
1 问题现象
最近,腾讯云某内部系统不定期出现数据库访问行更新慢,数据库用户线程大量堆积的现象。从slow log中观察,大量update执行时间超过10秒,甚至个别update执行时间超过百秒,这已经严重影响该系统的正常运行。
运维同学不得不采取杀死运行session的方式解决该问题,由于访问数据库的任务是离线后台批处理任务,因此会选择业务压力小的时候运行该任务,比如半夜12点,因此,运维同学必须半夜采取紧急措施,这给线上运行造成极大的负担。
2 问题分析
2.1 山重水复
根据运维同学反馈,数据库是不定期出现慢查询的现象,怀疑数据库可能存在死锁问题。由于问题复现的不确定性,因此在线上实例写脚本抓现场:当问题出现时,记录下innodb引擎状态(show innodb status)、用户线程状态,innodb引擎状态信息中存在死锁信息。遗憾的是,通过对innodb status分析,发现LATEST DETECTED DEADLOCK中不存在死锁问题,初步排除偶发死锁导致问题的可能,只能从业务模型角度寻找思路。
2.2 峰会路转
通过与业务系统开发、运维人员的沟通,发现有三个业务子系统会访问该数据库,这三个子系统访问模式类似,整理该业务模型如下图所示:

每一个离线请求都会触发上述流程,对同一个id的行短时间内有多次更新,如果等锁超时会重试,会重试十次。在极端场景,叠加重试请求,会有2000+线程同时更新数据库,造成大量连接等待现象。对热点行更新会加行锁,行锁在事务提交时释放,释放后唤醒其他线程继续更新,正常情况下热点行更新会降低数据库吞吐但不会产生数十秒的事务等待,因此怀疑加锁、释放锁、唤醒其他线程的某些环节有问题,导致大并发的极端情况下数据库性能严重下降。
2.3 柳暗花明
由于抽象出了出问题时的业务模型,按照该业务模型基本可以复现问题,因此搭建线下环境,用pt-pmp、perf等工具分析数据库问题。经过对pt-pmp仔细分析,发现部分线程等待异常,如下图所示:
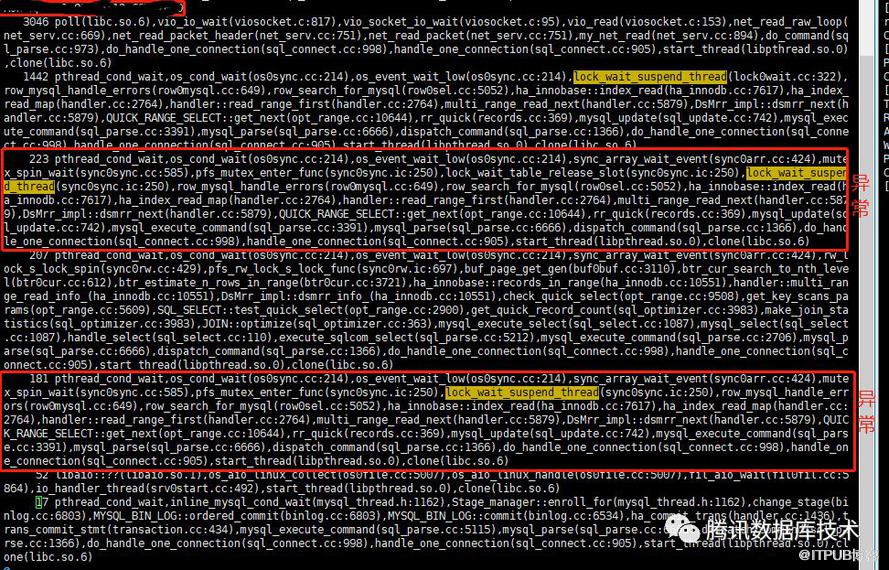
上图中1442个线程等待唤醒,这个是正常的,但有图上标出的2组异常线程:
- 233个线程等待lock_wait_suspend_thread中的lock_wait_table_release_slot的入口mutex上
- 181个线程等待lock_wait_suspend_thread本身的mutex上。
经过代码分析,这两个mutex为lock_wait_mutex_enter(),这把锁出现在两个地方中:
- 用户线程调用的lock_wait_suspend_thread
- 后台线程:lock_wait_timeout_thread
lock_wait_suspend_thread函数让所有调用线程进入suspend状态,挂起。当热点行更新时,只有一个线程更新其他所有线程都挂起等待行锁,因此在热点行更新时,这个函数是热点。图中的1442个线程就是在等待行锁唤醒。
lock_wait_timeout_thread是锁超时监测线程,监测是否有线程等锁超时,该线程会扫描每一个由lock_wait_suspend_thread进入等待的线程,判断其是否超时,如果有超时,唤醒。触发机制有2种:
- 每秒定时触发
- lock_wait_suspend_thread通知触发,这个就是热点行更新慢的关键!
lock_wait_suspend_thread与lock_wait_timeout_thread关系如下图所示:
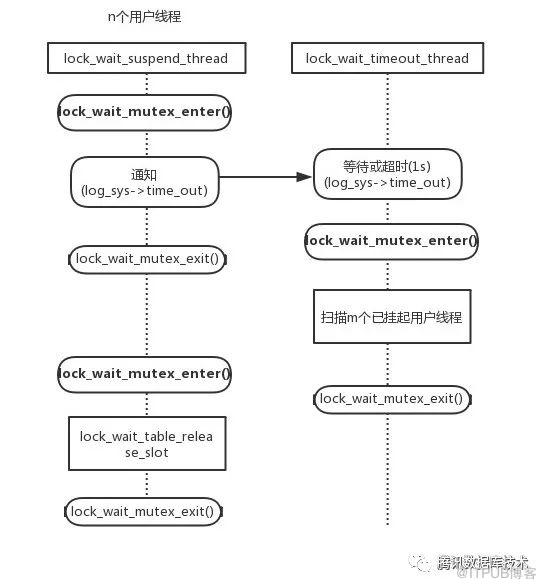
每增加n个进入等待进程,其中的每一个进程都会触发一次lock_wait_timeout_thread,而每一次lock_wait_timeout_thread调用都会对m个已经挂起线程持锁扫描,这样多出n * m次持锁扫描。由于持锁扫描会进一步加剧用户线程等待在lock_wait_suspend_thread入口锁lock_wait_mutex_enter()的等待,造成更多触发lock_wait_timeout_thread线程的机会,单次运lock_wait_timeout_thread时间增加,那个进入恶性循环,所有线程都在争夺lock_wait_mutex_enter()锁。
3 问题解决
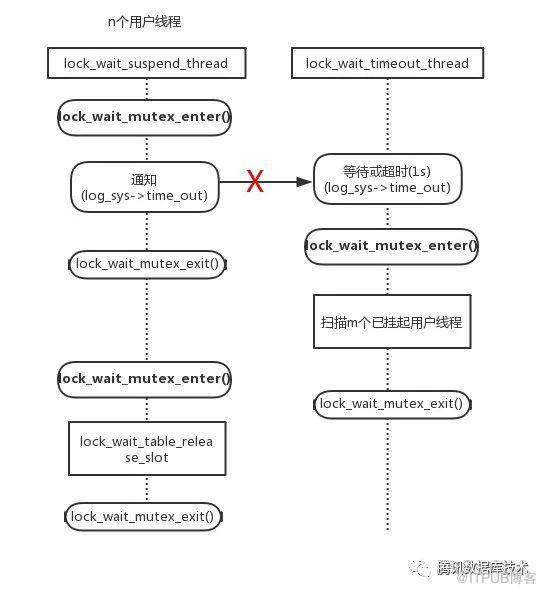
阻断lock_wait_suspend_thread 对lock_wait_timeout_thread触发,如下图所示:lock_wait_suspend_thread 对lock_wait_timeout_thread的调用,是用来加速监测锁超时等待的,去掉该调用,减少大压力并发的热点行更新对lock_wait_timeout_thread的调用,进而减小lock_wait_suspend_thread 锁等待,进而消除热点。
4 结果
业务模拟工具按照线上业务模型,模拟线上运行2000个业务请求同时进行,每秒每个请求更新一次,分析每个访问的执行时间(对binlog扫面得到执行时间(exec_time)得出执行时间)
用模拟业务的测试工具对改前、改后版本进行测试,结果如下:执行时间5.6优化前5.6优化后
| 所有 | 6968 | 32460 |
| 1-9 | 1504(占比21.6%) | 802(2.47%) |
| >10 | 12(占比0.17%) | 0 |
从效果上看,优化后的热点基本消失,5.6延迟(1-9s)的占比,优化后是优化前的十分之一,基本解决热点问题。查看ptpmp堆栈如下所示:
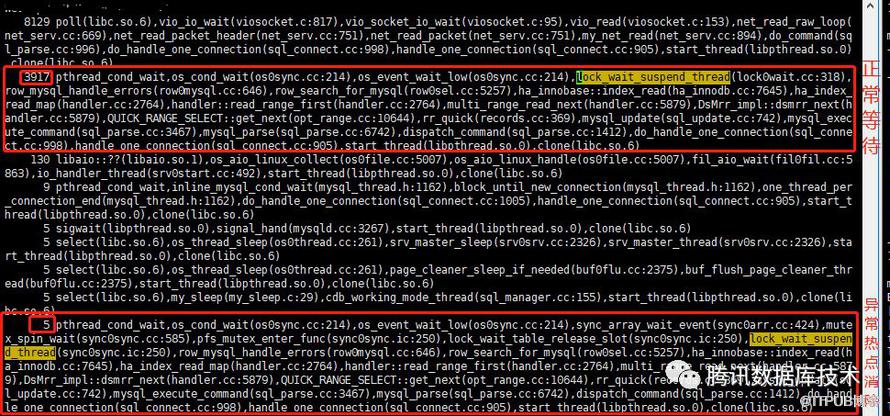
由图可见,大部分线程被挂起,等在lock_wait_suspend_thread上的slot->event上面,这是一个正常的行为。之前的热点消失,只有5个线程等在入口锁上面。该修复随着最新的txsql 5.6发布线上,经过近一个月的线上运行,腾讯云的线上业务没有再出现更新慢的问题,基本确认问题已经解决。