
在《写数据库同时发mq消息事务一致性的一种解决方案》一文的方案中把分布式事务巧妙转成了数据库事务。我们都知道关系型数据库事务能保证数据一致性,那数据库到底是怎么设计事务这一特性的呢?
一、MySQL事务模型ACID
MySQL是一个多引擎数据库,其中InnoDB支持数据库事务,也是最常用的引擎。下边就介绍InnoDB的事务模型
MySQL官方文档对事务是这么描述的“事务是可以提交或回滚的原子工作单元。当事务对数据库进行多个更改时,要么提交事务时所有更改都成功,要么回滚事务时撤消所有更改。”
“ACID模型是一组数据库设计原则,强调业务数据和关键应用程序的可靠性很重要。MySQL包含与ACID模型紧密结合的innodb存储引擎组件,确保数据不会被破坏,结果不会被软件崩溃和硬件故障等异常情况所篡改。当您依赖ACID的特性,就不再需要重新发明一致性检查和崩溃恢复机制。”
ACID模型按照字母拆解分为四大特性
A : atomicity 原子性。原子性是我们对事务最直观的理解:事务就是一系列的操作,要么全部都执行,要么全部都不执行。
C : consistency 一致性。数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款和不变。
I : isolation 隔离性。在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
D : durability 持久性。只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
二、InnoDB存储引擎架构
下边这张图是InnoDB的架构,包括两大部分,内存结构(In-Memory Structures)和磁盘上的结构(On-Disk Structures)。
在这张图中,尤其要关注“Redo Log”和“Undo Tablespaces”这两个区域,它们跟事务息息相关。
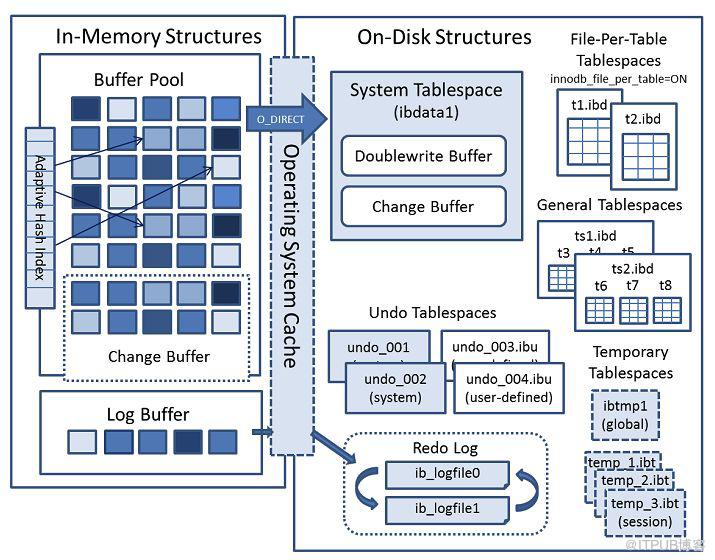
内存结构(In-Memory Structures)更多的目的是在提高性能,因此本文不会过多关注。如果感兴趣,可以访问MySQL的官方网站www.mysql.com
“Undo Tablespaces”包含Undo Log(撤消日志),Undo Log是撤消日志记录的集合,其中包含如何撤消事务对聚集索引记录的最新更改的信息。Undo Log存在于撤消日志段中,这些日志段包含在回滚段中。
MySQL事务的四个特性中ACD三个特性是通过Redo Log(重做日志)和Undo Log 实现的,而 I(隔离性)是通过Lock(锁)来实现。
三、普及个概念MVCC
MVCC,Multi-Version Concurrency Control,多版本并发控制。这项技术使得InnoDB的事务隔离级别下执行一致性读操作有了保证,换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值。这是一个可以用来增强并发性的强大技术,查询不用等待另一个事务释放锁。这项技术广泛应用于数据库,例如Oracle,PostgreSQL。当然也有一些数据库产品以及mysql的其它存储引擎不支持它。
看一看MVCC机制的示意图,图下边会给出文字解释
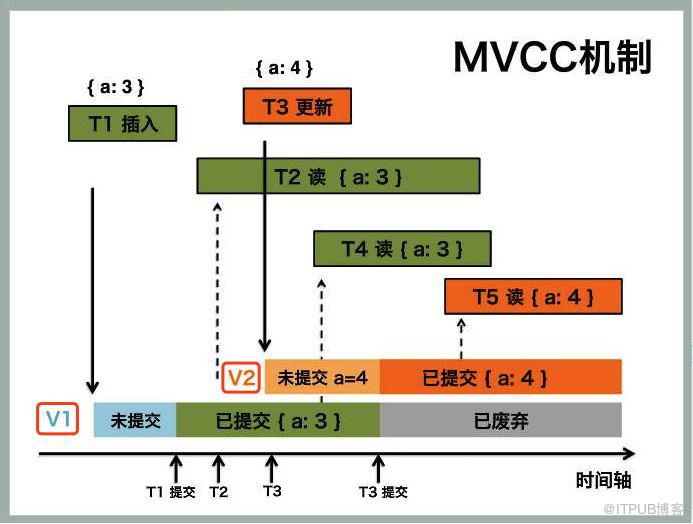
图中底部横轴是时间,纵向的箭头用来标记增、删、改、查发生的时刻。尤其注意时间轴上方两条色块,代表数据的两个版本V1、V2。为了醒目,我把V1、V2用红色方框圈了起来(多版本的体现)。从左向右解读这张图
1、T1事务插入数据a=3,然后提交,生成了数据对应的V1版本
2、T2事务开始读取a数据,读取会持续一段时间,由于开始读取的时刻,只有V1版本,所以最终T2读到a=3
3、T2读取过程中,T3对数据a进行修改,a=4,生成a数据的V2版本,但此时并未提交,因此生效的是V1版本数据。
4、T3修改提交之前,T4读取a数据,由于此时V1版本数据生效,因此,T4读到a=3
5、T3提交a=4的修改,V1版本数据失效,V2生效。a的值变为4
6、T5读取a的值,读到V2版本,a=4
至此,MVCC的概念就搞明白了,那么MySQL是怎么实现的呢?
四、InnoDB多版本的实现
1、三个隐藏字段
在内部,InnoDB向数据库中存储的每一行数据添加三个字段。
(1)DB_TRX_ID字段,6字节。表示插入或更新行的最后一个事务的事务标识符。此外,删除在内部被视为更新,其中行中的特殊位被设置为将其标记为已删除。
(2)DB_ROLL_PTR字段,7字节,叫做回滚指针(roll pointer)。回滚指针指向写入回滚段的撤消日志(Undo Log)。如果行已更新,则撤消日志包含重建更新前该行内容所需的信息。
(3)DB_ROW_ID字段,6字节。包含一个随着新行插入而单调增加的行ID,如果innodb自动生成聚集索引,则该索引包含行ID值。否则,DB_ROW_ID列不会出现在任何索引中。
2、多版本产生过程
以新增一条记录并对该记录进行2次修改来说明具体实现
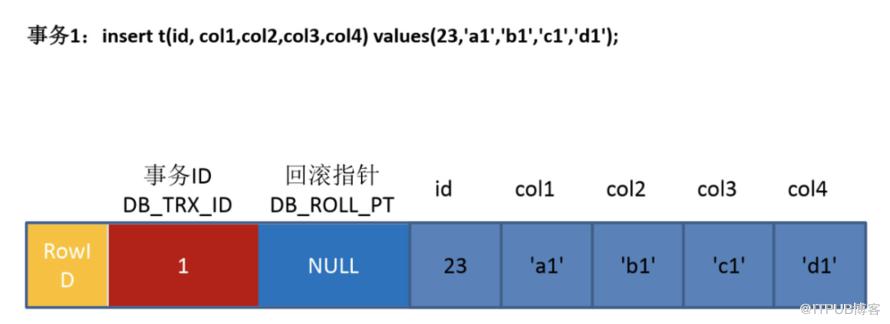
这条记录有3个隐含字段(前面已经介绍),分别应对行的ID、事务号和回滚指针。
当插入的是一条新数据时,记录上对应的回滚段指针为NULL
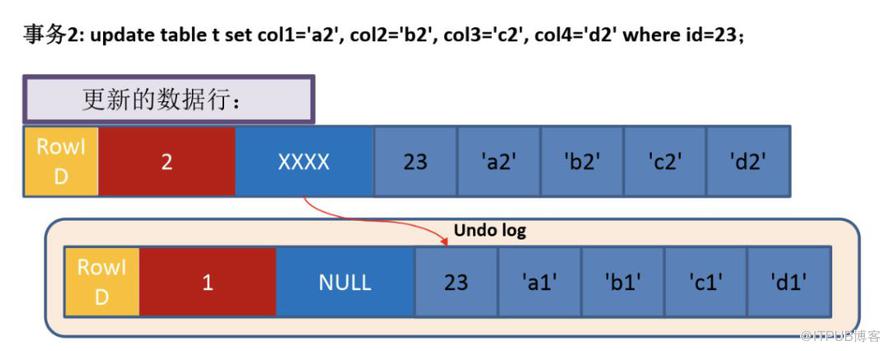
这个过程做了以下几件事
- 用排他锁锁定该行
- 把该行修改前的值拷贝到Undo Log中
- 修改当前行的值,填写事务编号,使回滚指针指向Undo Log中的修改前的行
- 记录Redo Log,包括Undo Log中的变化
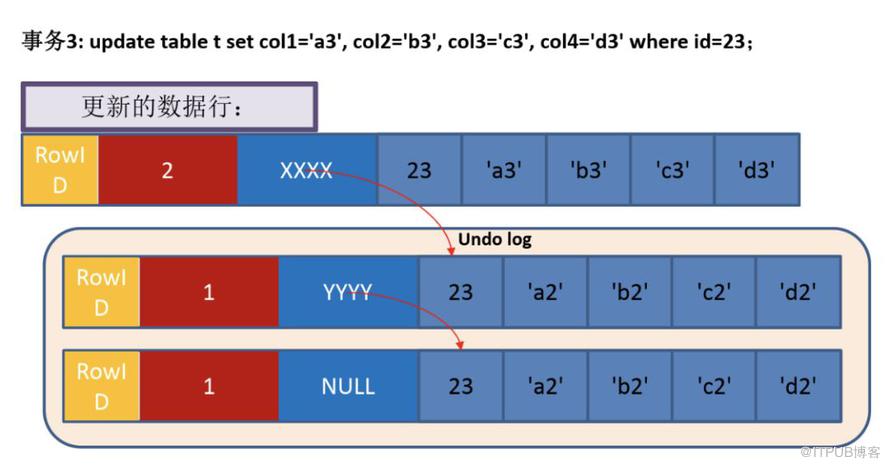
多次更新后,回滚指针会把不同版本的记录串在一起。在InnoDB中存在purge线程,它会查询那些比现在最老的活动事务还早的Undo Log,并删除它们,从而保证Undo Log文件不至于无限增长。
3、提交与回滚
当事务正常提交时,InnoDB只需要更改事务状态为commit即可,不需要做其他额外的工作
回滚(rollback)需要根据当前回滚指针从Undo Log中找出事务修改前的版本,并恢复。如果事务影响的行非常多,回滚则可能会很慢,根据经验值没提交的事务行数在1000~10000之间,InnoDB效率还是非常高的(唐成-数据库多版本实现内幕)。
commit效率高,rollback代价大
4、可见性
事务隔离是数据库处理的基础之一,隔离是缩写ACID中的I。隔离级别是当多个事务同时进行更改和执行查询时,微调性能、可靠性、一致性和结果再现性之间的平衡的设置。
InnoDB提供SQL1992标准定义的四个隔离级别,READ UNCOMMITTED(未提交读), READ COMMITTED(已提交读), REPEATABLE READ(可重复读), and SERIALIZABLE(可串行化)。默认的是REPEATABLE READ
每种隔离级别具体的意义可以百度查到,实现原理深入进去比较复杂。注意到每条数据隐藏的事务ID字段DB_TRX_ID有时序性,理论上可以根据一些策略,借助这个字段来实现与隔离级别相关的功能。事实上InnoDB也是这么做的。当然这个功能还涉及很多锁的问题,这里不再展开。
MySQL官方文档在“锁和事务模型”这一章节开始就介绍了InnoDB的锁,截个目录,感兴趣可以去读一下。
