
Apache Zepelin 0.9附带了重新设计的 Apache Flink 解释器,允许开发人员和数据工程师直接在齐柏林笔记本上使用 Flink 进行交互式数据分析。在接下来的段落中,我们将介绍为什么流式 ETL 非常适合像 Apache Flink这样的流处理框架,通过演示开发人员如何在齐柏林的 Flink 上运行流式 ETL 数据管道的教程,我们深入了解了 Zepelin 笔记本中的 Flink 解释器。

流 ETL 和 Apache 闪烁
提取转换-加载 (ETL) 是一种与在存储系统之间按摩和移动数据相关的常见操作。ETL 作业历来定期触发,经常将数据从事务数据库系统复制到分析数据库或数据仓库。
流式处理 ETL 管道具有类似用途的传统 ETL:它们转换和丰富数据,并可以将其从一个存储系统移动到另一个存储系统。但是,流式处理 ETL 管道不同于传统的 ETL,因为它们能够持续运行,并且能够从源中读取连续生成数据的记录,以及以低延迟将数据移动到所需的目标。
流式处理 ETL是Apache Flink 的常见用例,因为它能够使用 Flink SQL(或表 API) 处理最常见的数据转换或扩充任务,并且能够支持用户定义的函数。此外,Flink 为各种存储系统(如卡夫卡、Kinesis、弹性搜索和 JDBC数据库系统)提供了一组丰富的连接器Kafka现在,让我们描述一下 Flink 解释器在齐柏林笔记本中的工作方式。
齐柏林 0.9 中的 Flink 解释器
Flink解释器可以从齐柏林的解释器设置页面访问和配置。解释器已重构,以便 Flink 用户现在可以利用 Zepelin 以三种语言编写 Flink 应用程序,即 Scala、Python (PyFlink) 和 SQL(用于批处理和流式处理)。Zepelin 0.9 现在配备了 Flink 口译员组,由以下五名口译员组成:
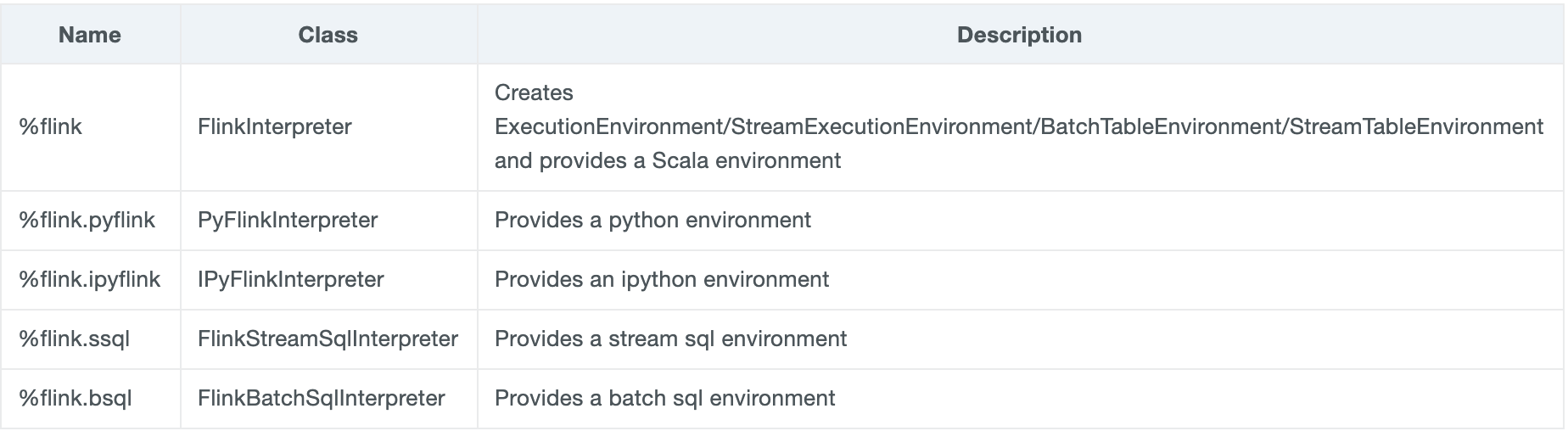
Flink 解释器已被带到一个新的水平,现在为以三种语言(Scala、Python [PyFlink] 和 SQL)编写 Flink 应用程序以及在不同的执行模式下运行此类应用程序(例如在本地、远程或纱线模式下运行 Flink)提供支持。如果您有兴趣了解有关 Flink 解释器的信息,以及有关如何开始使用 Zepelin 和 Flink 应用程序的所有执行模式的信息,可以查看本文。
在 Zepelin 上闪烁流 Etl 管道
Flink 解释器允许开发人员直接在 Zepelin 笔记本上构建流处理 Flink 应用程序,例如流式处理 ETL 和实时数据分析。这可以通过利用 Flink SQL 以及特定的 UDF(用户定义的函数)轻松执行。现在让我们展示一下如何使用齐柏林的 Flink 执行流 Etl:
您可以使用 Flink SQL 执行流式 ETL,按照以下步骤操作(有关完整教程,请参阅齐柏林网站的 Flink 教程/流式处理 ETL教程):
-
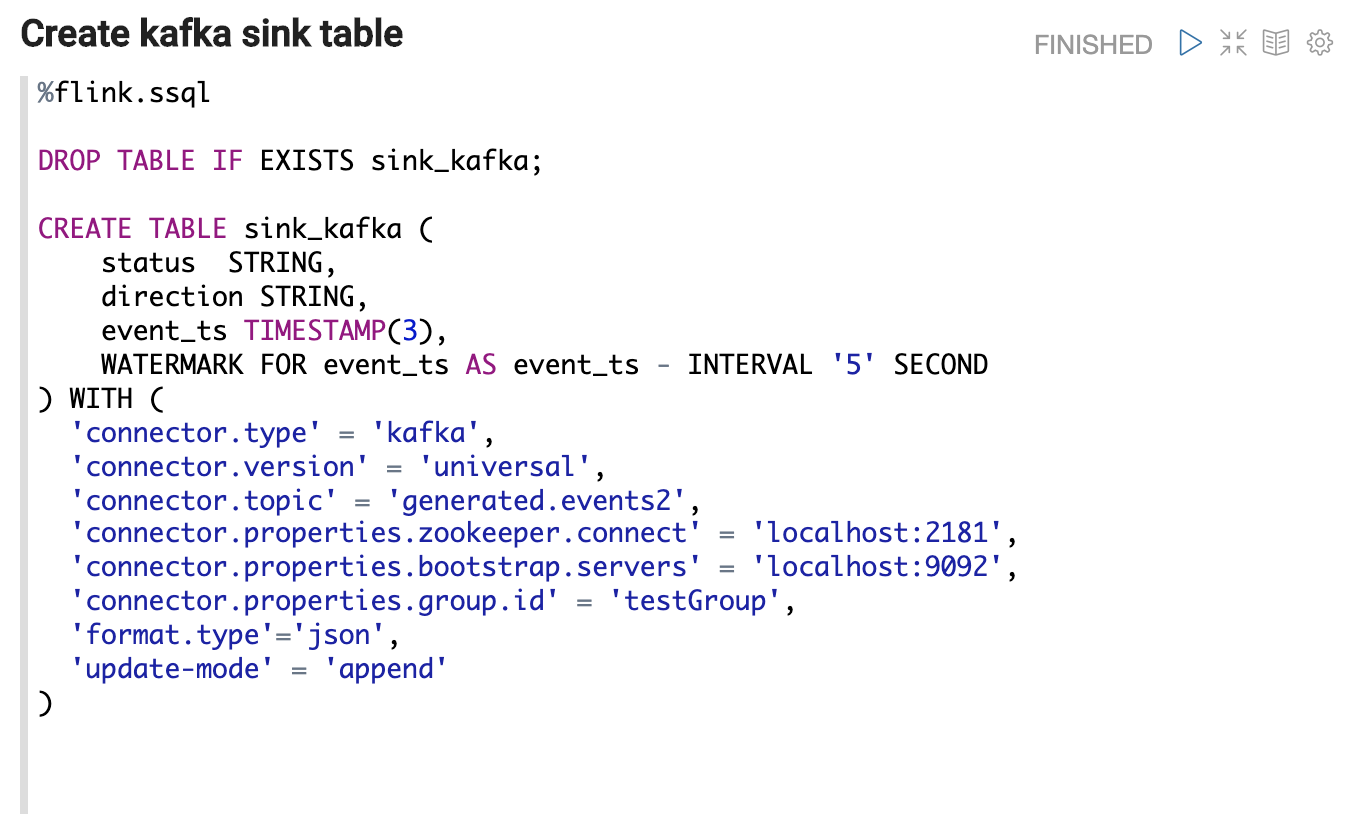
创建源表来表示源数据。
我们将使用%flink.ssql来表示以下 SQL 是流 SQL,这将通过StreamTableEnvironment

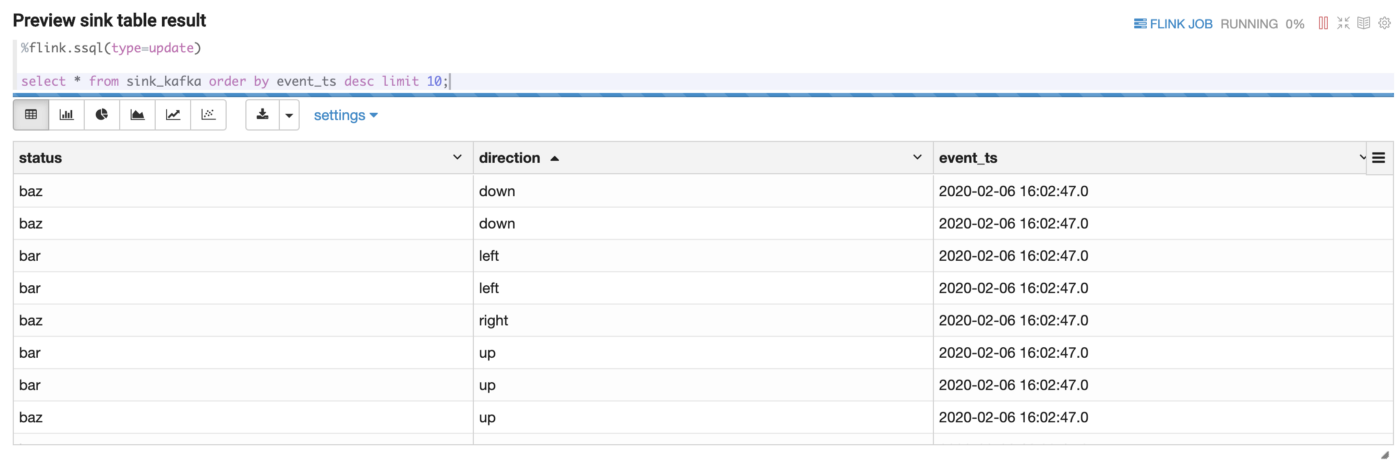
在这里,您可以看到每 3 秒刷新的 10 条前 10 条记录。
本文讨论了重新设计的 Flink 解释器在 Zepelin 0.9.0 中的工作方式,并提供了有关如何使用 Flink 和 Zepelin 执行流式 ETL 作业的一些分步指导com/@zjffdu/flink-on-ze-2-batch-711731df5ad9″rel=”nofollow”目标=”_blank”=教程, 如使用齐柏林上的Flink进行批处理,并在齐柏林的Flink上执行更高级的操作(例如资源隔离advanced operations、作业并发和并行、多个 Hadoop & Hive 环境等)我们希望您喜欢这个新的加入齐柏林项目,你尝试Flink解释很快!




