

桔妹导读:小桔车服为滴滴旗下品牌,围绕车主及汽车生命周期,整合运营多项汽车服务,更加智能更加用心地为车主提供适合的一站式用车服务,致力于让每一个人拥有轻松车生活。
本次分享的主题为强化学习在小桔车服用户运营中的实践。在互联网场景下,面向用户的营销是每个业务所对的共同问题,而如何帮助小桔车服运营提升营销的 ROI 是我们算法同学的工作重点之一。在本文,我们将向大家介绍如何将车服的营销问题建模为一个强化学习过程,并且如何精细化地对每个人做出个性化的营销动作,在实际业务中又取得了怎样的效果。
1.
小桔车服用户运营算法体系
▍滴滴用户运营算法模型
为了支持用户增长的需求,小桔车服构建了一个平台,一个系统以及四个算法策略模块:即流量分发平台、标签系统、画像模块、目标人群定向模块、营销策略模块、触达优化模块。
- 流量分发平台是对用户进行场景化广告的弹出,和用户进行一些交互,包括发 push 消息、播报及发短信消息等各种渠道。
- 标签系统一方面在线上服务中判别用户的身份属性、状态以及身份,另一方面是帮助各业务的运营人员去细粒度的圈选目标人群。
针对用户运营的四个阶段,也有相应的算法策略模块:
模块一:画像
包括用户画像,商家画像以及车辆画像,目标是把生态内的各个实体细粒度的刻画出来。
模块二:目标人群的定向
用户运营首先根据任务和用户生命周期去找到合适的用户群体,比如对用户长期价值的定向、对短期的转化率的预估、用户流失预警、体系外用户的精准定向等。
模块三:营销策略
分两部分,一个是滴滴体系内线上的一些算法策略模块,如强化学习、组合策略、个性化推荐,滴滴体系内有大量的拉单司机、专车司机、快车司机、顺风车司机以及出租车司机,他们和滴滴平台有非常紧密的联系,每天都在平台内拉单,用户行为非常稠密,为智能营销提供了丰富的源数据。另一部分是滴滴体系外的用户增长,如社交营销、DSP 外投广告。
模块四:触达优化
算法根据用户的状态和行为发放给用户一张一定面额的优惠券或一个活动提醒,为了增强用户的转化意愿,在触达优化阶段对用户进行个性化的消息提醒。因为平台业务众多,各业务下的运营活动众多,为了避免无节制地把所有的活动消息在很短的时间内推送给同一个人,需要做一些取舍,这就是全局流量优化解决的问题:在尽量减少打扰用户的限制下,提升平台的收益
▍滴滴人工运营的痛点和解决档案
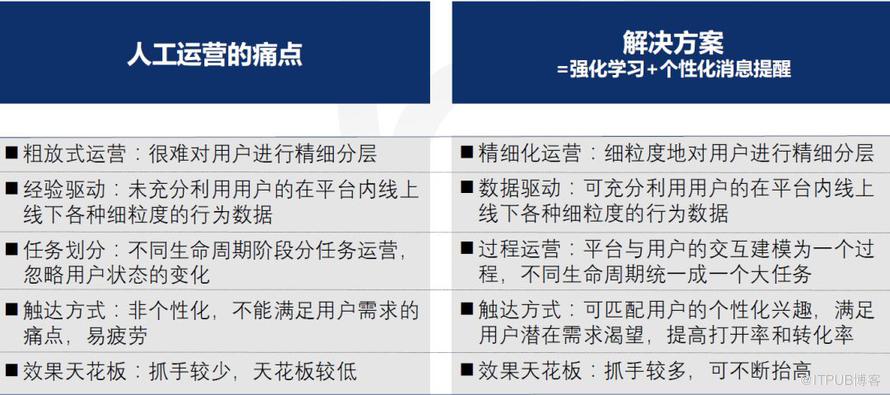
人工运营的痛点和解决方案人工运营和监督学习方法可以圈选目标人群进行运营活动,但是比较粗放,依赖运营人员的经验,将用户生命周期强制分成拉新、提频、沉默召回等阶段,由不同运营人员负责,但是这样将连续过程割裂开不利于运营效果的提升;同时没有利用平台用户线上线下丰富的行为特征,很难对用户进行精细化的分析和运营;消息提醒千篇一律,用户会感到疲劳从而影响转化率。针对这些痛点,小桔车服采用强化学习方法对用户和平台之间的交互过程进行建模,并且在消息提醒阶段,使用 graph embedding 方法根据用户的兴趣进行个性化的消息提醒,真正的做到精准触达。
2.
智能营销建模方法
▍强化学习
强化学习是一种与监督学习不一样的学习范式,通过一个智能体与环境进行交互从而达到学习目标。其最重要的概念包括状态 State、动作 Action、回报 Reward,智能体接收到环境的状态后,对该状态做出一个动作,环境根据该动作做出一个回报,然后进行一轮一轮的过程学习。强化学习的典型应用有游戏、个性化推荐、效果广告和网约车调度,如 AlphaGo Zero 在围棋领域战胜世界顶级选手、多款游戏中的 OpenAI 基本战胜人类,滴滴的网约车调度也采用强化学习去预测司机和乘客在时空中的匹配价值,进而在提升平台 GMV 的同时也提升了乘客和用户的产品体验。

强化学习分类大的方面强化学习可分为 Model based 和 Model free,两者的区别是 Model based 可以完整的了解并学习 Agent 所处的环境,Model free 却不能。Model free 分为三方面:策略梯度优化、Q-learning 及两者的结合,策略梯度优化适用的场景是动作连续的或者动作空间非常大,比较适合推荐或广告领域,典型的方法有 A3C 和 PPO;Q-learning 适合的场景是动作空间有限的几个或几十个,典型方法有 deep Q-learning;两者结合的典型方法有 DDPG 和 SAC。针对车服用户运营的问题,首先两个实体中 Agent 是车服平台,Environment 是用户,或者其他上下文。在每一轮迭代中 Agent 会向环境发送一张一定面额一定周期的优惠券,或者一定周期的消息或者空动作,Environment 收到动作后经过一定周期会做出一个正向或负向反馈,该反馈被量化后发送给 Agent,环境状态的变化 State 也会返回给 Agent。
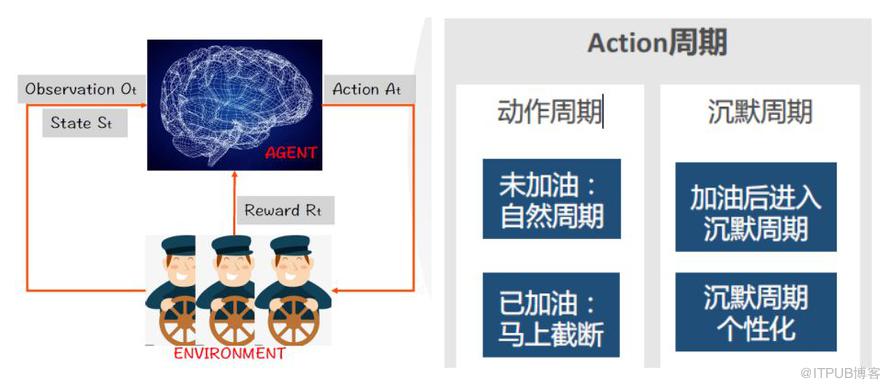
强化学习图解 + Action 周期在这个场景里,强化学习的第一个要素 Action 包括不同面额优惠券的推送、不同周期的消息推送、空动作;第二个要素 State 是观察和抽取出来的一些特征的表征,包括用户线下行为、用户线上行为、静态行为、模型学习预估分;第三个要素 Reward 是用户对 Action 的反馈,如空动作加油、消息推送加油、用优惠券加油;用户查看优惠券、查看消息;无加油无查看。除此之外,针对场景需要定义了两类 Action 周期:动作周期和沉默周期,传统强化学习当 Agent 发出动作 Environment 会马上给出一个响应,但在 O2O 场景下用户需要一定周期(动作周期)对动作做出响应,如加油,并且在下一时刻用户不可能再去加油,会进入沉默周期。
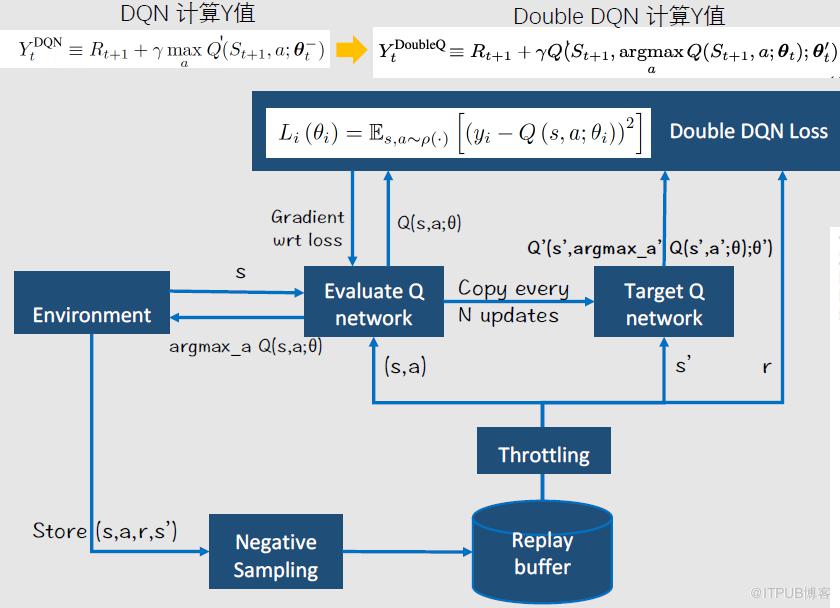
Double DQN 算法流程因为经典的 DQN 会带来 Q 值预估的 overstimatation,进而引起接下来训练的震荡,所以具体的算法采用 Double deep Q-learning network,算法分为训练部分和预测部分:训练部分的核心是损失值 loss 的不同,double DQN 中左边网络训练的 Q 值会周期性的复制给右侧的 target Q-network,二者共同去计算得到最终的损失值 loss;预测部分是 Environment 会把当前的状态输出给 Double DQN,通过计算将 Q 值最大的 Action 返回给环境,如发一张合适的优惠券、一个消息推送或者空动作。此外针对正负比例不均衡的情况,算法采用了负采样的方法。
▍Double DQN 算法流程
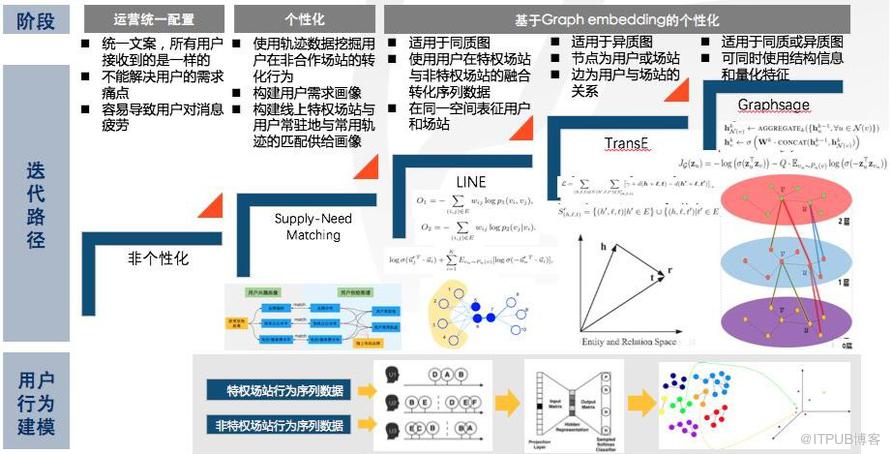
消息提醒部分可分为三个阶段:首先是运营统一配置,在这个阶段所有人收到的消息是一样的,用户容易产生疲劳;其次是初步的个性化,同时构建用户的需求画像和平台的供给画像,然后将二者匹配起来,这样可以达到一个相对较好的结果。最后是为了达到更好的个性化结果,基于用户的行为序列构建相应的图,采用 graph embedding 学习方法实现个性化消息的推送,具体使用了三种方法:LINE、TransE、Graphsage。LINE 适用同质图进行学习,在同一空间表征用户和场站,使用用户在特权场站与非特权场站的融合转化序列数据;TransE 适用于异质图,节点的种类包含用户或场站,边为用户与场站的关系;Graphsage 适用于同质或异质图,可同时使用结构信息和量化特征。
▍强化学习和 graph embedding 相结合
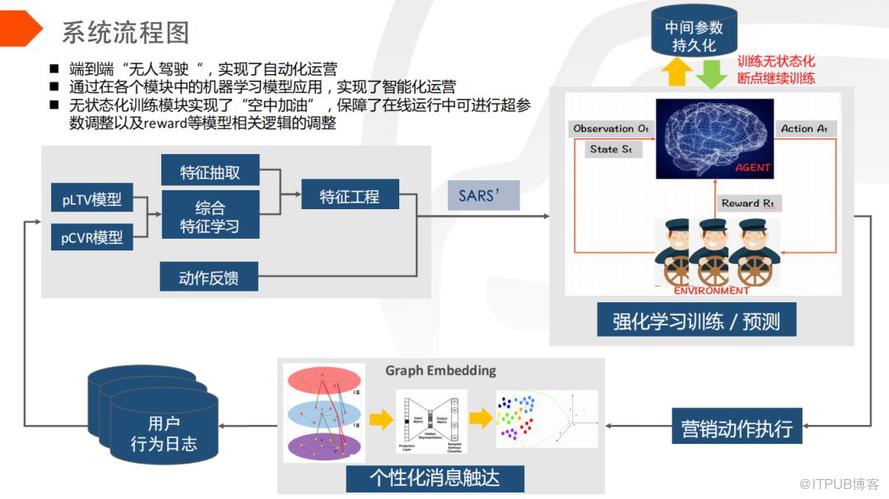
将强化学习和 graph embedding 两者结合,目前在端到端 “无人驾驶” 的大流量上已经实现了自动化运营,通过在各个模块中机器学习模型的应用,实现了智能化运营。首先通过特征提取模块的学习得到强化学习所需要的 State、Action、Reword 三要素,然后放到强化学习算法中去学习和训练,产出营销动作进而执行,执行的时候通过 graph embedding 个性化的消息推送,给每个用户匹配合适的服务,进而提高用户的消息打开率和转化率,最后通过用户行为收集进入下一轮的迭代,而且在强化学习过程中,实现了中间参数持久化的无状态化训练。
3.
效果展示
▍强化学习算法效果
强化学习部分,从 ROI 的趋势图可以看到强化学习实验组 ROI 是稳定的,基本上是稳定的高于对照组的。
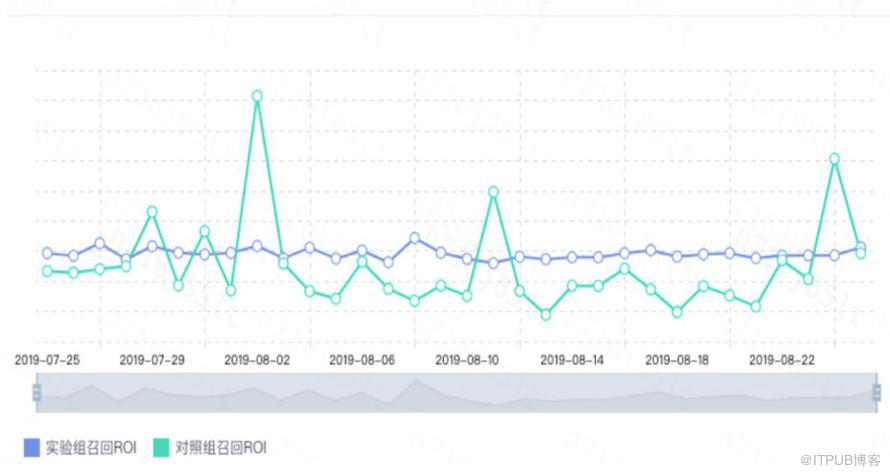
ROI趋势图目前强化学习算法已经全流量覆盖加油业务用户,包括有券提醒和无券推送,强化学习桶比人工运营桶在拉新率和召回率上都有约8%的提升,同时成本大约降低了一半,真正实现了一个比较高的 ROI,从而做到了更加精细化的运营。
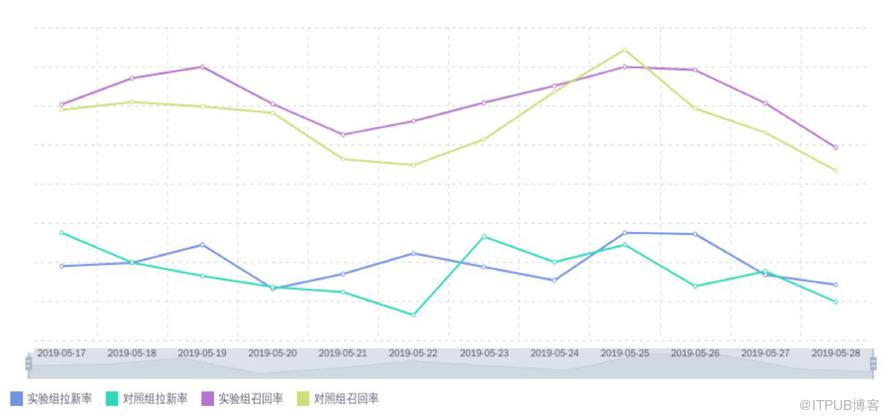
强化学习拉新召回率对比
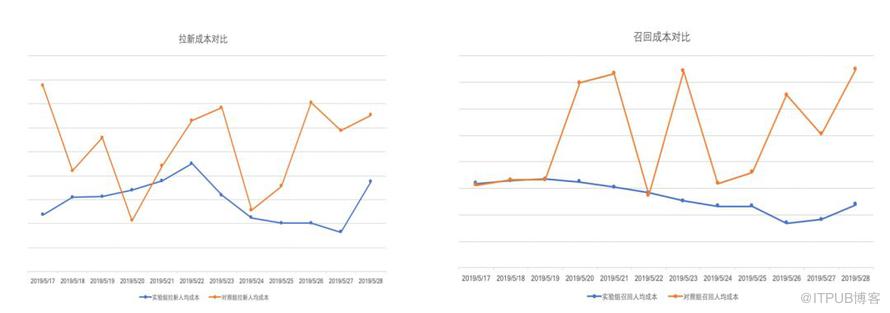
拉新成本对比和召回成本对比
▍Graph embedding 个性化消息提醒效果
关于个性化消息提醒方面的优化,首先用 LINE 方法和人工供需匹配做对比,在消息打开率和转化率上分别提升了7%和10%;然后将 TransE 方法和 LINE 方法做对比,在打开率和转化率方面分别提升了4%和6%,累计起来的话 TransE 方法比人工供需匹配在打开率上提升11%,转化率上提升16%。总之,目前基于 graph embedding 的个性化消息提醒方法在加油业务全流量上,每天对大量用户进行个性化的消息提醒,用户体验也明显提升。在用户增长上,车服算法团队初步建立起来一套智能营销的体系,通过数据驱动的方式精细化地赋能了运营,提升了用户增长的效果和效率。本次分享就到这里,谢谢大家!文章首发自 DataFunTalk ,点击此处可查看原文。
本文作者
▬刘 凯滴滴 | 高级算法专家博士毕业于中国科学院自动化所。做人低调,做事高调。以第一作者发表了多篇顶级国际学术杂志和会议文章,深耕于个性化推荐、效果广告、智能营销等相关领域。