

概述
使用Spark构建推荐系统是一项简单的任务。Spark 的机器学习库已经为我们做了所有艰苦的工作。
在本研究中,我将向您展示如何使用以下技术为大数据构建可扩展的应用程序:
- 斯卡拉语
- 机器学习的火花
- 阿卡与演员
- 卡桑德拉
您可能还喜欢:
推荐系统简介
推荐系统是一种信息过滤机制,用于预测用户将给特定产品的评级。创建推荐系统有一些算法。
Apache Spark ML 实现用于协作筛选的交替最小二乘 (ALS),这是一种非常流行的提出建议的算法。
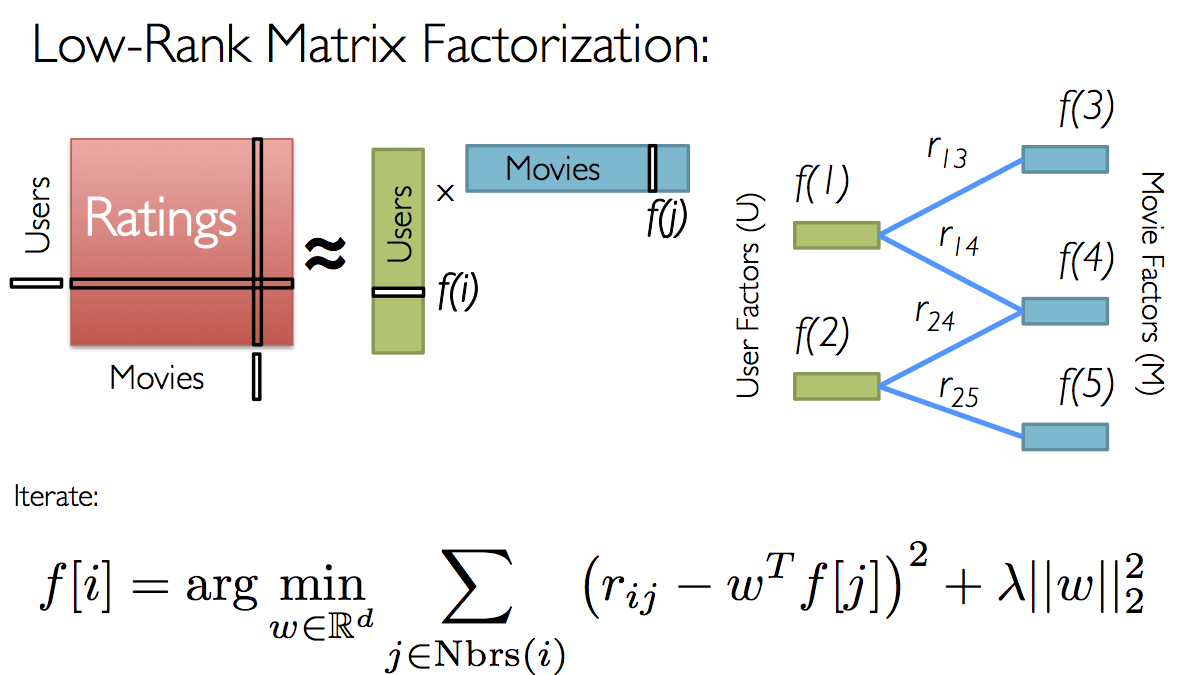
ALS 推荐器是一种矩阵分解算法,它使用具有加权-拉姆达-正则化 (ALS-WR) 的交替最小平方。它将用户到项目矩阵 A 到用户到要素矩阵(您和项到要素矩阵 M):
它以并行方式运行 ALS 算法。ALS 算法应发现将观察到的用户解释为项目评级的潜在因素,并尝试查找最佳因子权重,以最小化预测评级和实际评级之间的最小平方。
示例:
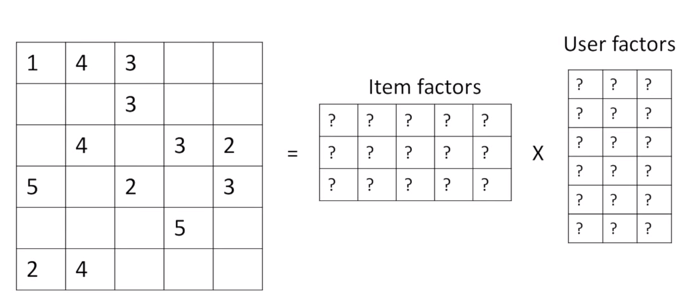
我们还知道,并非所有用户都对产品(电影)进行分级,或者我们还不知道矩阵中的所有条目。使用协作筛选,通过将其分解为两个矩阵的乘积来近似评级矩阵:一个描述每个用户的属性(以绿色显示),另一个描述每个影片的属性(以蓝色显示)。
示例:
1. 项目架构
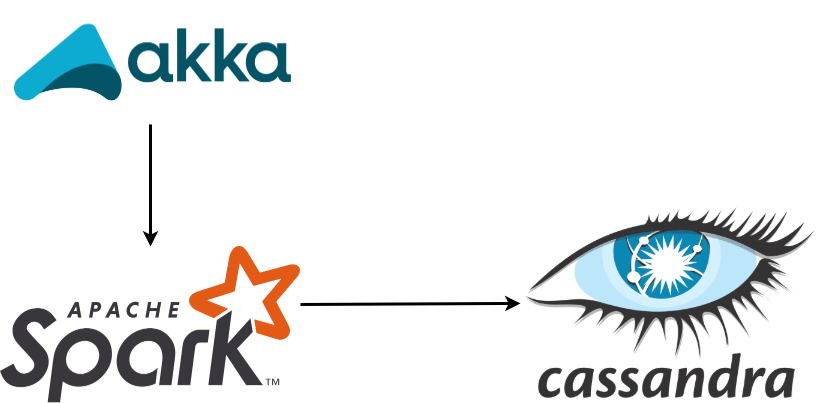
项目中使用的体系结构:
2. 数据集
具有电影信息和用户评分的数据集取自网站电影镜头。然后,数据被自定义并加载到阿帕奇卡桑德拉。卡桑德拉也使用了一个码头。
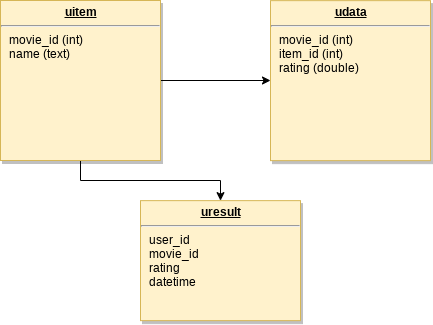
键空间称为电影。Cassandra 中的数据建模如下:
3. 《规范》
代码在: https://github.com/edersoncorbari/movie-rec
4. 组织和终点
集合:
| 集合 | 注释 |
|---|---|
| 电影.uitem | 包含可用影片,使用的数据集总数为 1682。 |
| 电影.udata | 包含每个用户分级的影片,使用的数据集总数为 100000。 |
| 电影.uresult | 在保存模型计算的数据时,默认情况下为空 |
5. 动手对接和配置卡桑德拉
运行以下命令以上载和配置 Cassandra:
$ docker pull cassandra:3.11.4
$ docker run --name cassandra-movie-rec -p 127.0.0.1:9042:9042 -p 127.0.0.1:9160:9160 -d cassandra:3.11.4在项目目录(电影-rec)中,有数据集已准备放入卡桑德拉。
$ cd movie-rec
$ cat dataset/ml-100k.tar.gz | docker exec -i cassandra-movie-rec tar zxvf - -C /tmp
$ docker exec -it cassandra-movie-rec cqlsh -f /tmp/ml-100k/schema.cql6. 动手运行和测试
输入项目根文件夹并运行命令。如果这是第一次,SBT 将下载必要的依赖项。
$ sbt run在另一个终端中,运行以下命令以训练模型:
$ curl -XPOST http://localhost:8080/movie-model-train这将启动模型训练。然后,您可以运行该命令以查看带有建议的结果。例子:
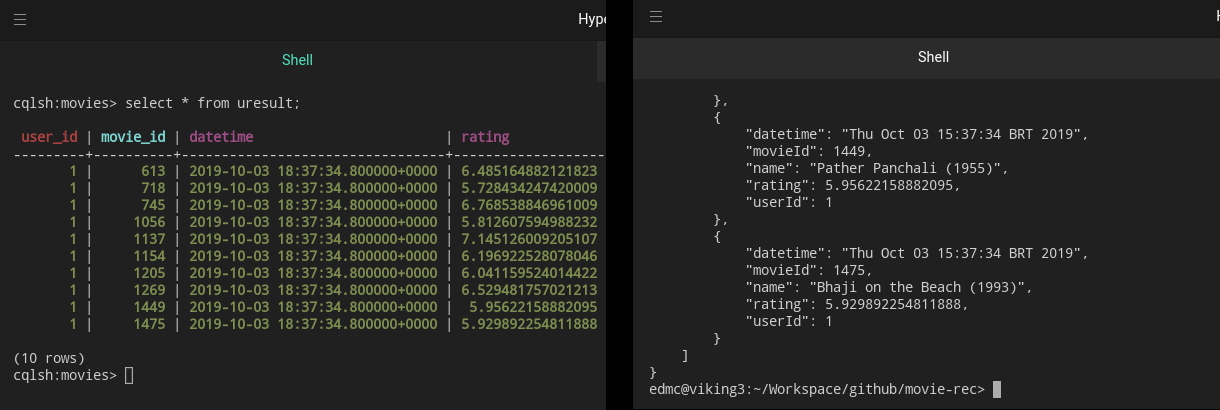
$ curl -XGET http://localhost:8080/movie-get-recommendation/1答案应该是:
{
"items": [
{
"datetime": "Thu Oct 03 15:37:34 BRT 2019",
"movieId": 613,
"name": "My Man Godfrey (1936)",
"rating": 6.485164882121823,
"userId": 1
},
{
"datetime": "Thu Oct 03 15:37:34 BRT 2019",
"movieId": 718,
"name": "In the Bleak Midwinter (1995)",
"rating": 5.728434247420009,
"userId": 1
},
...
}那是蛋糕上的冰块!请记住,该设置设置为显示每个用户 10 个影片建议。
您还可以在 uresult 集合中检查结果:
7. 模型预测
模型和应用程序培训设置位于: (src/主/资源/应用程序.conf)
model {
rank = 10
iterations = 10
lambda = 0.01
}此设置控制预测,并与我们拥有的数据量和类型相关联。有关更详细的项目信息,请访问以下链接:
8. 参考文献
使用的图书:
- 6.1. Scala机器学习项目
- 6.2. 使用Scala和Akka进行反应编程
Spark ML 文档:
- https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html
- https://spark.apache.org/docs/latest/ml-guide.html
谢谢!