
本文摘自我的书TinyML Cookbook,第二版 。您可以在此处找到文章中使用的代码.
准备工作
我们在本文中设计的应用程序旨在连续录制 1 秒的音频片段并运行模型推理,如下图所示:
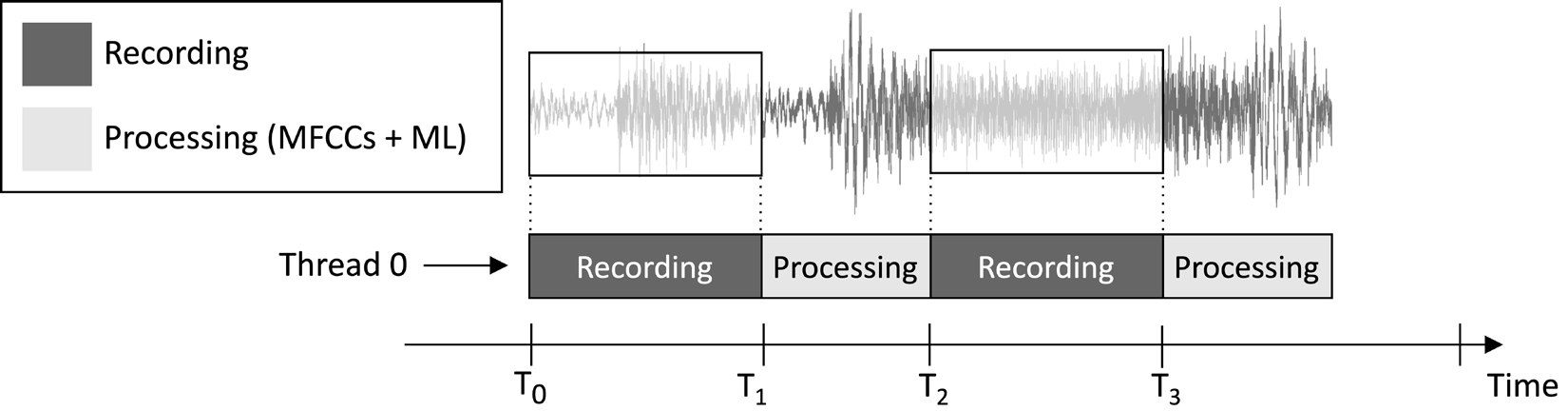
图 1:按顺序运行的记录和处理任务
从上图所示的任务执行时间线中,您可以观察到特征提取和模型推理始终在录音之后执行,而不是同时执行。因此,很明显我们没有处理实时音频流的某些片段。
与实时关键字识别 (KWS) 应用程序不同,实时关键字识别 (KWS) 应用程序应捕获并处理音频流的所有片段,以免错过任何口头单词,在这里,我们可以放宽此要求,因为它不会损害应用程序的有效性.
众所周知,MFCC特征提取的输入是Q15格式的1秒原始音频。然而,通过麦克风采集的样本表示为 16 位整数值。因此,我们如何将 16 位整数值转换为 Q15?解决方案比您想象的更简单:无需转换音频样本。
要了解原因,请考虑 Q15 定点格式。此格式可以表示 [-1, 1] 范围内的浮点值。从浮点转换为 Q15 需要将浮点值乘以 32,768 (215)。然而,由于浮点表示源自将 16 位整数样本除以 32,768 (215),因此这意味着 16 位整数值本质上是 Q15 格式。
如何做…
将带有麦克风的面包板连接到 Raspberry Pi皮科。断开数据线与微控制器的连接,并从面包板上取下按钮及其连接的跳线,因为本配方不需要它们。 图 2 显示了面包板上应有的内容:
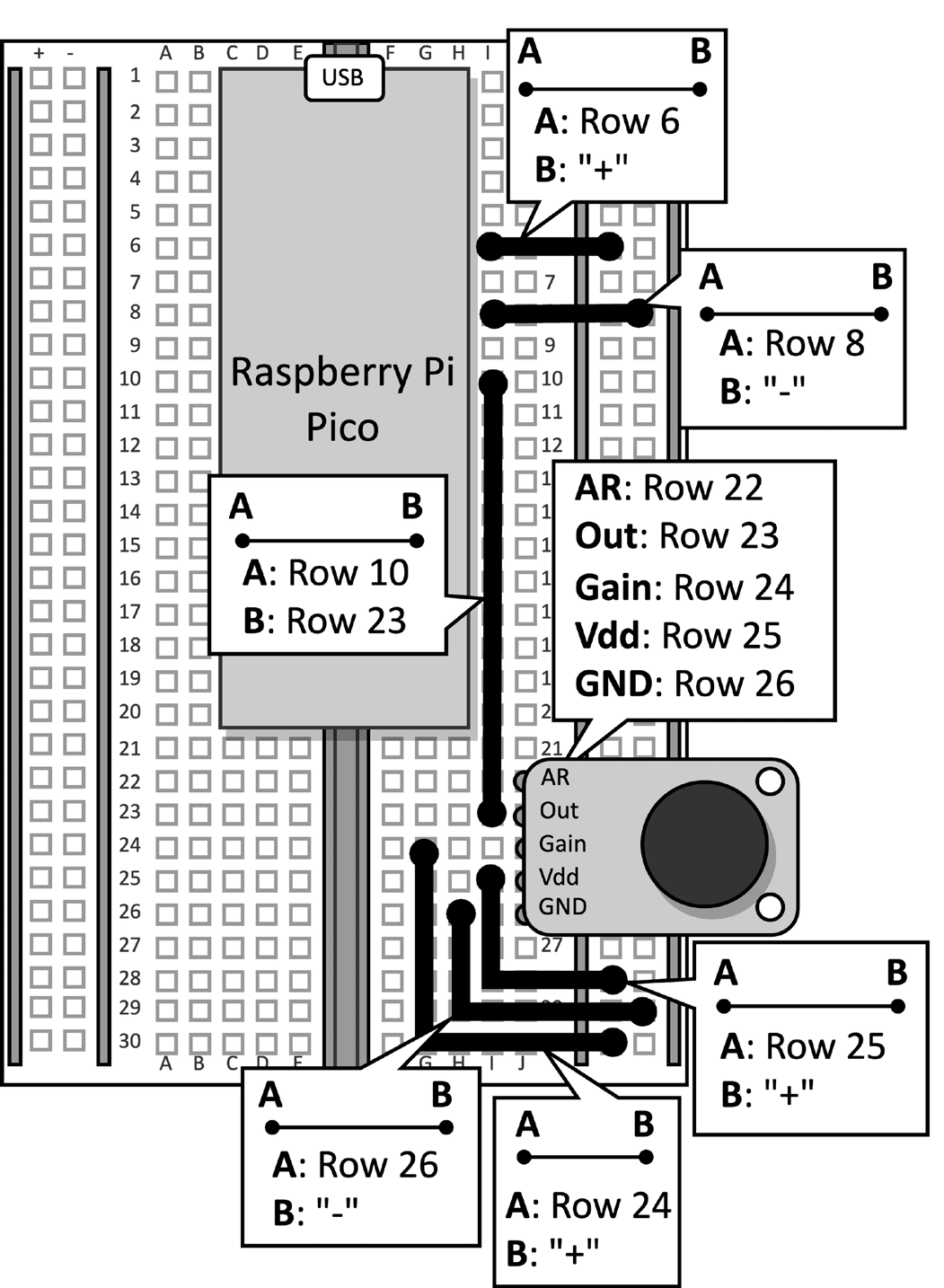
图 2:面包板上构建的电子电路
从面包板上取下按钮后,打开 Arduino IDE 并创建一个新的草图。
现在,按照以下步骤在 Raspberry Pi Pico 上开发音乐流派识别应用程序:
第 1 步
下载 Arduino TensorFlow Lite来自 TinyML-Cookbook_2E GitHub 存储库。
下载 ZIP 文件后,将其导入 Arduino IDE。
第 2 步
在 Arduino IDE 中导入 MFCC 特征提取算法所需的所有生成的 C 头文件,不包括 test_src.h 和 test_dst.h。
第 3 步
复制第 6 章中开发的草图,在 Raspberry Pi Pico 上部署 MFCC 特征提取算法,用于实现 MFCC 特征提取,不包括设置( ) 和 loop() 函数。
删除 test_src.h 和 test_dst.h 头文件。然后,删除 dst 数组的分配,因为 MFCC 将直接存储在模型的输入中。
第 4 步
复制第 5 章“使用 TensorFlow 和 Raspberry 识别音乐流派”Pi Pico – 第 1 部分中开发的草图,以使用麦克风录制音频样本,不包括 < code>setup() 和 loop() 函数。
导入代码后,删除对 LED 和按钮的任何引用,因为不再需要它们。然后,更改 AUDIO_LENGTH_SEC 的定义以录制持续 1 秒的音频:
#define AUDIO_LENGTH_SEC 1第 5 步
将包含 TensorFlow Lite 模型 (model.h) 的头文件导入 Arduino 项目。
导入文件后,将 model.h 头文件包含在草图中:
#include "model.h"
包含 tflite-micro 必需的头文件:
第 6 步
声明 tflite-micro 模型和解释器的全局变量:
然后,声明 TensorFlow Lite 张量对象 (TfLiteTensor) 以访问模型的输入和输出张量:
第 7 步
声明一个缓冲区(张量竞技场)来存储模型执行期间使用的中间张量:
张量区域的大小是通过经验测试确定的,因为中间张量所需的内存会有所不同,具体取决于 LSTM 运算符在底层的实现方式。我们在 Raspberry Pi Pico 上进行的实验发现,该模型仅需要 16 KB RAM 即可进行推理。
第 8 步
在setup()函数中,使用115200波特率初始化串行外设:
串行外设将用于通过串行通信传输识别的音乐流派。
步骤 9
在setup()函数中,加载存储在model.h头文件中的TensorFlow Lite模型:
tflu_model = tflite::GetModel(model_tflite);然后,注册tflite-micro支持的所有DNN操作,并初始化tflite-micro解释器:
tflite::AllOpsResolver tflu_ops_resolver;
静态 tflite::MicroInterpreter static_interpreter(
tflu_模型,
tflu_ops_resolver,
张量竞技场,
张量_竞技场_大小);
tflu_interpreter = &static_interpreter;第 10 步
在setup()函数中,分配模型所需的内存,并获取输入输出张量的内存指针:
第 11 步
在setup()函数中,使用Raspberry Pi Pico SDK初始化ADC外设:
第 12 步
在loop()函数中,准备模型的输入。为此,请录制 1 秒的音频剪辑:
//重置音频缓冲区
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / 采样率;
定时器.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
定时器.detach();录制音频后,提取 MFCC:
从前面的代码片段中可以看出,MFCC 将直接存储在模型的输入中。
第 13 步
运行模型推理并通过串行通信返回分类结果: