
自从我们能够对蛋白质进行排序以来, 三维结构就受到了巨大的实验关注。由于新方法的发展和技术的进步, 随着时间的推移, 确定这些结构已成为一个更准确和进步的过程。
然而, 问题在于, 发现新蛋白质结构的进展没有跟上新序列产生的速度。因此, 我们看到, 正在产生的新序列数量与正在识别的三维结构之间的差距不断扩大。
如果有足够的准确性, 一个可能的解决方案是蛋白质结构的计算预测。同源建模、折叠识别和新颖建模等方法可以用来填补这一空白。然而, 无论使用哪种方法, 随着序列数据量的迅速增加, 根本问题仍然是缺乏一个单一的知识库, 无法对蛋白质序列的宇宙进行快速而有力的扫描。所有公开的数据目前都位于跨许多不同来源的各种数据库中。从一个来源转移到另一个来源不是–当然也绝不能–是这一进程中最大的挑战。
在这篇文章中, 我的目的是展示知识图如何通过允许您加快蛋白质结构预测过程:
- 查询对单个、全面且相互关联的蛋白质序列数据集的见解。
- 搜索并生成一组入围的序列, 以便传递给预测过程中的下一个计算组件。
一个知识图中的所有数据
下图说明了我认为蛋白质序列结构这一领域的知识图模型是什么样子的。
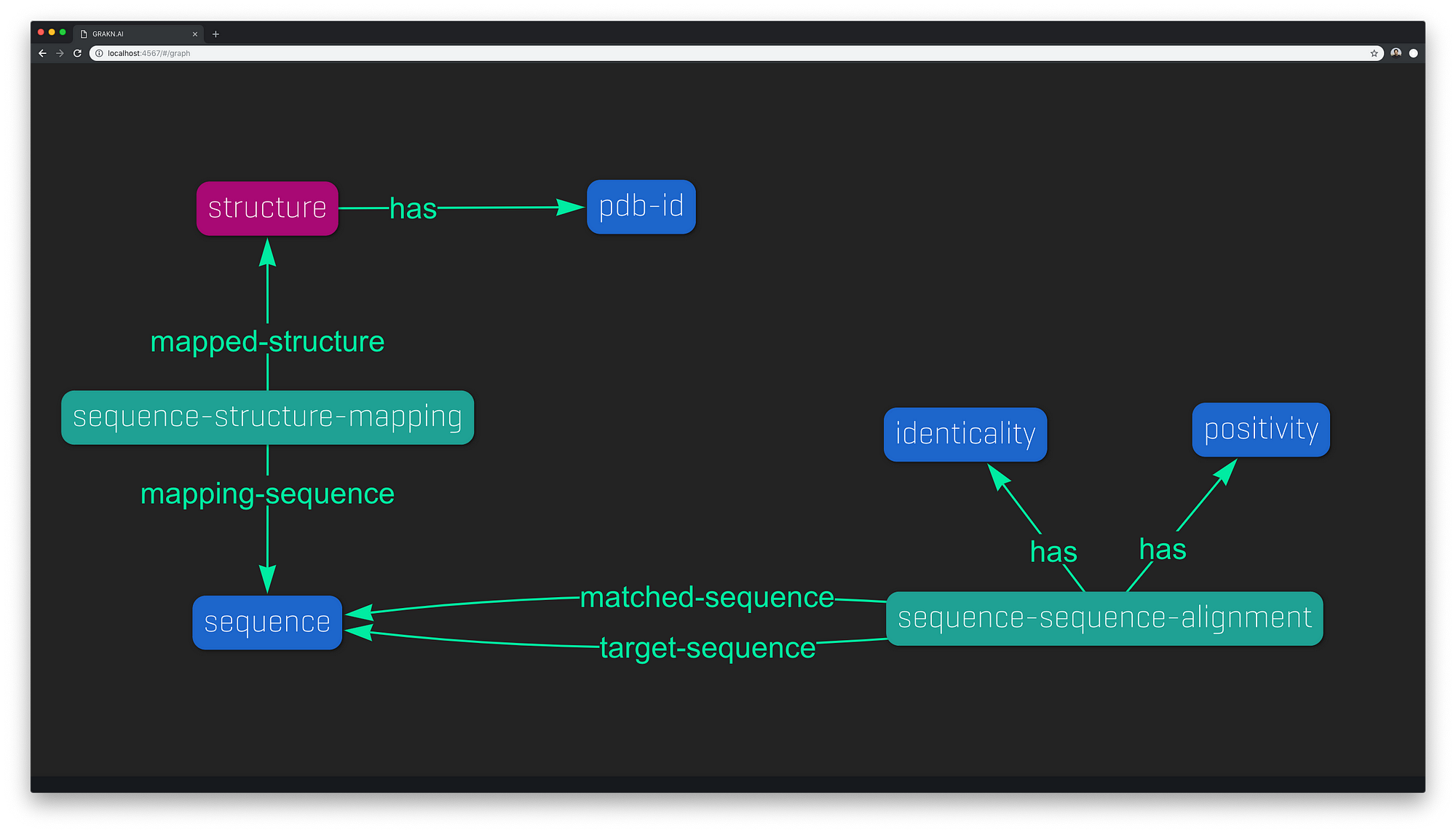
这个 grakn 知识图扮演一个单一知识库的角色, 它包含从各种来源 (如 uniprot 和 pdb) 提取的所有相关数据。这些数据也可以从与 grakn一起运行 blast 中提取出来。
将数据迁移到 grakn: 要了解如何将 csv、json 和 xml 格式的数据迁移到 grakn 知识图, 请查看全面和分步的迁移指南。
洞察查询
现在, 我们已经在 grakn 知识图中表示了所有相关数据 (如上所示), 我们可以继续在此数据集上提出以下问题。在每个问题中, 我都包含了相关的查询。
- 以下序列的结构是什么?
MNVGTAHSEVNPNTRVMNSRGIWLSYVLAIGLLHIVLLSIPFVSVPVVWTLTNLIHNMGMYIFLHTVKGTPFETPDQGKARLLTHWEQMDYGVQFTASRKFLTITPIVLYFLTSFYTKYDQIHFVLNTVSLMSVLIPKLPQLHGVRIFGINKYmatch
$target-sequence isa sequence "MNVGTAHSEVNPNTRVMNSRGIWLSYVLAIGLLHIVLLSIPFVSVPVVWTLTNLIHNMGMYIFLHTVKGTPFETPDQGKARLLTHWEQMDYGVQFTASRKFLTITPIVLYFLTSFYTKYDQIHFVLNTVSLMSVLIPKLPQLHGVRIFGINKY";
$structure isa structure;
(mapping-sequence: $target-sequence, mapped-structure: $structure) isa sequence-structure-mapping;
get $structure;- 哪些序列的结构与 pdg id 的 “2rhc”?
match
$target-structure isa strucuture has pdb-id "2RHC";
$sequence isa sequence;
(mapping-sequence: $sequence, mapped-structure: $target-structure) isa sequence-structure-mapping;
get $sequence;- 下面的序列没有已知的结构
8;
$structure 结构;
(映射序列: $$3 相似序列, 映射结构: $$结构) a 序列结构映射;
获得 $structure 结构;
你上面看到的密码是 graql。格拉克尔是格拉金的语言。它的表现力使它成为人类极其可读和直观的原因。简单地说, graql 是一种查询语言, 任何人都可以理解和编写, 而不仅仅是程序员。
扩展知识图
当我们决定将更多相关的数据源引入 grakn 知识图时, 模型可以以最小的努力进行进化和扩展。
一个例子
下面我包括了定义模型的代码, 我在本文前面说明了这个模型。如果我们扩展这个模型, 并引入与蛋白质序列 < c2/的关系的蛋白质序列 < cn/>, 我们可以这样扩展模型 (又名. a. 架构):
define
sequence-sequence-alignment sub relationship,
relates target-sequence,
relates matched-sequence,
has identicality,
has positivity;
sequence-structure-mapping sub relationship,
relates mapped-structure,
relates mapping-sequence;
//structure-function-mapping sub relationship,
//relates mapping-structure,
//relates mapped-function;
sequence sub attribute datatype string,
plays target-sequence,
plays matched-sequence,
plays mapping-sequence;
structure sub entity,
plays mapped-structure,
//plays mapping-structure,
has pdb-id;
//function sub attribute datatype string,
//plays mapped-function;
identicality sub attribute datatype double;
positivity sub attribute datatype double;
pdb-id sub attribute datatype string上面的注释行是我们需要添加的额外代码。没有其他需要改变的。知识图的这个扩展模型现在是这样的。
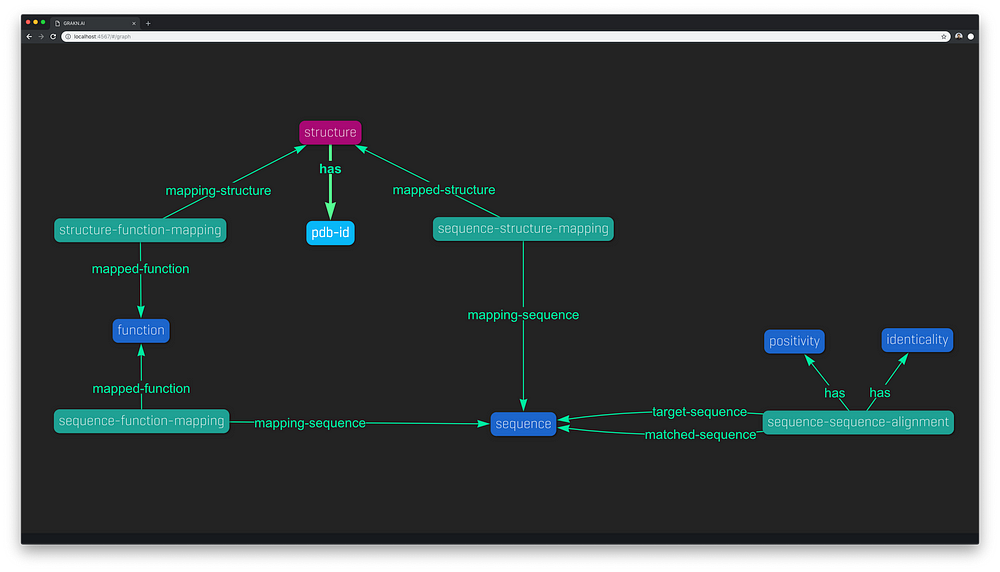
扩展模型: “函数” 被添加为一个吸引人, 并映射为 “结构” (直接) 和 “序列” (通过推断)。
考虑到新的关系 < c/> 和以前的关系 < c1 >, 我们可以利用 grakn 的自动推理能力进行推理, 从而产生新的知识–隐含的 < c/> 关系
通过对架构的这些添加, 我们现在可以提出以下问题:
- 哪些序列具有 “酶” 的功能?
match
$target-function isa function "enzyme";
$sequence isa sequence;
(mapping-sequence: $sequence, mapped-function: $target-function) isa sequence-function-mapping;
get $sequence;- 哪些函数直接映射到以下序列, 或通过至少与给定序列相同80% 的对齐序列间接映射?
The sequence: MNVGTAHSEVNPNTRVMNSRGIWLSYVLAIGLLHIVLLSIPFVSVPVVWTLTNL IHNMGMYIFLHTVKGTPFETPDQGKARLLTHWEQMDYGVQFTASRKFLTITPIVLYFLTSFYTKYDQIHFVLNTVSLMSVLIPKLPQLHGVRIFGINKYmatch
$target-sequence isa sequence "MNVGTAHSEVNPNTRVMNSRGIWLSYVLAIGLLHIVLLSIPFVSVPVVWTLTNLIHNMGMYIFLHTVKGTPFETPDQGKARLLTHWEQMDYGVQFTASRKFLTITPIVLYFLTSFYTKYDQIHFVLNTVSLMSVLIPKLPQLHGVRIFGINKY";
$direct-function isa function;
(mapping-sequence: $target-sequence, mapped-function: $direct-function) isa sequence-function-mapping;
$similar-sequence isa sequence;
$alignment (target-sequence: $target-sequence, matched-sequence: $similar-sequence) isa sequence-sequence-alignment;
$alignment has identicality > 0.8;
$indirect-function isa function;
(mapping-sequence: $similar-sequence, mapped-function: $indirect-function) isa sequence-function-mapping;
get $direct-function, $indirect-function;grakn 规则
你在上面看到的只是一个例子, 说明如何扩展 grakn 知识图来推断新的知识。规则可以写在任何研究领域, 以:
- 注入生物事实。
- 根据新的发现推断 (假设)。
- 强制约束。
这完全取决于你如何选择通过编写适合自己工作的规则来使你的知识图更加智能。
机遇是无穷无尽的!
grakn 是关于用智能的方式对智能知识图进行建模。我们相信简单是智力的基石。因此, 查询语言-graql。你可以用 grakn 知识图建模和查询的东西只受到你的意志和想象力的限制。
查看grakn 中对数据集建模背后的思维过程示例。阅读有关架构概念、类型和规则的信息。通过graql 查询的示例或了解如何编写自己的查询。
为您的灵感
- 序列对齐分析
- 药物重新定位