
Pandas是一个python的开源库,它基于Numpy,提供了多种高性能且易于使用的数据结构。Pandas最初被用作金融数据分析工具而开发,由于它有着强大的功能,目前广泛应用于数据分析、机器学习以及量化投资等。下面来跟随作者一起认识下Pandas吧!
1 如何开始
Pandas安装方式十分简单,如果使用Anaconda,Anaconda默认就已经为我们安装好了Pandas,直接拿来用就可以了,推荐使用这种方式。
如果不用Anaconda,只需执行如下命令即可:
pip install pandas
像其他python库一样,使用之前需要导入,通常采用如下方式:
import pandas as pd
2 Pandas数据结构
Pandas的数据结构包括 Series、 DataFrame以及 Panel,这些数据结构基于 Numpy,因此效率很高。其中 DataFrame最为常用,是Pandas最主要的数据结构。所有Pandas数据结构都是值可变的,除 Series外都是大小(Size)可变的, Series大小不可变。
Series
Series是一维的类似的数组的对象,它包含一个数组的数据(任意NumPy的数据类型)和一个与数组关联的索引 。

可以看到Pandas默认为我们生成了索引,它的结构如下表所示:
| 0 | 1 | 2 | 3 |
|---|---|---|---|
| 0.102780 | 1.523001 | 1.770067 | 0.437553 |
我们也可以使用 index关键字为其指定索引:

DataFrame
DataFrame是二维的、类似表格的对象,是使用最为广泛的Pandas数据结构。DataFrame有行和列的索引,访问便捷。它可以被看作是Series的字典:
结构如下表所示
| name | gender | height | weight | |
|---|---|---|---|---|
| 0 | 张三 | M | 174 | 80 |
| 1 | 李四 | F | 160 | 48 |
| 2 | 王五 | M | 185 | 70 |
一方面,我们可以使用 columns关键字指定DataFrame列的顺序,DataFrame的列将会严格按照 columns所指定的顺序排列;另一方面,与Series相同,我们可以使用 index关键字为其指定索引:

需要注意的是,DataFrame的同一列允许有不同类型的值(数字,字符串,布尔等),这便意味着:我们可以将 王五的 weight设置为 F。
3 数据访问和遍历
DataFrame支持按下标访问:

也支持按索引访问:

因此,DataFrame也支持如下两种遍历方式:
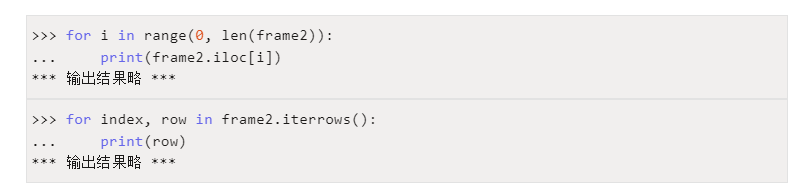
4 添加和删除列
如果我们想增加一列,也非常方便,如计算BMI指数:

仅需一行代码而无需遍历。
删除列:

5 添加和删除行
添加行

删除行

6 数据筛选
- 按下标取出前两条记录

- 按其他条件筛选
如找到BMI>20的记录:

DataFrame还支持许多其他的操作,篇幅有限,在此不一一展开。
7 Panel
Panel是三维的数据结构,可以看作是DataFrame的字典,这种数据结构使用很少,此处略过不提。
Pandas实战
学习技术是为了更好的工作和生活,抛开应用,技术也就失去了存在的意义。本文开篇中提到,Pandas作为数据分析工具的一个重要应用场景是量化投资,在此我想分享一下使用pandas的一个场景:
我想筛选出A股市场中过去60个交易日表现好的那些股票。关于表现好,也许每个人都有自己的看法,我的标准如下
- 涨幅够大,区间累计涨幅达60%以上
- 回撤小,区间内任意单个交易日跌幅不超过7%,包括高开低走7%(套人的不算好股票);区间内任意连续两个交易日累计跌幅不超过10%,包括连续两个交易日高开低走10%
我使用的数据源是TuShare,它提供了A股复权日线图,不过它没有提供复权数据的每日涨跌幅,所以我们需要对他进行处理:

此处使用了TALib,一个开源的金融数据分析工具。
完成初步的数据处理之后,我们就可以运行筛选条件了,截取代码片段如下:

最后的结果如下:
[('603986', '兆易创新'), ('603882', '金域医学'), ('603501', '韦尔股份'), ('300782', '卓胜微'), ('300622', '博士眼镜'), ('300502', '新易盛'), ('300492', '山鼎设计'), ('300433', '蓝思科技'), ('300223', '北京君正'), ('002917', '金奥博'), ('002892', '科力尔'), ('002876', '三利谱'), ('002850', '科达利'), ('002819', '东方中科'), ('002600', '领益智造'), ('002241', '歌尔股份'), ('000049', '德赛电池')]
可以看到其中科技股独领风骚,谁让我们大A是科技牛呢?