
为保障轨道交通安全,定期采用多种途径和方法对钢轨进行无损检测。确定铁路钢轨运行状况的主要方法之一是超声波无损检测。测试结果的评估取决于缺陷镜检查师。由于需要减少人类的工作量并提高超声波检测数据分析过程的效率,因此创建自动化系统的任务变得至关重要。这项工作的目的是评估创建一个有效的系统来通过超声波检查识别钢轨缺陷的可能性 使用机器学习方法的缺陷图。
域名分析
铁路轨道由通过螺栓和焊接接头连接在一起的钢轨部分组成。当配备有压电换能器(PZT)的探伤仪沿着铁路轨道通过时,超声波脉冲会以预定频率发射到钢轨中。然后接收 PZT 记录反射波。超声波方法的缺陷检测基于金属中不均匀性波的反射原理,因为裂纹(包括其他不均匀性)的声阻与金属其他部分不同。
A-Scan形成原理
图 1 显示了从螺栓孔反射的记录信号,探测脉冲垂直输入到轨道表面。这种信号的图像称为“振幅扫描”或缩写为“A 扫描”。< /p>
 图。图 1:在 A 扫描上显示已配准的超声波检测信号:a) 超声波发射和配准过程,b) 已配准信号。
图。图 1:在 A 扫描上显示已配准的超声波检测信号:a) 超声波发射和配准过程,b) 已配准信号。
沿轨道长度的每个 i 坐标处记录的此类回波信号的幅度可以表示为矢量。 Ai = [a1, a2, a< sub>3, … , a j ],其中 aj >- 是铁轨第 j 深度处反射信号的幅度。每个幅度值的深度aj是根据注册时间和发射信号的频率计算的。
B 扫描形成原理
沿着轨道长度的每个i个检查点记录的A扫描回波信号可以表示为二维阵列。 B = [A1, A2, A strong>3, … , Ai] 大小 (i x j)。图 2 示意性地显示了阵列 B 的片段,其中记录了从螺栓孔反射的回波信号,探测脉冲垂直输入到铁轨表面。

图。图2:带有螺栓孔信号和底部信号的阵列片段。
以强度图形式表示的二维数组 B 称为“亮扫描”(“B 扫描”),如图 3 所示,而数组的值则以三维形式显示在使用颜色作为数据沿 Z 轴的第三个维度的平面。

图。图3:通过将探测脉冲垂直输入到钢轨表面(Avikon-11 设备)进行扫描而获得的螺栓孔 B 扫描片段。
缺陷图的形成
缺陷的不同反射特性、它们的几何形状以及它们在轨道中的位置需要使用具有不同输入角度和记录角度的超声波换能器来进行检测。因此,现代钢轨探伤仪使用沿探伤仪搜索系统的长度分布的多个传感器,并形成所谓的钢轨断面探测方案。其中一种应用的检测方案如图 4 所示,其中每个超声波输入角度的产生和记录换能器位于同一外壳中。
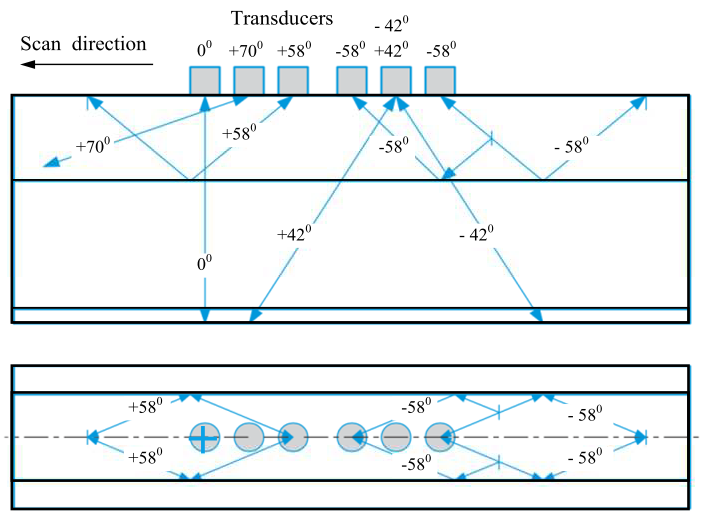 图。图 4:使用六个传感器向轨道发射超声波脉冲的方案示例
图。图 4:使用六个传感器向轨道发射超声波脉冲的方案示例
使用中心输入角为“+420”(橙色)、“- 420”的传感器形成螺栓孔的 B 扫描信号(沿轨道长度的三个特征点(1、2、3 位置)处的“00”(蓝色)和“00”(绿色)如图 5a 所示。
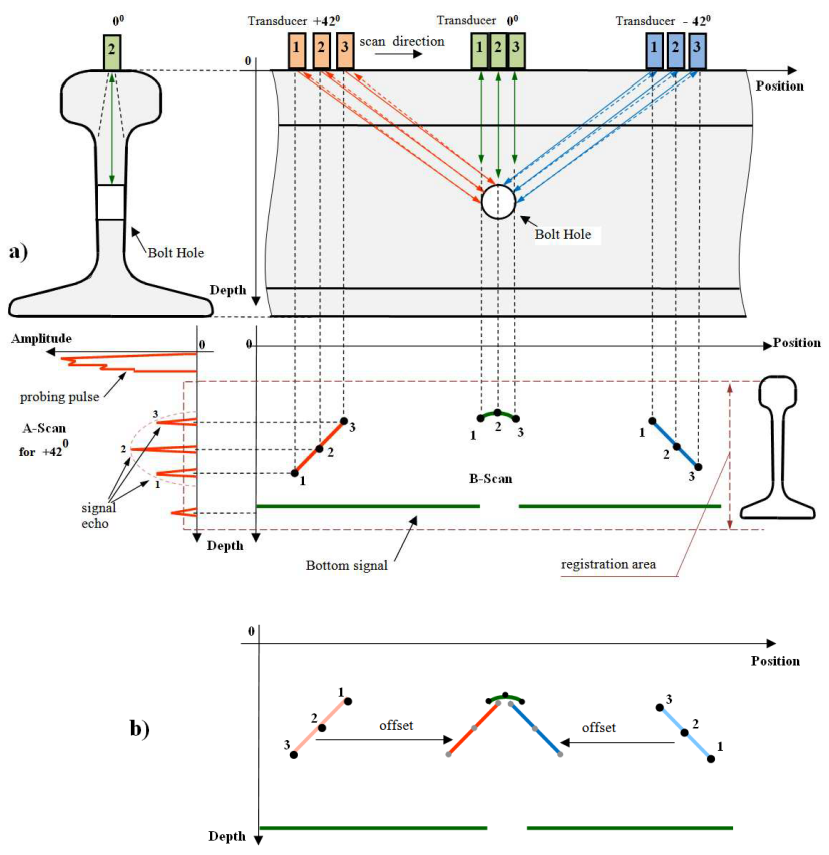 图。 5:扫描过程中的信号形成:a) 总体视图 b) 偏移校正。
图。 5:扫描过程中的信号形成:a) 总体视图 b) 偏移校正。
探伤仪的信息通道对应于依次排列在钢轨表面的物理传感器(传感器)。每根钢轨探伤仪所有通道的 B 扫描集组合成一个数据文件,称为缺陷图(扫描)。通常,选择考虑的一个通道或一组通道也称为缺陷图。
在大多数情况下,为了改善缺陷图的感知,它以缩小为单个部分的方式显示,其中通过额外考虑超声倾斜输入的通道的回波信号的坐标来校正考虑反射器从探测脉冲输入点到轨道金属的距离(图 5b)。此外,为了便于使用并减少整个缺陷图的图形外观,对数据通道进行了图形分组,其中之一如图 6 所示。

图。图 6:用超声波设备 Avicon-11 扫描获得的螺栓钢轨接头缺陷图的一部分示例。
解码缺陷图(信息特征)
为了在 B 扫描和 A 扫描上直观地搜索缺陷,需要使用受吸引的专家(探伤仪)的认知功能。当对钢轨进行超声波扫描时,其结构元素和缺陷会产生声学响应,并以特征图形图像的形式显示在缺陷图上。在数据分析过程中,专家可以通过视觉区分缺陷图上的每种类型的缺陷。缺陷图分析的主要目标是在可能的干扰和结构元素图像的背景下可靠地找到并突出显示缺陷的图形图像。
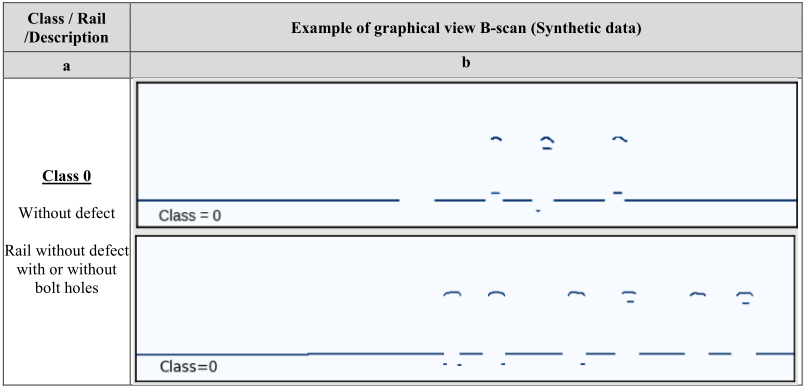
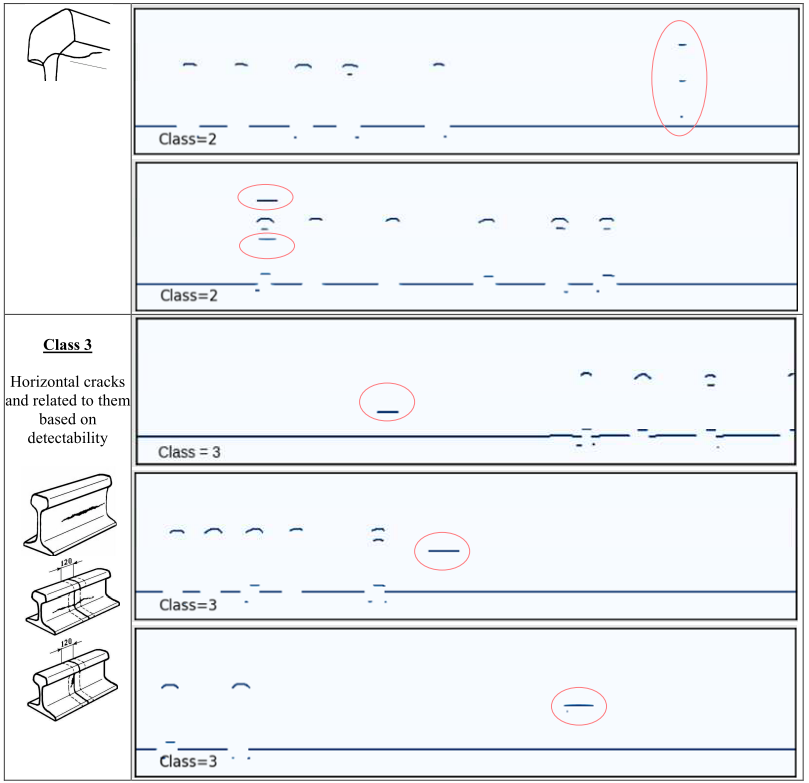
缺陷图的每个测量通道 00、±420、±580、+700 > 或它们的组合旨在检测一组特定的缺陷。为了简化搜索缺陷的任务,我们将分解问题并考虑深度学习算法使用 Avicon-11 通道“00”的缺陷图搜索各种类型缺陷区域的能力探伤仪。在这种情况下,可以根据特征信息特征将站点类型分为四类。从表 1 可以看出 Avicon-11 探伤仪获得的数据集的多样性。
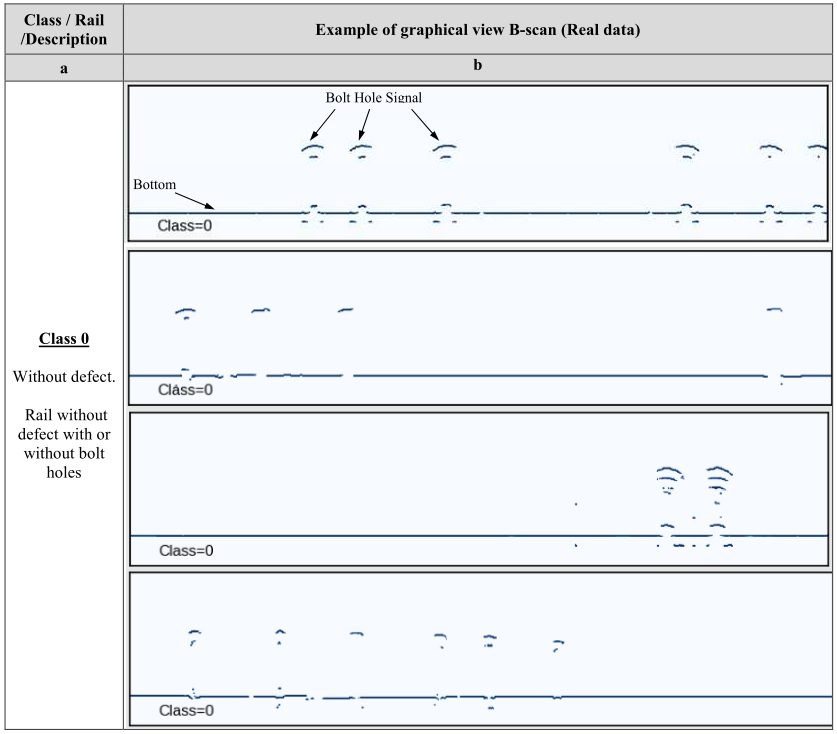


表 1:所选类(真实数据)的实例(B 扫描)示例
分类算法的选择和实现
尽管在铁路轨道的运营中,缺陷的存在与否(二元分类)具有决定性,但我们会定量评估哪些缺陷区域有较高的概率被误分类为无缺陷,从而这是铁路诊断中的一个危险案例。在这项工作中,分类任务被简化为明确的多重任务包含四个班级的班级任务。
数据集生成
数据集是从以下获得的缺陷图中收集的Avicon-11 探伤仪在各种条件下在多个铁路测试轨道 (RTT) 和传统轨道上运行。每个数据实例都表示为矩形“深度 × 长”数据,形状为 (224, 1024),这允许您在螺栓连接处沿轨道长度拟合六个以上螺栓孔的图像。
由于缺乏足够数量的缺陷区域,数据集的形成很困难,因此为了扩展它,我们使用了沿钢轨长度的位移,并在不同条件和测试设备下扫描相同的缺陷设置,这使我们能够获得不同的缺陷图像(图7)。
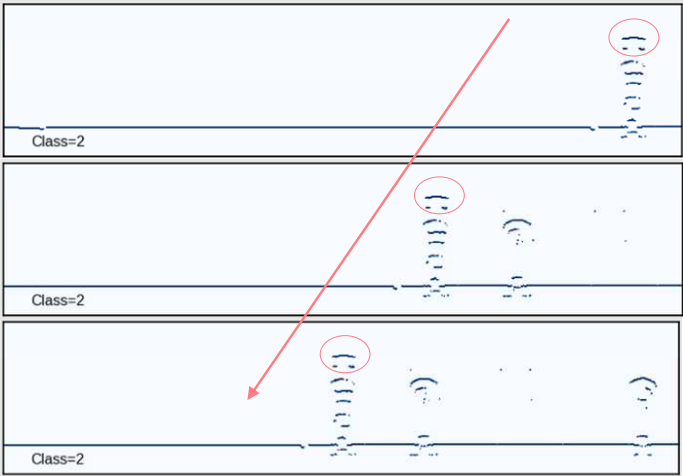
图。 7:数据集扩展示例
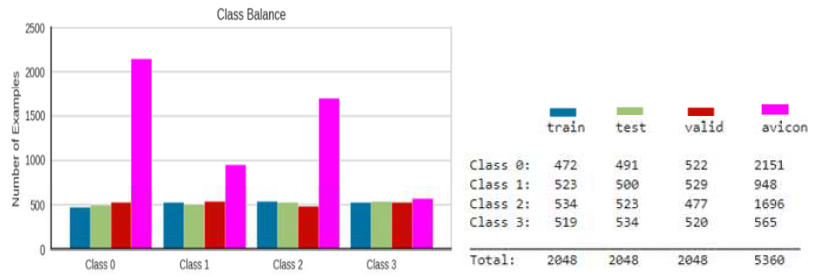
根据指定的方法,类别 0、1、2 和 3 的数据集分别为 2151、1043、1584 和 582,总共 5360 个实例。无缺陷类“0”包含 10%(214 个实例)没有螺栓孔的实例,其余 90%(1937 个实例)包含 1 到 6 个螺栓孔。该数据集名为“avicon”,仅用于最终测试。这使我们能够避免训练过程中类别不平衡的问题,并获得对分类器准确性的更可靠的评估。
为了在这项工作中训练和测试分类模型,使用了一个综合的、平衡的数据集,该数据集是在描述超声波从钢轨和缺陷的结构反射器的反射和记录过程的模型的数学建模的基础上获得的。图 8 展示了这种训练模型在轨道诊断过程中对探伤仪获得的实际数据进行分类的应用。
图。 8:基于模型数据训练的神经网络的应用
表 2 中列出了所选类的合成实例的示例。有关生成合成数据集的更多信息,请参阅作品 [1-4]。
建模过程使我们能够获得大量的实例;我们将每个合成集“训练”、“有效”、“测试”的工作限制为 2048 个实例。
根据图 9,每个数据集和标签的每个实例都写入相应的二进制文件 images.bin 和 labels.bin(数据类型 «uint8»)中。

图。 9:按目录分布集
探索性数据分析
有关数据量、合成集的类别平衡和 «avicon» 集的信息如图 10 所示。
对真实数据帧的图形表示的分析使我们能够识别 3 类缺陷的至少一个重要属性:缺陷图像与螺栓孔图像最难区分,尤其是当它们位于同一位置时level 作为铁路深度,这使得分类任务变得非常复杂。
每个数据实例的大小为 224 x 1024,这对于机器学习 (ML) 算法的应用来说足够大,但也给组织训练过程带来了困难。每个这样的实例都可以被视为 224*1024 = 229376 维空间中的数据点,该空间是高度稀疏的,因为它包含大量零。作为 PCA 方法的组件数量函数的“train”集合的积分可解释离散度的构造图(图 11)表明,当使用 1000 个组件(比原始大小小 330 倍)时,已经有 98.5%解释了分散性,这表明原始数据中存在高度冗余。这样的缩减数据集可以用于 ML 算法,但同时在整个数据集上获取它会带来困难;因此,在进一步的工作中,考虑了基于深度学习的算法。

图。图 11:数据的积分可解释离散度图,作为“训练”数据集的 PCA 方法的组件数量的函数
神经网络架构
在这项工作中,考虑了线性堆叠层形式的深度学习模型(图 12a:网络的最终版本)。激活函数:relu(修正线性单元),对于输出全连接层——归一化指数softmax函数,所有输出神经元的值之和等于1。损失函数:以实际数据的概率分布与其预测(交叉熵)之间的距离的形式衡量误差。优化器:RMSProp 中的随机梯度下降算法的修改。训练过程中的指标:准确率,等于正确分类的对象数量与对象总数的比率。
网络培训
网络的最终版本经过了 50 个 epoch 的训练。表征训练过程的质量指标“loss”和“accuracy”的变化图(图12b)在训练和验证阶段收敛,并分别具有低值和高值,这可能表明不存在过度拟合效应模型的。模型在“训练”集上获得的预测精度为 99.61%,在“测试”集上获得的预测精度为 99.02%,这也证实了这一事实(图 12b、c)。 H5格式的网络占用内存为30KB。完整的代码可以在 GitHub 存储库中的链接 [5] 中找到。
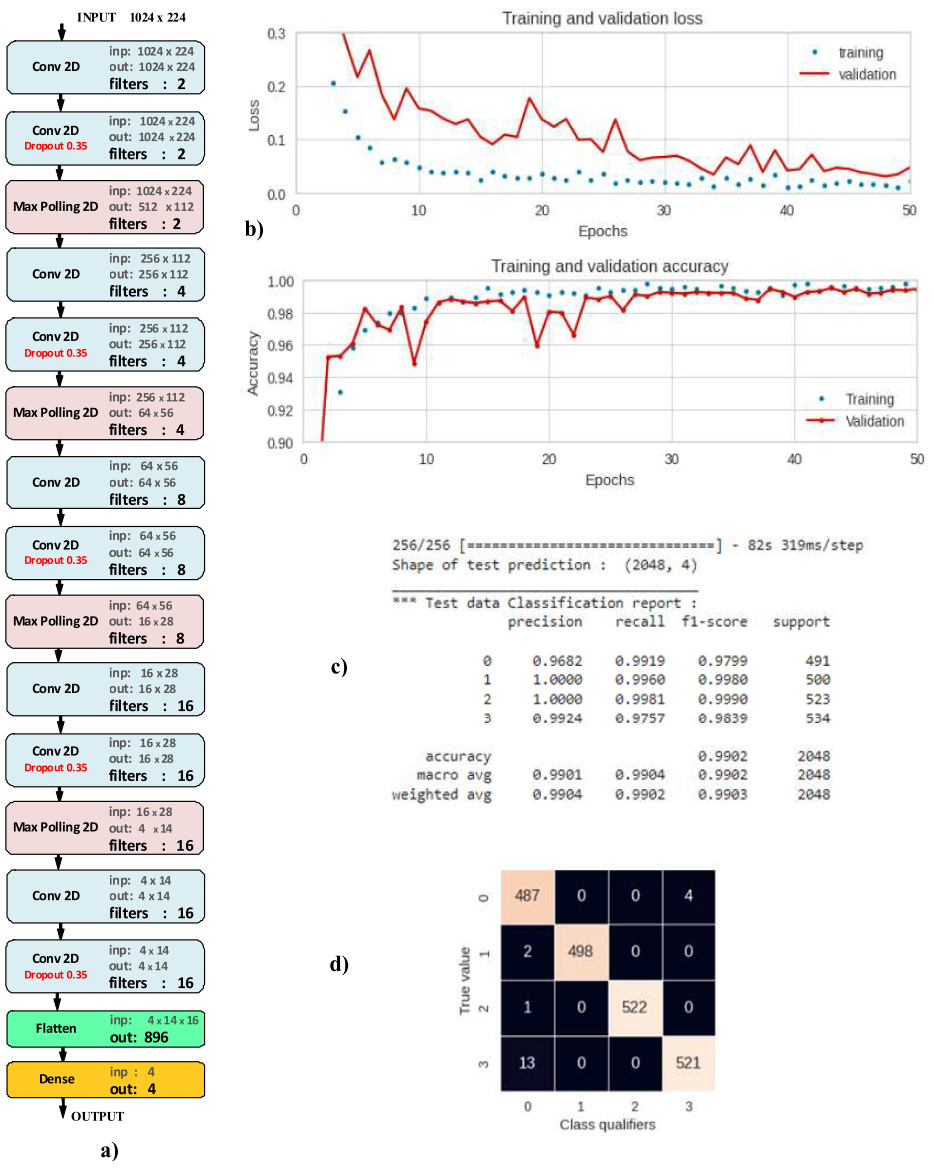
图。 12:NN及其训练结果:a)网络架构; b) 训练过程中“Loss”和“Accuracy”的变化; c) 分类报告; d) 混淆矩阵
混淆矩阵和分类报告如图 12d、c 所示。训练后的模型对于所有类别分类器均具有较高的准确率和召回率均在 96% 以上,这也意味着数据中有足够的信息特征用于分类。
考虑错误分类的样本对于理解分类器的操作及其变化非常重要。根据混淆矩阵,第 3 类分类器错误地识别了 4 个第 0 类样本,这些样本具有至少一个与第 3 组缺陷图像相似的螺栓孔信号(示例如图 13a 所示),这可能是导致错误的原因。
0 类分类器错误地识别了 1 类的两个样本。两个错误识别的缺陷都具有特征外观,并且位置非常接近数据框的上边界。其中一个帧如图 13b 所示。
0 类分类器错误地识别了 2 类的一个样本,该样本的位置足够接近螺栓孔的深度(图 13c)。
0 类分类器错误地识别了 3 类的 13 个样本,这些样本的位置足够接近螺栓孔的深度(图 13d)。
网络测试的结果表明区分 3 类缺陷和螺栓孔的难度。
 图。 13:错误分类数据的特征框
图。 13:错误分类数据的特征框
使用真实数据评估网络效率(«Avicon»)
评估经过训练的神经网络的工作质量 为了识别 Avicon-11 探伤仪获得的真实数据实例,在 avicon 数据集上进行了建模。整个网络的准确率为90%,比合成数据的预测准确率低9%。由此产生的混淆矩阵和模型质量的总结报告如图 14 所示。通过对标记数据进行分类所需的时间,可以估计对 100 公里铁路线进行分类所需的时间 — 11 秒。
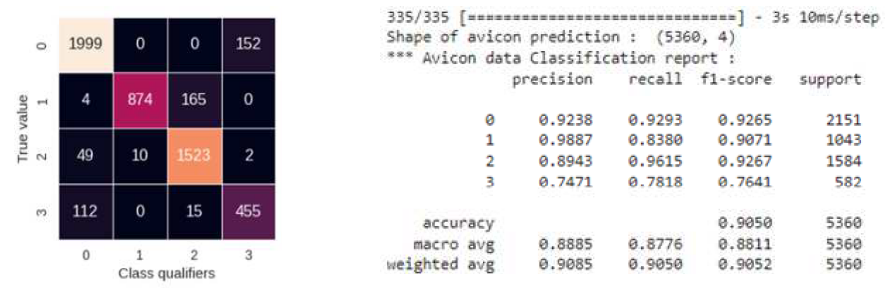
图。 14:基于《avicon》数据集分类的模型质量总结报告
我们将分析最重要的数据分类错误。根据混淆矩阵(图 14),通道“00”记录的响应最弱且属于 1 类的 4 条横向裂纹被归类为 0 类(无缺陷)。为了提高对此类缺陷的识别能力,需要添加额外的信息特征,这些信息特征可以从探伤仪的倾斜通道中获得,这些通道是检测此类缺陷的主要通道(图15)。
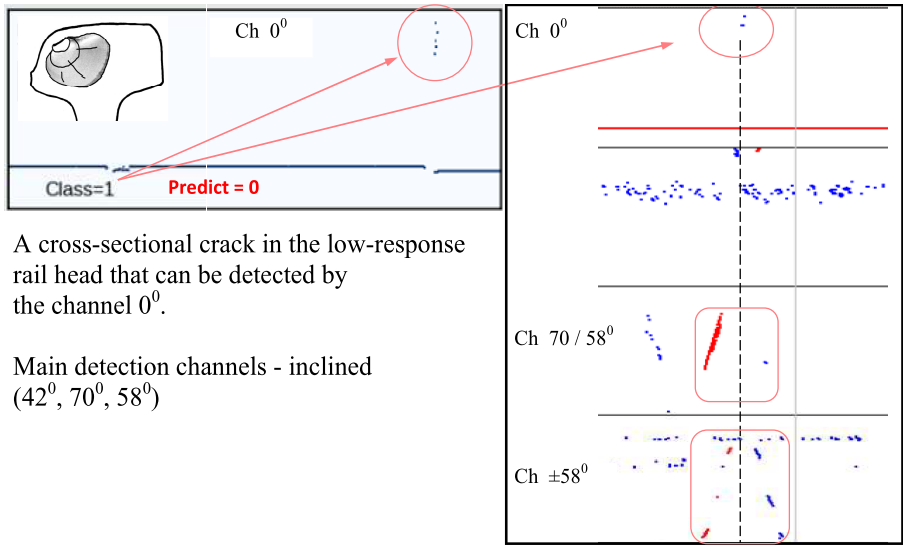
图。 15:错误分类数据的典型帧(True = 1,Predict = 0))
将 49 个 2 类缺陷错误分类为非缺陷与测量通道 «00» 记录的微弱信号响应有关。改进此类 2 类样本分类的一种方法是考虑来自倾斜通道 (Ch ±420) 的附加信息特征,因为它们是检测错误分类缺陷的主要通道(图 16) )。

图。 16:典型的2类误分类数据框(True = 2,Predict = 0)
将 112 个 3 类样本错误分类为 0 类与缺陷图像所在的数据帧相关:
- 位于螺栓孔的水平
- 位于更靠近数据框边缘的位置
- 具有与螺栓孔类似的图案
将 152 个 0 类样本错误分类为 3 类样本是由于类似的原因——螺栓孔图案与 3 类缺陷图案相似。
改进 0 类和 3 类样本分类的方法之一是考虑倾斜通道 (Ch ±420) 的附加信息符号,因为在这种情况下,螺栓孔很好与 3 类缺陷区分开来,反之亦然(图 17)。
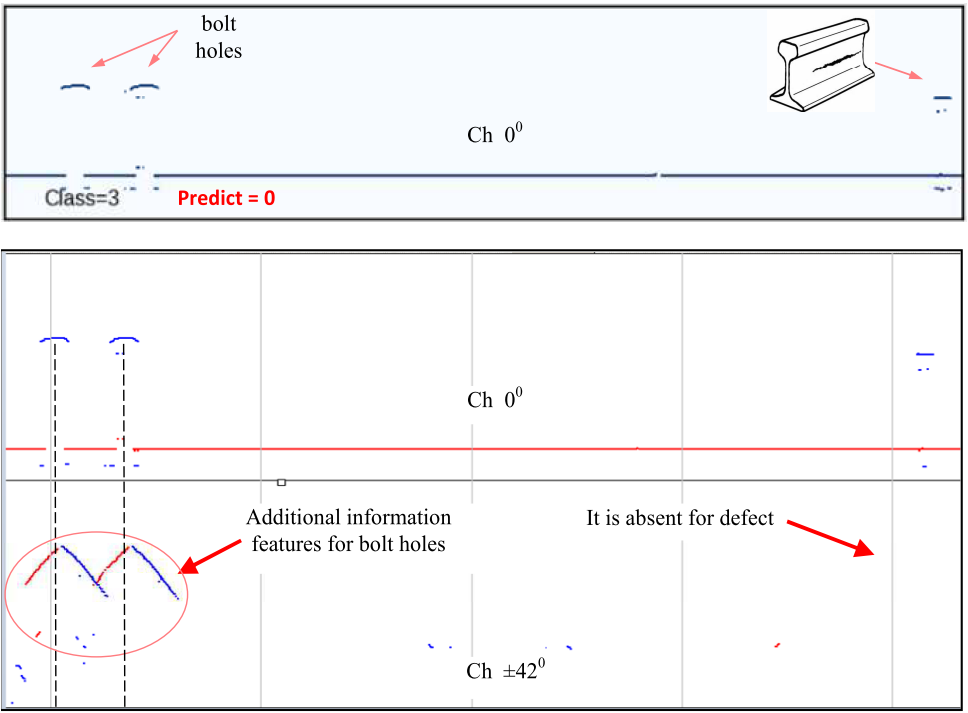
图。 17:典型的 3 类错误分类数据框(True = 3,Predict = 0)
1 类和 2 类缺陷的图形图像相似,将缺陷分配给 1 类或 2 类取决于缺陷图像开始记录在缺陷图上的深度。 1 类缺陷位于钢轨头部。 2 类缺陷可以从钢轨头部到颈部的过渡区域开始记录。将 165 个 1 类缺陷错误分类为 2 类缺陷很可能与钢轨头部记录的弱缺陷响应有关(图 18)。
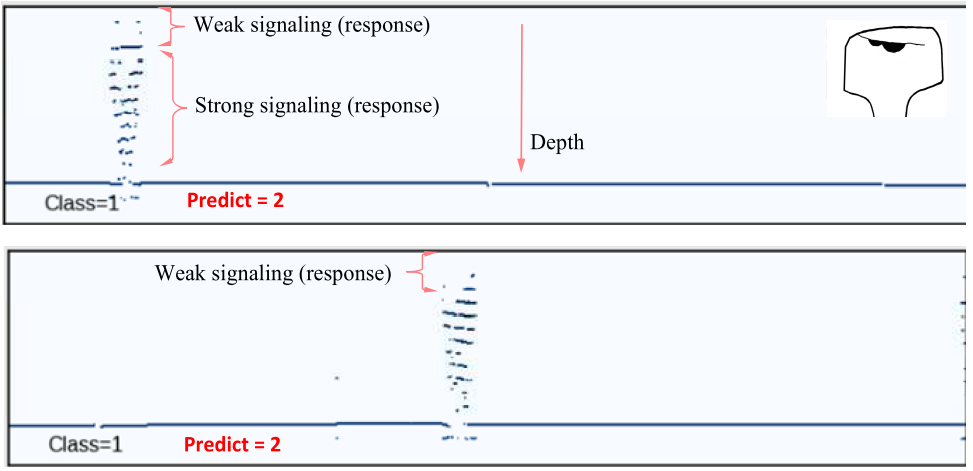
图。图 18:1 类典型误分类数据帧(True =1,Predict = 2)
二元分类器
所获得的分类器在实际使用中的重要任务之一是准确定义无缺陷类别(0 类),这将允许排除将缺陷样本错误分配给无缺陷样本的情况。通过改变概率截止阈值可以减少 0 类分类器的误报数量。为了评估适用的截止阈值水平,通过隔离无缺陷状态和所有缺陷状态对多类任务进行二值化,这对应于“一个与其余”策略(One vs Rest)。默认情况下,对于二元分类,阈值为 0.5 (50%)。采用这种方法,二元分类器的准确率达到 92.28%(图 19)。
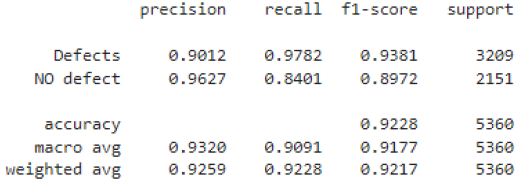
图。 19:截止阈值为 0.5 的二元分类器的定性指标(《avicon》集)
二元分类器的精度和召回率的变化取决于阈值的变化,显示在“精度-召回率曲线”图中(图 20a)。阈值为0.5时,误报值为161个样本(图20b)。将阈值增加到 0.8 和 0.9 可以将假阳性数量分别减少到 70 和 58,因为假阴性增加到 344 和 440(图 20b)。
可以说,在自动分析中,提高阈值,一方面可以减少将缺陷误分配到无缺陷状态,从而降低漏检缺陷的风险。另一方面,增加了人工对已知缺陷的车架进行分析时的劳动强度。

图。图20:截止阈值对二元分类器特性的影响:a)精确召回曲线,b)不同截止阈值下的混淆矩阵。
5。结论
- 基于对钢轨超声波检测主题领域的分析,识别出缺陷的信息迹象,使我们能够识别四类钢轨截面,并使用机器学习方法进行分类.
- 收集并标注了超声波钢轨检测数据集,包含 5360 个实例。
- 基于模型的随机数学建模创建了综合训练、测试和验证数据集,这些模型描述了超声波从钢轨和缺陷的结构反射器反射和记录的过程。
- 为了解决明确的多类分类问题,训练了基于卷积模型的神经网络结构,总体准确率达到 99%。
- 使用模型数据训练的神经网络来识别真实铁路缺陷图像的有效性已得到证实。
- 仅使用超声波探伤仪零通道的缺陷图部分即可估计可达到 90% 的分类精度。
- 我们已经对神经网络误差的原因进行了分析,并表明需要使用探伤仪倾斜通道缺陷图中的附加信息特征。
参考文献
- Kaliuzhnyi A. 应用模型数据训练超声波诊断中铁路螺栓孔缺陷分类器。人工智能进化[互联网]。 2023年4月14日[引用2023年7月28日];4(1):55-69。
- Kaliuzhnyi A. 应用机器学习方法搜索铁路缺陷(第 2 部分< /a>)
- Kaliuzhnyi A. 使用机器学习检测铁路缺陷。
- NVIDIA 博客。 什么是合成数据?
- GitHub 存储库