
在本文中,我们介绍了交付时间预估迭代的三个版本,分别为基于地址结构的树模型、向量召回方案以及轻量级的End-to-End的深度学习网络。同时介绍了如何在性能和指标之间取舍,以及模型策略迭代的中间历程,希望能给从事相关工作的同学们有所启发和帮助。
1. 背景
可能很多同学都不知道,从打开美团App点一份外卖开始,然后在半小时内就可以从骑手小哥手中拿到温热的饭菜,这中间涉及的环节有多么复杂。而美团配送技术团队的核心任务,就是将每天来自祖国各地的数千万份订单,迅速调度几十万骑手小哥按照最优路线,并以最快的速度送到大家手中。
在这种场景下,骑手的交付时间,即骑手到达用户附近下车后多久能送到用户手中,就是一个非常重要的环节。下图是一个订单在整个配送链路的时间构成,时间轴最右部分描述了交付环节在整个配送环节中的位置。交付时间衡量的是骑手送餐时的交付难度,包括从骑手到达用户楼宇附近,到将餐品交付到用户手中的整个时间。
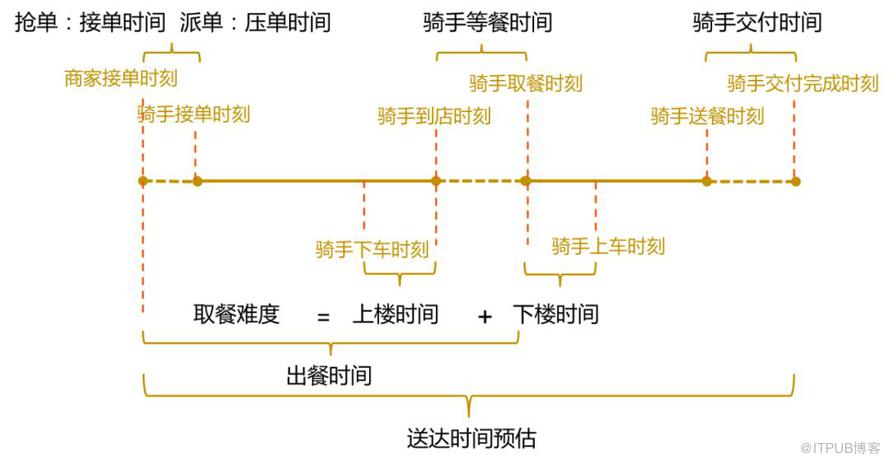
交付时间的衡量是非常有挑战的一件事,因为骑手在送餐交付到用户手中时会碰到不同的问题,例如:骑手一次送餐给楼宇内多个用户,骑手对于特定楼宇寻址特别困难,骑手在交付楼宇附近只能步行,老旧小区没有电梯,写字楼无法上楼,或者难以等到电梯等等。交付时间预估需要具备刻画交付难度的能力,在定价、调度等多个场景中被广泛使用。例如根据交付难度来确定是否调节骑手邮资,根据交付难度来确定是否调节配送运单的顺序,从而避免超时等等。总的来说,交付时间预估是配送业务基础服务的重要一环。
但是,交付时间预估存在如下的困难:
- 输入信息较少,且多为非数值型数据,目前能够被用来预估的仅有如下维度特征:交付地址、交付点的经纬度、区域、城市,适配常规机器学习模型需要重新整理且容易丢失信息。
- 计算性能要求很高。由于是基础服务,会被大量的服务调用,需要性能TP99保证在10ms以内,整个算法平均响应时间需要控制在5ms内,其中包括数据处理及RPC的时间。且该标准为CPU环境下的性能要求,而非GPU下的性能要求。

上图为部分版本所对应的性能,平响时间均在5ms内,TP99基本在10ms内
总结起来,交付时间预估的问题,在于需要使用轻量级的解决方案来处理多种数据形式的非数值型数据,并提取有效信息量,得到相对准确的结果。在相同效果的前提下,我们更倾向于性能更优的方案。
在本文中,我们介绍了交付时间预估迭代的三个版本,分别为基于地址结构的树模型、向量召回方案以及轻量级的End-to-End的深度学习网络。同时介绍了如何在性能和指标之间取舍,以及模型策略迭代的中间历程,希望能给从事相关工作的同学们有所启发和帮助。
2. 技术迭代路径
首先,在交付时间预估的技术迭代上,我们主要经历了三个大版本的改动,每一版本在5ms计算性能的约束下,追求轻量化的解决方案,在兼顾提升效果的基础上,不显著增加性能的消耗。
本章节分别叙述了3个模型的迭代路径,包括技术选型、关键方案及最终效果。
2.1 树模型
技术选型
最早也是最容易被考虑到的是利用规则,核心思路是利用树结构衡量地址相似性,尽可能在相似的交付地址上积聚结构化数据,然后利用局部的回归策略,得到相对充裕的回归逻辑,而未能达到回归策略要求的则走兜底的策略。
为了快速聚积局部数据,树模型是一个较为合适的解决方案,树的规则解析能够有效地聚集数据,同时一个层级并不深的树,在计算速度上,具备足够的优势,能够在较短的时间内,得到相对不错的解决方案。
观察用户填写地址以及联系实际中地址的层级结构,不难发现,一个地址可以由四级结构组成:地址主干词(addr)、楼宇号(building)、单元号(unit)、楼层(floor)。其中的地址主干词在实际中可能对应于小区名或者学校名等地标名称。例如望京花园1号楼2单元5楼,解析为(望京花园,1号楼,2单元,5楼)。通过分析,实际交付时长与楼层高低呈正相关关系,且不同交付地址的交付时长随楼层增加的变化幅度也有所区别,所以可以使用线性回归模型拟合楼层信息和交付时长的关系,而地址主干词、楼宇号、单元号作为其层级索引。但用户填写的地址中并不一定包含完整的四级结构,就会存在一定比例的缺失,所以利用这样的层级结构构建成一棵树,然后充分利用上一层已知的信息进行预估。预测时,只需根据结点的分支找到对应的模型即可,如果缺失,使用上一层结构进行预测。对于没有达到训练模型要求数据量的地址,使用其所在的区域平均交付时长作为交付时长的预估结果,这部分也可以看作区域信息,作为树结构的根节点。
迭代路径
整体的思路是基于离散特征训练树模型,在树的结点上基于楼层训练线性回归模型。树结点训练分裂规则:(1)数据量大于阈值;(2)分裂后MAE(平均绝对误差)的和小于分裂前。考虑到数据的时效性,采用加权线性回归增加近期数据的权重。
2.2 树模型+向量召回方案
技术选型
向量召回作为主流的召回方案之一,被业界广泛使用,在使用LSH、PQ乘积量化等常用开源工具基础上,高维向量召回性能通常在毫秒量级。
而从算法上考虑,树模型中NLP地址解析结果能够达到模型使用要求的仅为70%+,剩余20%+的地址无法通过训练得到的模型从而只能走降级策略。利用高维向量来表达语义相似性,即利用向量来表达地址相似性,从而用相似数据对应的模型来替代相似但未被召回数据,将地址主干词进行Embedding后,摆脱主干词完全匹配的低鲁棒性。
例如,在地址上可能会出现【7天酒店晋阳街店】数据量比较充足,但【7天连锁酒店太原高新区晋阳街店】数据量不充足从而无法训练模型的案例,这可能是同一个交付位置。我们希望尽可能扩大地址解析的成功率。
迭代路径
整个技术路径较为清晰简单,即利用Word2Vec将charLevel字符进行Embedding,获得该地址的向量表示,并且融入GPS位置信息,设计相应兜底策略。
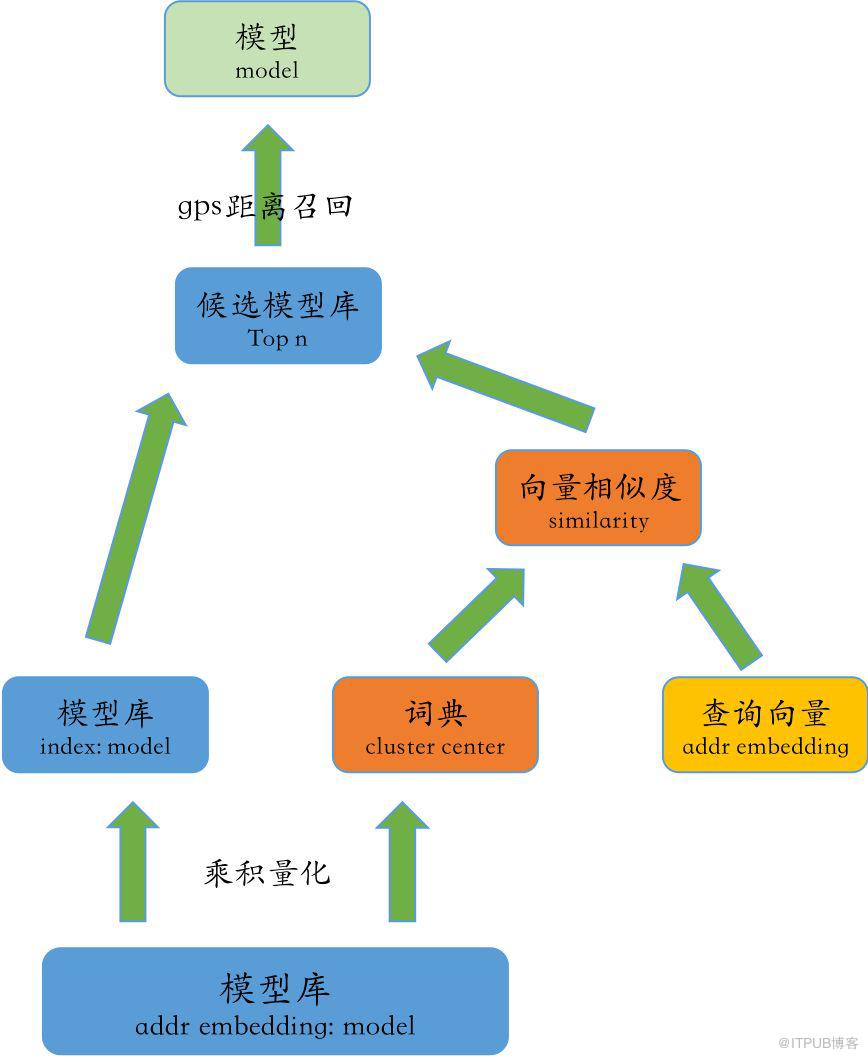
向量召回方案决策路径
最终效果
比较大地提升了整体策略的召回率,提升了12.20pp,对于未被上一版本树模型召回的地址,指标有了显著的提升,其中ME下降87.14s,MAE下降38.13s,1min绝对偏差率减小14.01pp,2min绝对偏差率减小18.45pp,3min绝对偏差率减小15.90pp。
2.3 End-to-End轻量化深度学习方案
技术选型
在树模型的基础上,迭代到向量召回方案,整个模型的召回率有了较大幅度的增长,但仍然不是100%。分析发现,召回率提升的障碍在于NLP对于地址解析的覆盖率。
整个方案的出发点:
从模型复杂度考虑,同样仅仅使用地址信息的话,在提升模型VC维的基础上,使用其他的模型方案至少可以持平树模型的效果,如果在这基础上还能融入其他信息,那么对于原模型的基线,还能有进一步的提升。
考虑到不仅仅需要使用地址数据,同时需要使用GPS数据、大量ID类的Embedding,对于各类非数值类型的处理灵活性考虑,采用深度学习的方案,来保证多源且多类型特征能在同一个优化体系下优化学习。
工程上需要考虑的点:
交付模型作为基础模型,被广泛应用在路径构造、定价、ETA等各个业务中频繁调用,在树模型版本中,对于性能的要求为平均响应时间5ms,TP99在10ms左右,本方案需要考虑沿袭原业务的性能,不能显著增加计算耗时。
交付模型的难点在于非数值型特征多,信息获取形式的多样化,当前的瓶颈并不在于模型的复杂度低。如果可以轻量地获取信息及融合,没必要对Fusion后的信息做较重的处理方案。
所以整体的设计思路为:利用深度学习融合非数值型特征,在简单Fusion的基础上,直接得到输出结构,对于组件的选择,尽可能选用Flops较低的设计。该设计背后意图是,在充分使用原始输入信息,在尽可能避免信息损失的基础上,将非数值型的信息融入进去。并将信息充分融合,直接对接所需要的目标。而选用的融合组件结构尽可能保证高性能,且具备较高学习效率。这里分别针对地址选用了较为Robust的LSTM,针对GPS选用了自定义的双线性Embedding,兼顾性能和效果。
迭代路径
开始采用端到端的深度学习模型,这里首先需要解决的是覆盖率问题,直接采用LSTM读取charLevel的地址数据,经过全连接层直接输出交付时间。作为第一版本的数据,该版本数据基本持平树模型效果,但对于树模型未召回的20%数据,有了较大的提升。
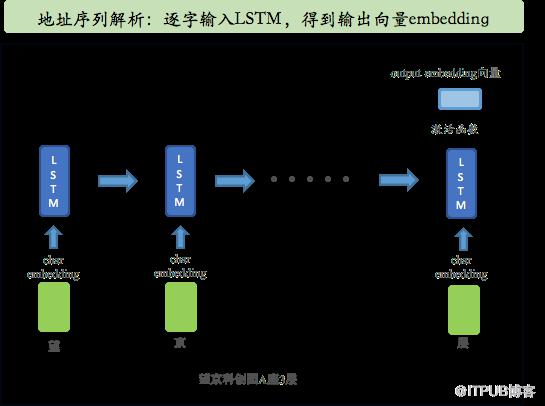
地址信息输入charLevel模型
在采用charLevel的地址奏效后,我们开始采用加入用户地址GPS的信息,由于GPS为经纬度信息,非数值型数据,我们使用一种基于地理位置格点的双线性插值方法进行Embedding。该方案具备一定的扩展性,对不同的GPS均能合理得到Embedding向量,同时具备平滑特性,对于多对偏移较小的GPS点能够很好的进行支持。
最终方案将地址Embedding后,以及GPS点的Embedding化后,加入下单时间、城市ID、区域ID等特征后,再进行特征融合及变换,得到交付模型的时间预估输出。整个模型是一个端到端的训练,所有参数均为Trainable。
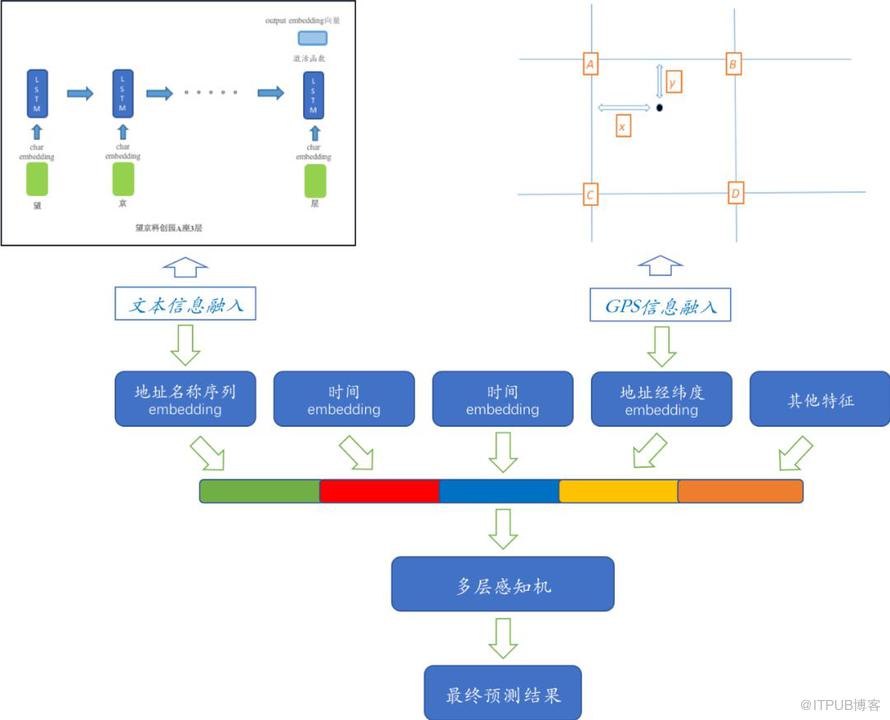
模型结构示意图
扩展组件
在证实End-to-End路径可行后,我们开始进行扩展组件建设,包括自定义损失函数、数据采样修正、全国模型统一等操作,得到一系列正向效果,并开发上线。
特征重要性分析
对于深度学习模型,我们有一系列特征重要性评估方案,这里采用依次进行Feature Permutation的方式,作为评估模型特征重要性的方式。
考虑GPS经纬度和用户地址存在较大程度的信息重叠,评估结果如下。Shuffle后,用户地址的特征重要性高于GPS经纬度的特征重要性。加入GPS后ME下降不如地址信息明显,主要是地址信息包含一定冗余信息(下文会分析),而其他信息的影响则可以忽略不计。
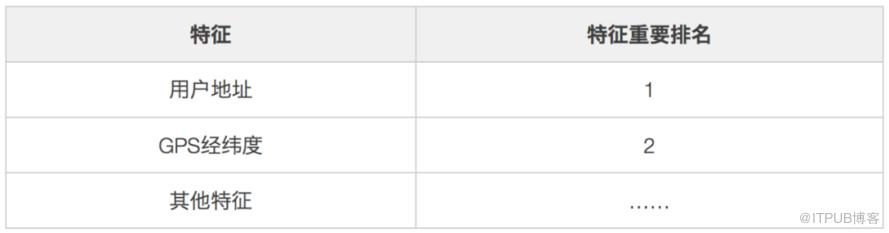
注:在配送的其他案例中,商户GPS的经纬度重要性>>用户地址重要性>>用户GPS的经纬度重要性,该特征重要性仅仅为本案例特征重要性排序,不同学习目标下可能会有比较明显差别。
最终效果
End-to-End深度学习模型的最终效果较为显著:对于树模型及向量召回方案的最痛点,覆盖率得到彻底解决,覆盖率提升到100%。ME下降4.96s,MAE下降8.17s,1min绝对偏差率减小2.38pp,2min绝对偏差率减小5.08pp,3min绝对偏差率减小3.46pp。同时,对于之前树模型及向量召回方案未能覆盖到的运单,提升则更为明显。
3. 模型相关分析
在整个技术迭代的过程中,由于整个解决方案对于性能有着较为苛刻的要求,需要单独对方案性能进行分析。本章节对向量召回方案及深度学习方案进行了相应的性能分析,以便在线下确认性能指标,最终保证上线后性能均达到要求。下文分别着重介绍了向量匹配的工具Faiss以及TensorFlow Operation算子的选取,还有对于整体性能的影响。
同时对比End-to-End生成向量与Word2Vec生成向量的质量区别,对于相关项目具备一定的借鉴意义。
3.1 向量召回性能
最近邻搜索(Nearest Neighbor Search)指的是在高维度空间内找到与查询点最近点的问题。在数据样本小的时候,通过线性搜索就能满足需求,但随着数据量的增加,如达到上百万、上亿点时候,倾向于将数据结构化表示来更加精确地表达向量信息。
此时近似最近邻搜索ANN(Approximate Nearest Neighbor)是一个可参考的技术,它能在近似召回一部分之后,再进行线性搜索,平衡效率和精度。目前大体上有以下3类主流方法:基于树的方法,如K-D树等;基于哈希的方法,例如LSH;基于矢量量化的方法,例如PQ乘积量化。在工业检索系统中,乘积量化是使用较多的一种索引方法。
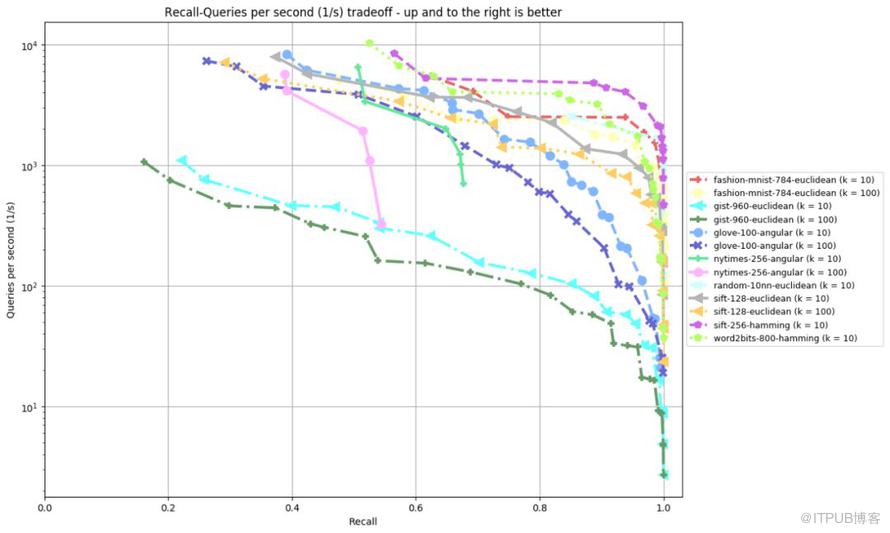
针对向量召回的工具,存在大量的开源实现,在技术选型的过程中,我们参照ANN-Benchmarks以及Erikbern/ANN-Benchmarks中的性能评测结果。在众多ANN相关的工具包内,考虑到性能、内存、召回精度等因素,同时可以支持GPU,在向量召回方案的测试中,选择以Faiss作为Benchmark。
Faiss是FaceBook在2017年开源的一个用于稠密向量高效相似性搜索和密集向量聚类的库,能够在给定内存使用下,在速度和精度之间权衡。可以在提供多种检索方式的同时,具备C++/Python等多个接口,也对大部分算法支持GPU实现。
下图为Faiss测评曲线:
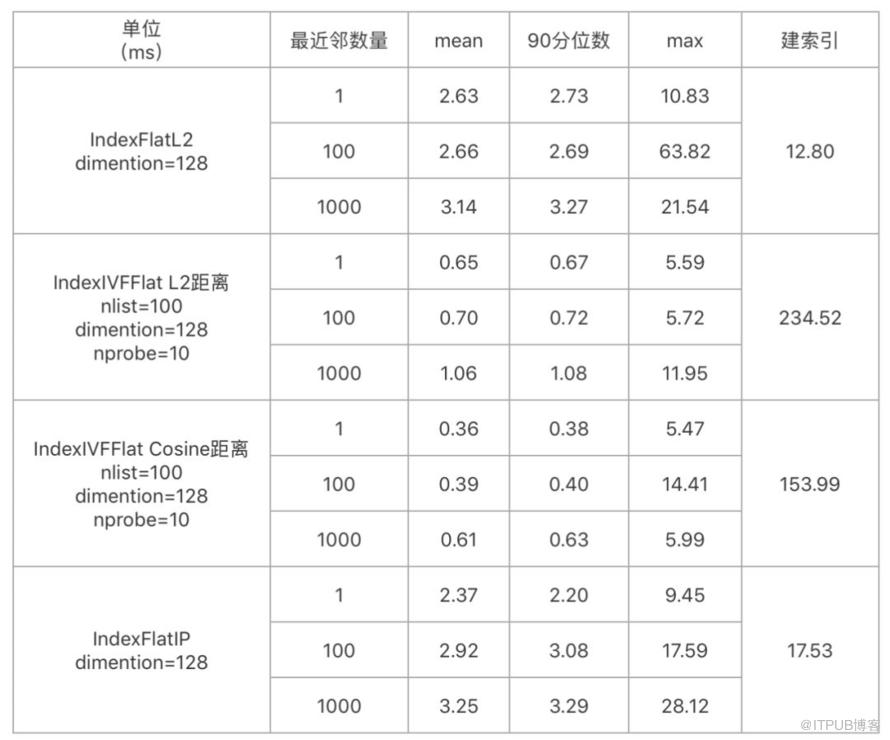
交付时间模型召回的性能测试如下,可以达到性能需求。
- 召回候选集数量:8W条向量【由于采用了GPS距离作为距离限制,故召回测试采用8W数量级】。
- 测试机器:Mac本机CPU【CPU已满足性能,故不再测试GPU】。
3.2 序列模块性能
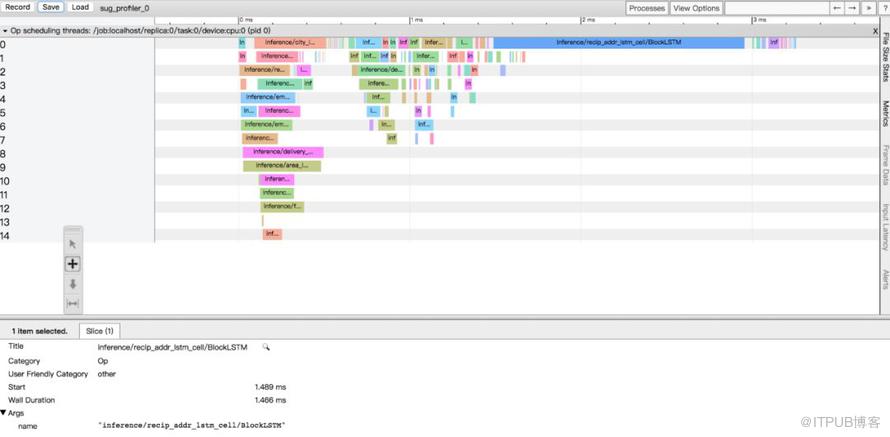
在TensorFlow系统中,以C API为界限,将系统划分为【前端】和【后端】两个子系统,前端扮演Client角色,完成计算图的构造,然后由Protobuf发送给后端启动计算图计算。计算图的基础单元是OP,代表的是某种操作的抽象。在TensorFlow中,考虑到实现的不同,不同OP算子的选择,对于计算性能具有较大影响。
为了评测深度学习交付模型的性能瓶颈,首先对整个模型进行Profile,下图即为Profile后的Timeline,其中整个计算大部分消耗在序列模块处理部分,即下图中的蓝色部分。故需要对序列模块的计算性能进行OP算子的加速。
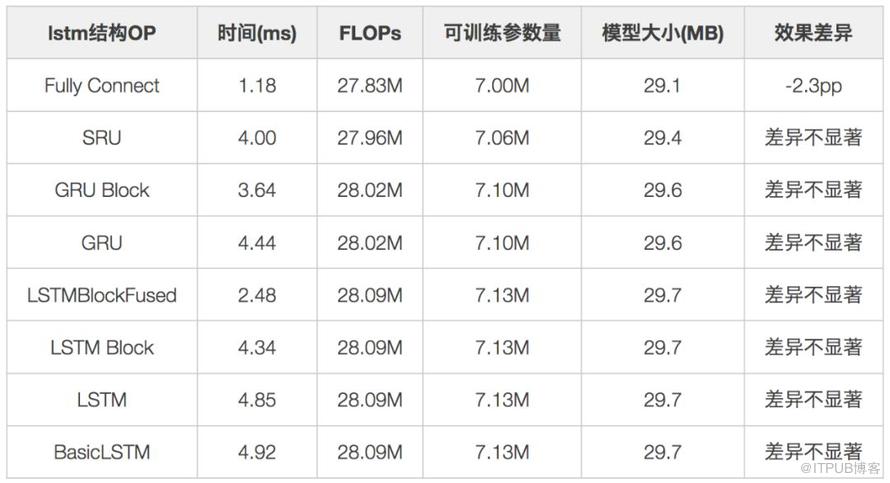
考虑到序列处理的需求,评估使用了LSTM/GRU/SRU等模块,同时在TensorFlow中,LSTM也存在多种实现形式,包括BasicLSTMCell、LSTMCell、LSTMBlockCell、LSTMBlockFusedCell和CuDNNLSTM等实现,由于整个交付模型运行在CPU上,故排除CuDNNLSTM,同时设置了全连接层FullyConnect加入评估。
从评估中可以发现,全连接层速度最快,但是对于序列处理会损失2.3pp效果,其余的序列模型效果差异不大,但不同的OP实现对结果影响较大。原生的BasicLSTM性能较差,contrib下的LSTMBlockFusedCell性能最好,GRU/SRU在该场景下未取得显著优势。
这是LSTMBlockFusedCell的官方说明,其核心实现是将LSTM的Loop合并为一个OP,调用时候整个Timeline上更为紧凑,同时节约时间和内存:
This is an extremely efficient LSTM implementation, that uses a single TF op for the entire LSTM. It should be both faster and more memory-efficient than LSTMBlockCell defined above.
以下是序列模块的性能测试:
- 环境:Tensorflow1.10.0,CentOS 7。
- 测试方法:CPU inference 1000次,取最长的地址序列,求平均时间。
- 结论:LSTMBlockFused实现性能最佳。【FullyConnect性能最快,但对性能有损失】
注:在评估中,不仅仅包括了序列模型,也包括了其他功能模块,故参数量及模型大小按照总体模型而言
3.3 向量效果分析
将向量召回与深度学习模型进行横向比较,二者中间过程均生成了高维向量。不难发现,二者具备一定的相似性,这里就引发了我们的思考:
- 相较于向量召回,深度学习模型带来的提升主要来自于哪里?
- 有监督的lstm学习到的Embedding向量与自监督的Word2Vec得到的向量在地址相似性计算中有多大差别,孰优孰劣?
首先,我们分析第一个问题,End-to-End模型提升主要来自哪里?
我们直接将End-to-End模型得到的char embedding抽取出来,直接放入到Word2Vec方案内,取代Word2Vec生成的char embedding,再进行向量召回的评估。结果如下表所示,单独抽取出来的char embedding在向量召回方案中,表现与Word2Vec生成的向量基本一致,并没有明显的优势。

注:
- 1min绝对偏差率定义:|pred-label|<=60s
- 2min绝对偏差率定义:|pred-label|<=120s
- 3min绝对偏差率定义:|pred-label|<=180s
此时的变量有2个方面:
- 对于charLevel地址的学习结构不同,一个为Word2Vec,一个为LSTM。
- 输入信息的不同,Word2Vec的信息输入仅仅为地址主干词,而End-to-End的信息输入则包括了地址主干词、地址附属信息、GPS等其他信息。
注:
- 完整地址:卓玛护肤造型(洞庭湖店) (洞庭湖路与天山路交叉路口卓玛护肤造型)
- 地址主干词:卓玛护肤造型店
- 地址附属信息:(洞庭湖店)(洞庭湖路与天山路交叉路口卓玛护肤造型)
为了排除第二方面的因素,即b的因素,使用地址主干词作为输入,而不用地址附属信息和其他模型结构的输入,保持模型输入跟Word2Vec一致。在测试集上,模型的效果比完整地址有明显的下降,MAE增大约15s。同时将char embedding提取出来,取代Word2Vec方案的char embedding,效果反而变差了。结合2.3节中的特征重要性,可知,深度学习模型带来的提升主要来自对地址中冗余信息(相较于向量召回)的利用,其次是多个新特征的加入。另外,对比两个End-to-End模型的效果,地址附属信息中也包含着对匹配地址有用的信息。

针对第二个问题,有监督的End-to-End学习到的Embedding向量,与自监督的Word2Vec得到的向量在地址相似性计算中有多大差别,孰优孰劣?
采用地址主干词代替完整地址,作为End-to-End模型的输入进行训练,其他信息均保持不变。使用地址主干词训练得到的Embedding向量,套用到向量召回方案中。
从评估结果来看,对于不同的阈值,End-to-End的表现差异相对Word2Vec较小。相同阈值下,End-to-End召回率更高,但是效果不如Word2Vec。
从相似计算结果看,End-to-End模型会把一些语义不相关但是交付时间相近的地址,映射到同一个向量空间,而Word2Vec则是学习一个更通用的文本向量表示。
例如,以下两个交付地址会被认为向量距离相近,但事实上只是交付时间相近:
南内环西街与西苑南路交叉口金昌盛国会<=>辰憬家园迎泽西大街西苑南路路口林香斋酒店
如果想要针对更为复杂的目标和引入更多信息,可以使用End-to-End框架;只是计算文本相似性,从实验结果看,Word2Vec更好一些。同时,通过查看Case也可以发现,End-to-End更关注结果相似性,从而召回一部分语义上完全不相关的向量。两个模型目标上的不同,从而导致了结果的差异。
4. 总结与展望
在本篇中,依次展示了在配送交付场景下的三次模型策略迭代过程,以及在较为苛刻性能要求限制下,如何用轻量化的方案不断提高召回率及效果。同时,对迭代过程中的性能进行简单的分析及衡量,这对相关的项目也具备一定的借鉴意义,最后对Word2Vec及End-to-End生成的向量进行了比较。
事实上,本文中提及的向量召回及深度学习融合非数值型特征的方案,已经在业界被广泛使用。但对于差异化的场景,本文仍具备一定的借鉴价值,特别是对于订单-骑手匹配、订单-订单匹配等非搜索推荐领域的场景化应用,以及TF OP算子的选用及分析、Embedding生成方式带来的差异,希望能够给大家提供一些思路和启发。
5. 关联阅读
交付时间预估与ETA预估及配送其他业务关系:
- 交付时间预估是ETA预估中的重要一环,关于ETA预估,请参见《深度学习在美团配送ETA预估中的探索与实践》。
- 具体ETA在整个配送业务中的位置及配送业务的整体机器学习实践,请参看《机器学习在美团配送系统的实践:用技术还原真实世界》。
6. 作者介绍
基泽,美团点评技术专家。
闫聪,美团点评算法工程师。