
就在几年前,RN及其门控变体(增加了乘法交互和机制,用于更好的梯度转移)是 NLP 最常用的体系结构。
著名的研究人员,如安德烈·卡帕西,对RNN的不合理有效性大加评论,大公司热衷于采用这些模型,将它们放入虚拟代理和其他NLP应用。
现在,变形金刚(BERT,GPT-2)已经出现,社区甚至很少提到经常性网络。
在本文中,我们将对 NLP 中的深度学习进行高级介绍;我们将简要地解释 RNN 和变压器的工作原理,以及后者的哪些特定属性使其在适用于各种 NLP 任务的更好体系结构中。
来吧!
让我们从RNN开始,为什么直到最近,它们被认为是特别的。
循环神经网络是具有很酷属性(循环机制)的神经体系结构系列,这使得它们成为处理可变长度序列数据的自然选择。与标准 N 不同,RN 可以挂起以前图层中的信息,同时接受新的输入。
下面是它的工作原理
假设我们正在构建一个电子商务聊天机器人,该机器人由处理文本的 RNN 和预测其背后的意图的转发网络组成。机器人收到此消息:”嗨!你们有这件衬衫在任何特定的颜色吗?
作为我们的输入,我们有11个单词(11个单词嵌入)和序列,切成代币,看起来像这个I1,I2….I11.
RNN 背后的核心思想是,它将相同的权重矩阵应用于每个输入,并生成一系列隐藏状态(其中将和我们有输入一样多),这些状态包含以前时间步长中的信息。
每个隐藏状态 (Ht) 基于以前的隐藏状态 (Ht-1) 和当前输入 (It) 计算;正如我们已经提到的,它们实际上是每个时间步长不断修改的状态。
因此,处理从第一个单词嵌入(I1) 开始,随着初始隐藏状态 (H0);在RNN的第一个单元内,在I1和H0上执行线性变换,添加偏置,最终值通过某种非线性(sigmoid、ReLU等)进行,这就是我们获得H1的方式。
之后,模型吃I2与H1配对,并执行相同的计算,然后I3与H2进入,其次是I4与H3,等等,直到我们处理整个序列。
由于我们一再使用相同的权重矩阵,因此 RNN 可以处理冗长的序列,而不是增加大小本身。另一个优点是,从理论上讲,每个时间步骤都可以访问许多步骤之前的数据。
问题
RNN的独特特征——它多次使用相同的层——也是它极易受到消失和爆炸梯度影响的原因。实际上,这些网络很难通过许多步骤来保存数据每次处理新输入时,模型都会更改隐藏状态,尽管隐藏状态可能微不足道。因此,当网络到达序列末尾时,来自早期层的数据可能会完全被冲掉。
这意味着,在我们的示例中”嗨!你们有这种衬衫有任何不同颜色吗?
另一个固有的缺点是顺序处理的性质:由于部分输入一次处理一个(除非我们有 H1,否则我们无法计算 H2),因此网络的计算总体上非常缓慢。
门控变体
为了解决上述问题,提出了不同的架构修改,以改善RN,最流行的是长期短期记忆(LSTM)和门禁循环单元(GTU)。
LSTM 背后的主要思想,粗略地说,是在每个单元内除了隐藏状态之外,每个单元内都有一个单元状态(它们都是相同大小的矢量)。
此外,这些模型有三个门(忘记门、输入门、输出门),用于确定从单元格状态写入、读取或擦除哪些信息。
所有门都是与隐藏状态长度相同的矢量,它们正是它们所针对的:
- 忘记门决定应该保留什么,以及应该从上一个时间步长中擦除什么。
- 输入门确定应允许哪些新信息进入单元格状态。
- 输出门确定应将单元格中哪些数据合并到隐藏状态中。
它们都是使用 sigmoid 函数计算的,因此它们始终输出值介于 0 和 1 之间。
如果门产生的东西接近 1,则认为它是打开的(数据可以包含在单元格状态中),如果发出的值接近 0,则信息将被忽略。
GRUs 的工作方式与 LSTM 类似,但在体系结构中更简单;它们消除单元格状态,并在隐藏状态之前计算两个门,而不是三个门。
GRUs 的要点是保持 LStM 的强大功能(在减少消失梯度方面),并消除其复杂性。GRU 的大门是:
更新门确定应修改隐藏状态的哪些部分,以及应保留哪些部分。从某种意义上说,它执行在 LSTM 中输入和忘记门的作用。
重置门现在确定隐藏状态的哪些部分。如果它输出的数字接近 1,我们可以复制以前的状态,并免除网络不必更新权重(没有权重调整 – 没有消失的渐变。
LSTM 和 GRUs 都能够控制信息流、掌握远程依赖关系,并根据输入的不同强度使错误消息流。
序列到序列 (seq2seq) 模型和注意机制
序列序列模型曾经在神经机器翻译 (NMT) 领域如此流行,由两个 RNN (一个编码器和一个解码器 ) 堆叠在一起。
编码器按顺序处理输入,并生成一个思想载体,用于保存每个时间步长的数据。然后,其输出传递给解码器,该解码器使用该上下文来预测适当的目标序列(翻译、聊天机器人的答复等)。
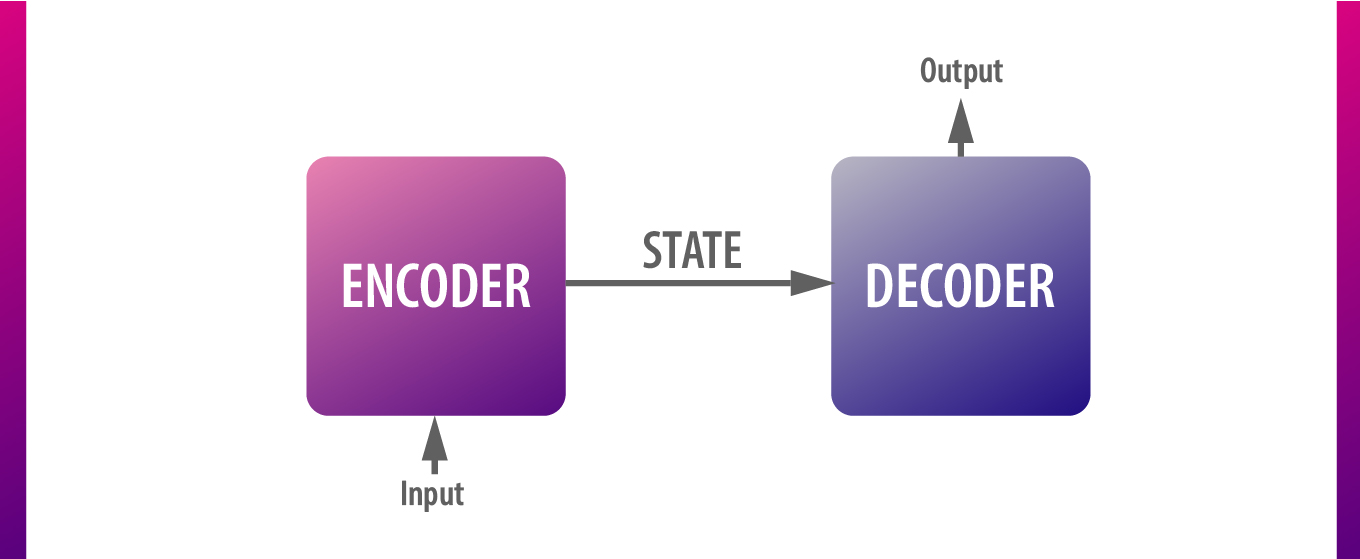
然而,香草seq2seq的问题是,它试图将整个输入的上下文塞进一个固定大小的矢量中,并且它可以携带多少数据是有限制的它们允许解码器网络在生产输出时专注于输入的相关部分。它们通过向来自编码步骤的每个解码步骤添加额外的输入来执行此操作。
RNN 的坠落和变压器
是的,我们可以使用 LSTM 构建在 RNN 中延长短内存,甚至使用关注点使用长内存。但是,我们仍不能完全消除渐变消失的影响,使这些模型(其设计抑制了并行计算)更快,或者使它们在序列中显式对远程依赖项和层次结构建模。
2017年,谷歌研究人员推出的”变形金刚”模型克服了RNN的所有缺点。这种新的革命性架构使我们能够完全依靠注意机制,在广泛的 NLP 任务(NMT、问题解答等)中消除重复计算,实现最先进的结果。
变压器也由编码器和解码器组成。它实际上在一侧有一堆编码器,另一侧有一叠解码器(具有相同数量的单元)。
编码
每个编码器单元由自注意层和前向层组成。
自我注意是允许单元格将输入的内容与序列中的所有其他输入进行比较并将它们之间的关系包含在嵌入中的机制。如果我们谈论的是一个词,自我注意允许代表一个句子中哪些其他词与它有着密切的关系。
在变压器模型中,每个位置可以同时与输入中的所有其他位置交互;网络的计算是微不足道的并行化。
多头注意机制进一步增强了自我注意层,该机制提高了模型聚焦于不同位置的能力,并使其能够创建表示子空间(将不同的权重矩阵应用于同一输入)。
为了确定输入的顺序,Transformers 向每个嵌入添加另一个矢量(这称为位置编码),这有助于它们识别序列中每个输入的位置以及它们之间的距离。
每个编码器将其输出推送到其正上方的单元。
在解码器方面,单元格之间也有一个自注意层、一个前向层和一个附加元素(编码器解码器注意层)。《变形金刚》中的解码器组件从顶部编码器(一系列关注向量)获取输出,并在预测目标序列时将其重点放在输入的相关部分上。
总体而言,变压器比RNN更轻,更容易训练,适合并行化;他们可以学习远距离依赖关系。
总结说明
变压器结构已成为许多突破性型号的基础。
Google 的研究使用”关注是您所需要的一切”论文中的想法来开发BERT – 一种强大的语言表示模型,可以轻松适应各种 NLP 任务(只需添加一个微调的输出层)和 OpenAI科学家们已经成功地创造了一个难以置信的连贯语言模型,根据他们的说法,这个模型太危险了,不能发布。
多头注意力技术目前正在各个研究领域进行试验。很快,我们可能会看到它深刻地改变多个行业。这将是令人兴奋的
