
在1 部分中, 我研究了数据环境的编写信息, 这是 HR 数据的样本, 然后通过比较熊猫库和 SQL 来对数据做一些简单的查询。对于本文中的示例, 我们首先 meed 1 部分所述设置环境。
在这里, 我将继续通过重写与熊猫的查询来提供更复杂的 SQL 查询。SQL 查询有6部分, 即;
- 选择: 用于选择所有列或选定列。
- 自: 用于包含所需的数据集。
- WHERE: 用于定义数据集之间的联接或筛选数据 (在某些语法中, 联接是在 from 子句中定义的, 其中联接关键字如内部联接、外部联接等)。
- 分组使用: 用于聚合属性列以计算聚合的度量。
- 有: 用于筛选聚合的度量值。
- 排序依据: 用于定义所需列的排序。
SELECT <column or columns> /*[1]*/
FROM <table or tables> /*[2]*/
WHERE <join> or <filters> /*[3]*/
GROUP BY <aggregate column or columns> /*[4]*/
HAVING BY <aggregate column filter> /*[5]*/
ORDER BY <sort column or columns> /*[6]*/在本文中, 程序示例将介绍如何筛选数据。
按值筛选
SQL 版本
SELECT * FROM EMPLOYEES
WHERE MANAGER_ID = 100
AND DEPARTMENT_ID = 90输出为:

熊猫版
它可以用四种不同的语法编写, 如下所示, 它们都提供相同的输出数据;
employees_filtered_v1 = employees[(employees.MANAGER_ID == 100) & (employees.DEPARTMENT_ID == 90)]
employees_filtered_v1
#Or
employees_filtered_v2 = employees.query('MANAGER_ID == 100 & DEPARTMENT_ID == 90')
employees_filtered_v2
#Or
employees_filtered_v3 = employees[(employees['MANAGER_ID'] == 100) & (employees['DEPARTMENT_ID'] == 90)]
employees_filtered_v3
#Or
#Using Boolean values
manager_id = employees['MANAGER_ID'] == 100
department_id = employees['DEPARTMENT_ID'] == 90
employees_filtered_v4 = employees[manager_id & department_id]
employees_filtered_v4下面显示的输出与我们在 SQL 代码段中得到的结果相同。

在上面的示例中, “and” 运算符用于筛选与这两个条件匹配的数据。但是, 如果要在 SQL 查询和熊猫脚本中使用 “or” 运算符, 请分别使用 “or” 和 ” | ” (管道)。
筛选 null 和非 null 值
SQL 版本
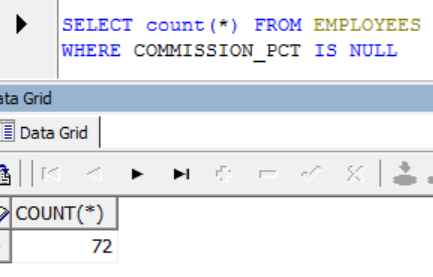
SELECT * FROM EMPLOYEES
WHERE COMMISSION_PCT IS NULL“雇员” 表的结果为72个记录。
熊猫版
employees[employees.COMMISSION_PCT.isnull()].count()[1]
SQL 版本
SELECT * FROM EMPLOYEES
WHERE COMMISSION_PCT IS NOT NULL“雇员” 表的结果为35条记录cheeli/wp-内容/上传/2018/10/10372334-countnotnullsql. png 宽度 = “236”/>
熊猫版
employees[employees.COMMISSION_PCT.notnull()].count()[1]此代码的结果为:

联接两个数据集
有时需要加入两个数据集。可以联接具有不同联接类型的数据集。SQL 中有四种不同类型的联接, 它可应用于具有相同逻辑的熊猫数据帧。这些是:
- 内部联接
- 左/右联接
- 完全外部联接
下面的示例是内部联接示例。在我们的熊猫版本中, 您可以通过设置合并函数的参数来更改联接类型。
1. 左外联接:
how='left'2. 右外联接
how='right'3. 完全外部联接
how='outer'SQL 版本
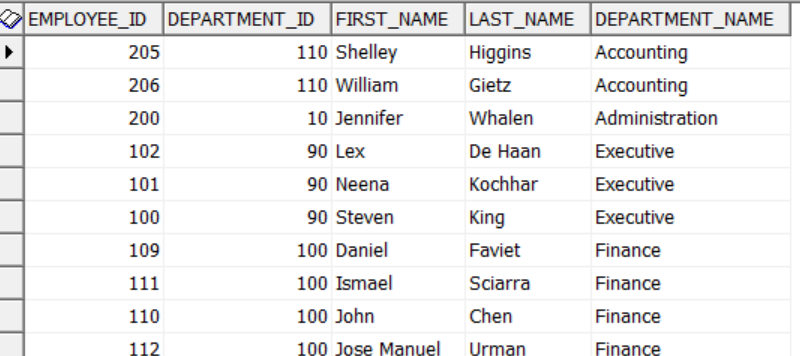
SELECT
e.employee_id, e.department_id,
e.first_name, e.last_name,
d.DEPARTMENT_NAME
FROM
employees e,
departments d
WHERE e.department_id = d.department_id
order by department_name, first_name , last_name输出为:
熊猫版
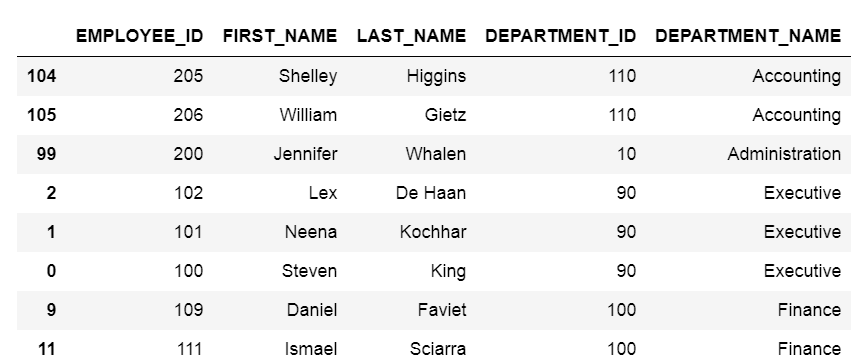
employees_departments = pd.merge(
employees[['EMPLOYEE_ID', 'FIRST_NAME', 'LAST_NAME', 'DEPARTMENT_ID']],
departments[['DEPARTMENT_ID', 'DEPARTMENT_NAME']],
on = 'DEPARTMENT_ID')
employees_departments输出为:
本文介绍了联接和筛选。

