

纳米神经
NanoNeuron是神经网络中神经元概念的一个过度简化版本。NanoNeuron 经过训练可将温度值从摄氏度转换为华氏度。
NanoNeuron.js代码示例包含 7 个简单的 JavaScript 函数(模型预测、成本计算、向前和向后传播、训练),这些函数将让您了解机器如何真正”学习”。没有第三方库,没有外部数据集和依赖项,只有纯和简单的 JavaScript 函数。
这些功能不是机器学习的完整指南。大量的机器学习概念被跳过和过度简化在那里!这种简化是为了让读者对机器如何学习有一个真正基本的理解和感觉,并最终使读者能够称之为”机器学习 MAGIC”,而是”机器学习 MATH”。
您可能还需要阅读:
从程序员的角度设计Java中的神经网络
纳米神经学将学到什么
你可能听说过神经网络中的神经元。我们将在下面实现的 NanoNeuron 有点像神经网络,但简单得多。为简单起见,我们甚至不会在 NanoNeuron 上构建网络。我们将有这一切本身做一些”神奇”的预测为我们。也就是说,我们将教这个简单的纳米神经转换温度从摄氏度到华氏度。
顺便说一下,将摄氏度转换为华氏度的公式是:

但是现在,我们的纳米神经不知道…
纳米神经模型
让我们实现我们的纳米神经元模型函数。它实现了 和 之间的基本线性依赖关系 x y ,如下所示 y = w * x + b 。简单地说,我们的NanoNeuron是一个”孩子”,可以在坐标中画直线 XY 。
变量 w b 是模型的参数。NanoNeuron只知道线性函数的这两个参数。这些参数是 NanoNeuron 在训练过程中要”学习”的内容。
NanoNeuron 唯一能做的就是模仿线性依赖性。在其 predict() 方法中,它接受一些输入 x 并预测输出 y 。这里没有魔法
function NanoNeuron(w, b) {
this.w = w;
this.b = b;
this.predict = (x) => {
return x * this.w + this.b;
}
}(…等。。。线性回归…是你吗?
摄氏度 到 华氏度 转换器
温度值(以摄氏度为单位)可以使用以下公式转换为华氏度:f = 1
function celsiusToFahrenheit(c) {
const w = 1.8;
const b = 32;
const f = c * w + b;
return f;
};最终,我们想教我们的NanoNeuron模仿这个函数(学习 w = 1.8 和 b = 32 ),而事先不知道这些参数。
这是摄氏度到华氏度的转换函数的外观:

生成数据集
培训前,我们需要根据功能生成训练和测试数据集 celsiusToFahrenheit() 。数据集由输入值对和正确标记的输出值组成。
在大多数情况下,将收集这些数据,而不是生成这些数据。例如,我们可能有一组手绘数字和相应的数字集,用于解释每张图片上写的数字。
我们将使用训练数据示例来训练我们的 NanoNeuron。在 NanoNeuron 能够独立成长和做出决策之前,我们需要使用培训示例来教导它什么是正确和错误。
我们将使用 TEST 示例来评估我们的 NanoNeuron 在培训期间未看到的数据上的表现。这是我们可以看到,我们的”孩子”已经成长,可以自己做决定。
function generateDataSets() {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [];
const yTrain = [];
for (let x = 0; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTrain.push(x);
yTrain.push(y);
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [];
const yTest = [];
// By starting from 0.5 and using the same step of 1 as we have used for training set
// we make sure that test set has different data comparing to training set.
for (let x = 0.5; x < 100; x += 1) {
const y = celsiusToFahrenheit(x);
xTest.push(x);
yTest.push(y);
}
return [xTrain, yTrain, xTest, yTest];
}预测的成本(误差)
我们需要一个指标,该指标将显示模型的预测与校正值的接近程度。使用以下公式计算 正确的输出值 y 和 NanoNeuron 之间的成本(错误): prediction
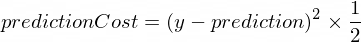
这是两个值之间的简单区别。值越接近,差异越小。我们使用 2 这里的力量只是为了去除负数,这样与 相同 (1 - 2) ^ 2 (2 - 1) ^ 2 。划分 2 只是为了简化进一步的向后传播公式(见下文)。
在这种情况下,成本函数将非常简单,例如:
function predictionCost(y, prediction) {
return (y - prediction) ** 2 / 2; // i.e. -> 235.6
}正向传播
执行正向传播意味着对来自和数据集的所有训练示例进行预测, xTrain yTrain 并计算这些预测沿途的平均成本。
我们只是让我们的NanoNeuron有它的意见在这一点上,只是问他如何转换温度平均成本将显示我们的模型现在是多么错误。这个成本值是非常有价值的,因为通过更改 NanoNeuron 参数 w b ,并且通过再次执行正向传播,我们将能够评估 NanoNeuron 在参数更改后是否变得更聪明。
将使用以下公式计算平均成本:
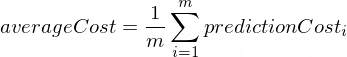
m一些培训示例在哪里(在我们的例子中是 100 )。
以下是如何在代码中实现它:
function forwardPropagation(model, xTrain, yTrain) {
const m = xTrain.length;
const predictions = [];
let cost = 0;
for (let i = 0; i < m; i += 1) {
const prediction = nanoNeuron.predict(xTrain[i]);
cost += predictionCost(yTrain[i], prediction);
predictions.push(prediction);
}
// We are interested in average cost.
cost /= m;
return [predictions, cost];
}向后传播
现在,当我们知道 NanoNeuron 的预测(基于此时的平均成本)如何正确或错误时,我们应该怎么做才能使预测更加精确?
向后传播是这个问题的答案。反向传播是评估预测成本和调整 NanoNeuron 参数的过程 w b ,以便下一个预测更加精确。
在这里,机器学习看起来像魔法。这里的关键概念是导数,它显示了要采取哪些步骤来接近成本函数的最小值。
请记住,找到成本函数的最小值是培训过程的最终目标。如果我们发现这些值 w b ,并且我们的平均成本函数将很小,则意味着 NanoNeuron 模型会做出非常精确的预测。
衍生工具是一个单独的主题,我们将在本文中不介绍。MathIsFun是获得基本理解的良好资源。
关于导数,它将帮助您理解向后传播的工作原理,即从它的意义上,导数是函数曲线的一条切线,指出函数最小方向。

图像来源:数学
例如,在上面的图中,您可以看到,如果我们在比 (x=2, y=4) 斜率告诉我们去 left 并 down 达到最小函数的点时。还要注意,斜率越大,我们应该移动到最小。
参数函数的导数 averageCost w b 如下所示:
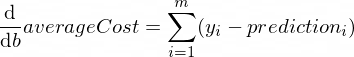
m一些培训示例在哪里(在我们的例子中是 100 )。
function backwardPropagation(predictions, xTrain, yTrain) {
const m = xTrain.length;
// At the beginning we don't know in which way our parameters 'w' and 'b' need to be changed.
// Therefore we're setting up the changing steps for each parameters to 0.
let dW = 0;
let dB = 0;
for (let i = 0; i < m; i += 1) {
dW += (yTrain[i] - predictions[i]) * xTrain[i];
dB += yTrain[i] - predictions[i];
}
// We're interested in average deltas for each params.
dW /= m;
dB /= m;
return [dW, dB];
}训练模型
现在,我们知道如何评估模型对于所有训练集示例的正确性(正向传播),并且我们也知道如何对参数 w 和 b NanoNeuron 模型(向后传播)进行小调整。但问题是,如果我们只向前传播,然后向后传播一次,那么我们的模型就不足以从训练数据中学习任何规律/趋势。你可以把它比作一个孩子上小学的一天。他/她应该不是一次,而是日复一日地去学校学习一些东西。
因此,我们需要多次重复模型的向前和向后传播。这正是 trainModel() 函数的作用。它就像我们的纳米神经模型的”老师”:
- 它将花费一些时间
epochs()与我们但有点愚蠢的纳米神经模型,并尝试训练/教导它 - 它将使用特定的”书籍”(
xTrain和yTrain数据集)进行培训 - 它将推动我们的孩子学习更努力(更快)通过使用学习速率参数
alpha
关于学习速度的几句话 alpha 。这只是一个乘数 dW , dB 我们在向后传播期间计算的值。因此,衍生物指出了我们需要的方向,以找到成本函数的最小( dW 和 dB 符号),并指出我们需要多快地去这个方向( dW 和 dB 绝对值)。现在,我们需要将这些步长大小相乘 alpha ,以使我们的移动更快或更慢。有时,如果我们使用 一个很大的值 alpha ,我们可能只是跳过最小值,却永远找不到它。
与老师的类比是,他越努力地推动我们的”纳米孩子”,我们的”纳米孩子”学习得越快,但如果老师推得太狠,”孩子”就会神经衰弱,无法学到任何东西。
以下是我们将如何更新模型 w 和 b 参数:


以下是我们的培训师功能:
function trainModel({model, epochs, alpha, xTrain, yTrain}) {
// The is the history array of how NanoNeuron learns(让纪元 = 0;纪元 < 纪元 = 1) |
转发传播。
const [预测,成本] = 转发传播(模型、xTrain、yTrain);
成本历史.推送(成本);
向后传播。
康斯特 [dW, dB] = 向后传播(预测,xTrain,yTrain);
调整我们的 NanoNeuron 参数,以提高模型预测的精度。
纳米Neuron.w = α = dW;
纳米Neuron.b = α = dB;
}
退货成本历史记录;
}
把所有的碎片放在一起
现在,让我们使用上面创建的函数。
让我们创建我们的纳米神经模型实例。此时,NanoNeuron 不知道应该为参数和 设置什么值 w b 。因此,让我们设置 w 和 b 随机。
const w = Math.random(); // i.e. -> 0.9492
const b = Math.random(); // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron(w, b);生成培训和测试数据集。
const [xTrain, yTrain, xTest, yTest] = generateDataSets();让我们 0.0005 在纪元期间用小 ( ) 步骤来训练模型 70000 。您可以玩这些参数,它们是根据经验定义的。
const epochs = 70000;
const alpha = 0.0005;
const trainingCostHistory = trainModel({model: nanoNeuron, epochs, alpha, xTrain, yTrain});让我们检查一下成本函数在培训期间的变化情况。我们预计培训后的费用应该比以前低很多。这意味着纳米神经变得更智能。反之亦然。
console.log('Cost before the training:', trainingCostHistory[0]); // i.e. -> 4694.3335043
console.log('Cost after the training:', trainingCostHistory[epochs - 1]); // i.e. -> 0.0000024这就是培训成本在纪元期间的变化。轴上 x 是纪元号 x1000。
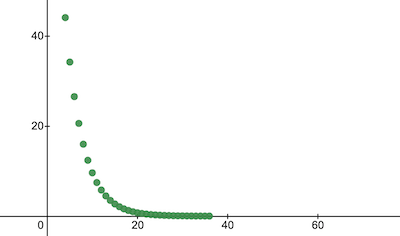
让我们来看看NanoNeuron参数,看看它学到了什么。我们期望NanoNeuron参数和 w b 我们在 celsiusToFahrenheit() 函数(和)上的参数相似, w = 1.8 b = 32 因为我们的纳米神经试图模仿它。
console.log('NanoNeuron parameters:', {w: nanoNeuron.w, b: nanoNeuron.b}); // i.e. -> {w: 1.8, b: 31.99}评估测试数据集的模型准确性,了解我们的 NanoNeuron 处理新的未知数据预测的能力。测试集的预测成本预计将接近培训成本。这意味着 NanoNeuron 在已知和未知数据上表现良好。
[testPredictions, testCost] = forwardPropagation(nanoNeuron, xTest, yTest);
console.log('Cost on new testing data:', testCost); // i.e. -> 0.0000023现在,自从我们看到我们的NanoNeuron”孩子”在训练中在”学校”中表现良好,他可以正确地将摄氏度转换到华氏度——即使是它没有看到的数据——我们可以称之为”聪明”,并问他一些问题。这是整个培训过程的最终目标。
const tempInCelsius = 70;
const customPrediction = nanoNeuron.predict(tempInCelsius);
console.log(`NanoNeuron "thinks" that ${tempInCelsius}°C in Fahrenheit is:`, customPrediction); // -> 158日志(”正确答案是:’,摄氏温度(温度)”-> 158
太近了!作为所有人类,我们的纳米神经是好的,但不是理想的:)
祝你学习愉快!
如何启动纳米神经
您可以克隆存储库并在本地运行它:
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.js跳过机器学习概念
为了简化解释,跳过并简化了以下机器学习概念。
训练/测试集拆分
通常,您有一组大型数据。根据该集中的示例数,您可能希望将其拆分为 70/30 的比例,以用于训练/测试集。拆分之前,应随机随机排列集中的数据。如果示例数量很大(即数百万个),则对于火车/测试数据集,拆分的比例可能接近 90/10 或 95/5。
网络带来力量
通常,你不会注意到只使用一个独立神经元。能量在这样的神经元网络中。网络可能会学习更复杂的功能。NanoNeuron 本身看起来更像是一个简单的线性回归,而不是神经网络。
输入规范化
在培训之前,最好对输入值进行规范化。
矢量化实现
对于网络,矢量化(矩阵)计算比循环工作快得多 for 。通常,如果以矢量化形式实现并使用Numpy Python 库等计算,则向前/向后传播工作速度要快得多。
成本函数的最小值
我们在此示例中使用的成本函数过于简单化了。它应该有对数组件。更改成本函数也会更改其导数,因此反向传播步骤也将使用不同的公式。
激活功能
通常,神经元的输出应通过激活函数,如Sigmoid或ReLU或其他。