
python 线程
在上一篇文章中, 我们研究了 python 中的线程方法。在本文中, 我们将介绍守护进程线程和锁。
守护进程线程
到目前为止, 我们已经创建了一个非守护进程线程。什么是守护进程线程?当主线程退出时, 它将尝试终止其所有守护子线程。
请考虑 gui 的一个示例, 如下所示:
考虑到, 通过 gui 输入, 一些计算正在后台执行, 计算需要时间。
如果单击 “关闭” 按钮, 可以执行两个操作过程。
- 单击 “关闭” 按钮后, 整个 gui 窗口将关闭。
- 单击 “关闭” 按钮后, gui 窗口将等待后台计算的完成。
如果执行第一个操作过程, 则在后台计算中使用守护进程线程。如果执行第二个操作过程, 则在后台计算中使用非守护进程线程。
让我们通过一些代码来理解这一点:
import threading
import time
def n():
print(“Non deamon start”)
print(“NOn daemoon exit”)
def d():
print(”daemon start”)
time.sleep(5)
print(”daemon stop”)
t = threading.Thread(name = “non - daemon”, target = n)
d = threading.Thread(name = “daemon”, target = d)
d.setDaemon(True)
d.start()
t.start()如果方法 < c/ > returns < c2/> ,则线程是守护进程线程。语法 < cn/> 或 < cl > 可用于制作守护程序线程。
让我们看看输出: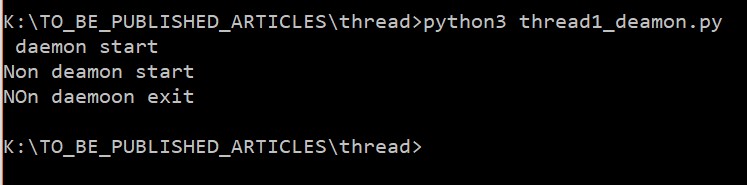
守护进程线程将需要5秒才能完成其任务, 但主线程没有等待守护进程线程。这就是为什么在输出中没有 “守护进程停止” 语句的原因。现在从 < c/> 函数中删除 < cn/>, 并将其添加到 < c/> 函数中。
请参见下面的代码:
import threading
import time
def n():
print(“Non deamon start”)
time.sleep(5)
print(“NOn daemoon exit”)
def d():
print(”daemon start”)
print(”daemon stop”)
t = threading.Thread(name = “non - daemon”, target = n)
d = threading.Thread(name = “daemon”, target = d)
d.setDaemon(True)
d.start()
t.start()请参见输出:
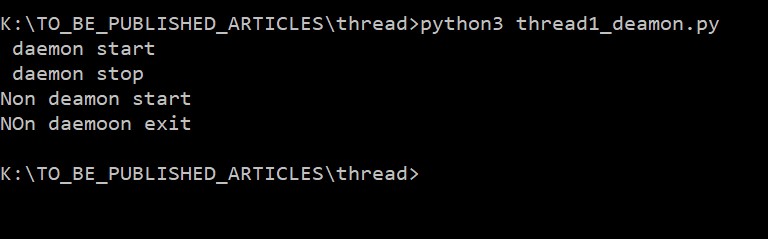
在上面的示例中, 将执行所有打印语句。主线程必须等待非守护进程。
注意: 如果使用守护进程线程的联接语句, 则主线程必须等待守护进程线程任务的完成。
锁
锁是线程模块提供的最基本的同步机制。锁处于两种状态之一: 锁定或解锁。如果线程尝试持有已由其他线程持有的锁, 则第二个线程的执行将停止, 直到释放锁获取 ():
获取锁, 阻止其他锁, 直到 true (默认值)。
锁定. 锁定 ():
如果锁被锁定, 则返回 true, 否则为 false。
版本 ():
解锁。
让我们看一个例子。
import threading
import time
lock = threading.Lock()
list1 = []
def fun1(a):
lock.acquire()
list1.append(a)
lock.release()
for each in range(10):
thread1 = threading.Thread(target = fun1, args = (each, ))
thread1.start()
print(“List1 is: “, list1)语句用于创建锁对象.
锁的主要问题是锁不记得哪个线程获取了锁。现在可能会出现两个问题。
请参阅下面的代码。
import threading
import time
lock = threading.Lock()
import datetime
t1 = datetime.datetime.now()
def second(n):
lock.acquire()
print(n)
def third():
time.sleep(5)
lock.release()
print(“Thread3“)
th1 = threading.Thread(target = second, args = (“Thread1”, ))
th1.start()
th2 = threading.Thread(target = second, args = (“Thread2”, ))
th2.start()
th3 = threading.Thread(target = third)
th3.start()
th1.join()
th2.join()
th3.join()
t2 = datetime.datetime.now()
print(“Total time”, t2 - t1)在上述代码中, 锁由 < cn/获取, 并由 < c2/发布。< cn/> 正在尝试获取锁。
让我们看看输出。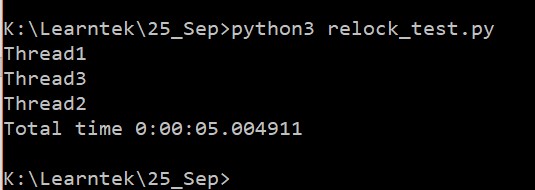 从执行顺序可以看出, 由 < cn/获取的锁是由 < cn> 释放的。
从执行顺序可以看出, 由 < cn/获取的锁是由 < cn> 释放的。
让我们来看看第二个问题。
import threading
lock = threading.Lock()
def first(n):
lock.acquire()
a = 12 + n
lock.release()
print(a)
def second(n):
lock.acquire()
b = 12 + n
lock.release()
print(b)
def all():
lock.acquire()
first(2)
second(3)
lock.release()
th1 = threading.Thread(target = all)
th1.start()当您运行上述代码时, 将发生死锁。在函数中, 所有线程都将获得一个锁, 在获取锁之后, 将调用第一个函数。线程将看到 < cn/> 语句。由于此锁本身是由同一线程获取的。但锁不记得获取它的线程。
为了克服上述问题, 我们使用重入锁(rlock)。
只需将 < cn/ > 改为 < c2/ .
线程。rlock () -返回新的重入锁对象的工厂函数。重新锁定锁必须由获取它的线程释放。一旦线程获得了重新进入的锁, 同一线程可能会再次获得它而不阻塞;线程必须在每次获取它时释放一次它。
锁与锁
主要区别在于, 锁只能获得一次。它不能再次获得, 直到它被释放 (它被释放后, 它可以被重新获得的任何线程)。
另一方面, rlock 可以通过同一线程多次获取。它需要释放相同的次数才能 “解锁”。
另一个区别是, 获取的锁可以由任何线程释放, 而获取的 rlock 只能由获取它的线程释放但是, python 解释器并不是完全线程安全的。为了支持多线程 python 程序, 使用了名为全局解释器锁 (gil) 的全局锁。这意味着只有一个线程可以同时执行 python 代码;python 会在很短的时间后或当线程执行可能需要一段时间的操作时自动切换到下一个线程。gil 不足以避免您自己的程序中出现问题。虽然, 如果多个线程试图访问同一数据对象, 它可能最终处于不一致的状态。
让我们看看这个例子。
import datetime
def count(n):
t1 = datetime.datetime.now()
while n > 0:
n = n - 1
t2 = datetime.datetime.now()
print(t2 - t1)
count(100000000)在上面的代码中, 计数函数正在运行主线程。让我们看看线程所花费的时间。
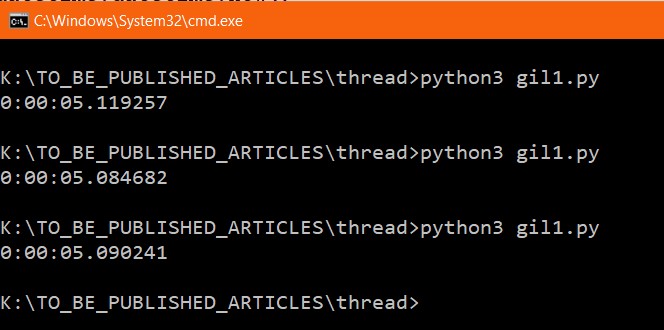 我运行了三次代码, 每次我得到一个类似的结果。
我运行了三次代码, 每次我得到一个类似的结果。
让我们创建两个线程, 请参阅下面的代码。
import datetime
from threading
import Thread
def count(n):
while n > 0:
n = n - 1
def count1(n):
while n > 0:
n = n - 1
t1 = datetime.datetime.now()
thread1 = Thread(target = count, args = (100000000, ))
thread2 = Thread(target = count1, args = (100000000, ))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
t2 = datetime.datetime.now()
print(t2 - t1)在上面, 创建了两个并行运行的线程。
让我们看看结果。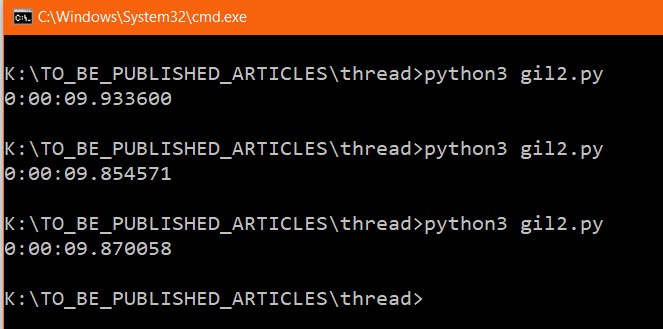
你可以用上面的代码花了近 10秒, 这是以前程序的两倍, 这意味着, 只有主线程充当多线程。但是, 在上面的实验中, 我们可以得出结论, 多线程被定义为处理器同时执行多个线程的能力。
在一个简单的单核 cpu 中, 它是通过线程之间频繁切换来实现的。这称为上下文切换。在上下文切换中, 只要发生任何中断 (由于 i传递或手动设置), 就会保存线程的状态并加载另一个线程的状态。上下文切换发生得非常频繁, 以至于所有线程似乎都在并行运行 (这称为多任务处理)。
我希望你喜欢这篇文章。


