zookeeper -3.5.6 一起启动并运行。 (请阅读此处如何设置 Kafka 集群。)。
安装并启动 Flink 1.18.1
- 可以下载Flink-1.18.1的二进制发行版此处。
- 使用
$ tar -xzf flink-1.18.1-bin-scala_2.12.tgz 在终端上提取存档 flink-1.18.1-bin-scala_2.12.tgz。成功提取后,将创建目录flink-1.18.1。请确保其中的bin/、conf/和examples/目录可用。 - 通过终端进入
bin目录,执行$ ./bin/start-cluster.sh启动单节点Flink集群。
- 此外,我们还可以利用 Flink 的 Web UI 通过访问浏览器的 8081 端口来监控集群的状态和正在运行的作业。

- 可以通过执行
$ ./bin/stop-cluster.sh停止 Flink 集群。
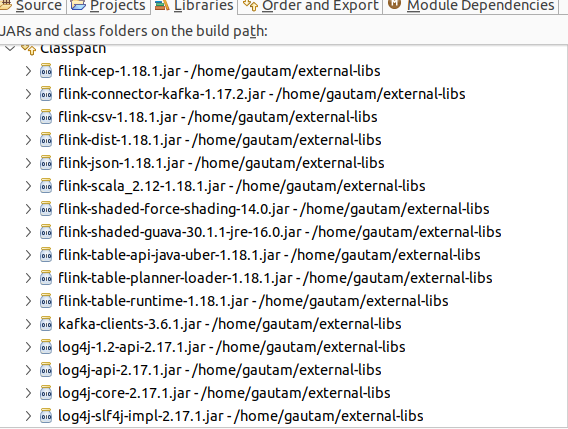
依赖 JAR 列表
以下 .jar 应包含在类路径/构建文件中:
我使用 Eclipse IDE 23-12 创建了一个基本的 Java 程序,以在 Flink 中持续使用来自 Kafka 主题的消息。使用 Kafka 的内置 kafka-console-publisher 脚本将虚拟字符串消息发布到主题。每条消息到达 Flink 引擎后,不会发生数据转换。相反,只是将一个附加字符串附加到每条消息并打印以进行验证,确保消息连续流式传输到 Flink。
整个执行过程已被屏幕记录。如果有兴趣,您可以在下面观看:<
我希望您喜欢阅读本文。请继续关注另一篇即将发布的文章,我将在其中解释如何将消息/数据从 Flink 流式传输到 Kafka 主题。





