
对于我们中的许多人来说,EDA 可能只是意味着深入数据,并在基础数据中找到一些初始模式和趋势。它还可能意味着在变量之间建立相关性,以整理一些有趣的见解。
然而,作为数据分析实践者,有一件事不能忽视,它可能会把我们的数据梦变成一场噩梦,那就是数据卫生或数据质量。因此,在我看来,数据质量、描述、形状、模式和关系将完成 EDA 周期。
让我们从各种 Python 命令的角度来了解 EDA 过程,这些命令不仅展示了工作量,还指明了与单行代码相比的复杂性级别,即 pandas_profiling.ProfileReport() 使数据分析和 EDA 处理变得轻而易举。

熊猫分析 Python 包是创建 HTML 分析报告的绝佳工具。对于给定的数据集,它计算以下统计信息:
- 要点:类型、唯一值、缺失值。
- 分位数统计信息,如最小值、Q1、中位数、Q3、最大值、范围、四分位数范围。
- 描述性统计,如均值、模式、标准偏差、总和、中位数绝对偏差、变异系数、峰度、偏斜度。
- 最常见的值。
- 直方图。
- 高度相关变量、斯皮尔曼和皮尔逊矩阵的相关性突出显示。
先决条件:
- 安装 Python 和 Jupyter 笔记本
- 安装熊猫分析模块
如何在虚拟数据集上使用熊猫分析包
创建新笔记本后(我使用 Google colab 环境运行所有 Python 模块和库),我们需要:
- 加载熊猫和熊猫分析
- 进口熊猫作为pd
- 进口熊猫_分析
- 将数据加载到数据帧中

3. 运行熊猫配置文件 report 的命令:
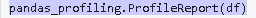
4. 显示数据分析报告:
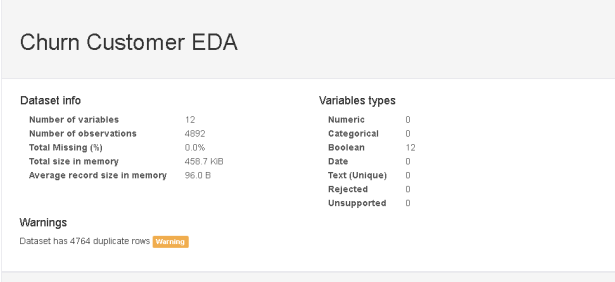
以上只是快照 – 此报告还有更多内容!
您可以在 GitHub页面上查看完整的 EDA 分析。
用户还可以将此报告导出为 HTML 格式,并可以与较大的受众共享。

数据分析是数据分析对数据源内容的系统预先分析,从计算字节和检查基数到对数据能否满足数据仓库的高级目标的最周到的诊断。-
拉尔夫·金鲍尔