
“Mixtral-8x7B大型语言模型 (LLM) 是一种预训练的生成式稀疏专家混合体。”
当我看到它出现时,它看起来非常有趣且易于理解,所以我尝试了一下。如果有适当的提示,看起来不错。对于我的用例,我不确定它是否比 Google Gemma、Meta LLAMA2 或 OLLAMA Mistral 更好。
今天我将向您展示如何将新的 Mixtral LLM 与 Apache NiFi 结合使用。只需几个步骤即可针对您的文本输入运行 Mixtral。
<图名称=“d56a”>

此模型可以由轻量级无服务器 REST API 或转换器库运行。您还可以使用 此 GitHub 存储库。上下文最多可以有 32k 个令牌。您还可以用英语、意大利语、德语、西班牙语和法语输入提示。关于如何利用此模型,您有很多选择,但我将向您展示如何利用 Apache NiFi 构建实时 LLM 管道。
需要决定的一个关键事情是您将获得什么样的输入(聊天、代码生成、问答、文档分析、摘要等)。一旦你决定了,你将需要做一些提示工程并需要调整你的提示。在下面的部分中,我提供了一些指南来帮助您提高提示构建技能。我将在我的演练教程中为您提供一些基本的提示工程。
优化提示的指南
提示符的构建对于使其顺利运行非常关键,因此我们使用 NiFi 构建它。
流程概述
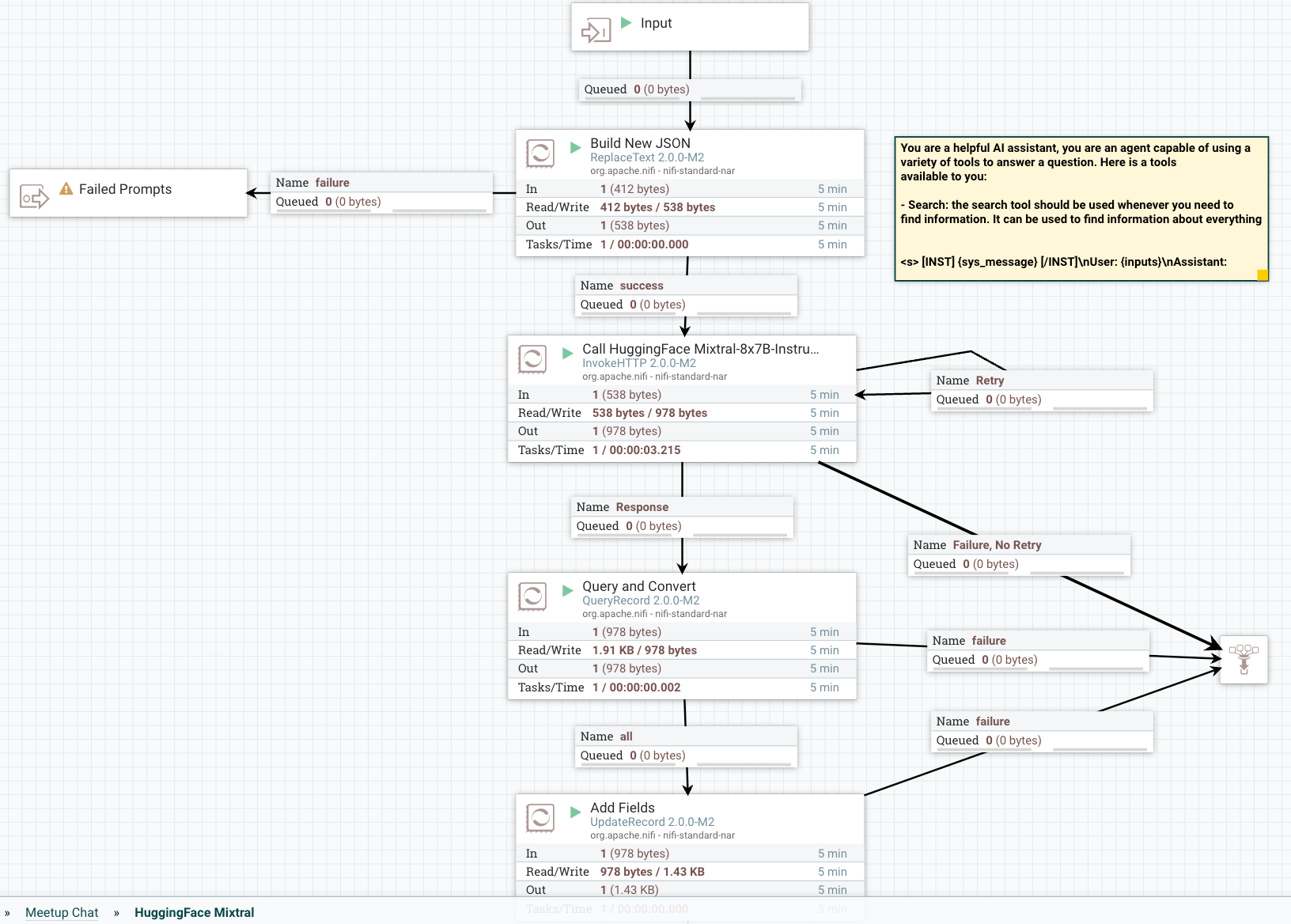
第 1 步:构建并设置提示格式
在构建我们的应用程序时,以下是我们将使用的基本提示模板。
提示模板
{
“输入”:
“[INST]写出详细、完整的回应,并适当地
回答请求。[/INST]
[INST]使用此信息来增强您的答案:
${context:trim():replaceAll('"',''):replaceAll('\n', '')}[/INST]
用户:${inputs:trim():replaceAll('"',''):replaceAll('\n', '')}"
}
<图名称=“d500”>
您将在 ReplaceText 处理器的替换值字段中输入此提示。
![输入替换值]()
第 2 步:构建对 HuggingFace REST API 的调用以根据模型进行分类
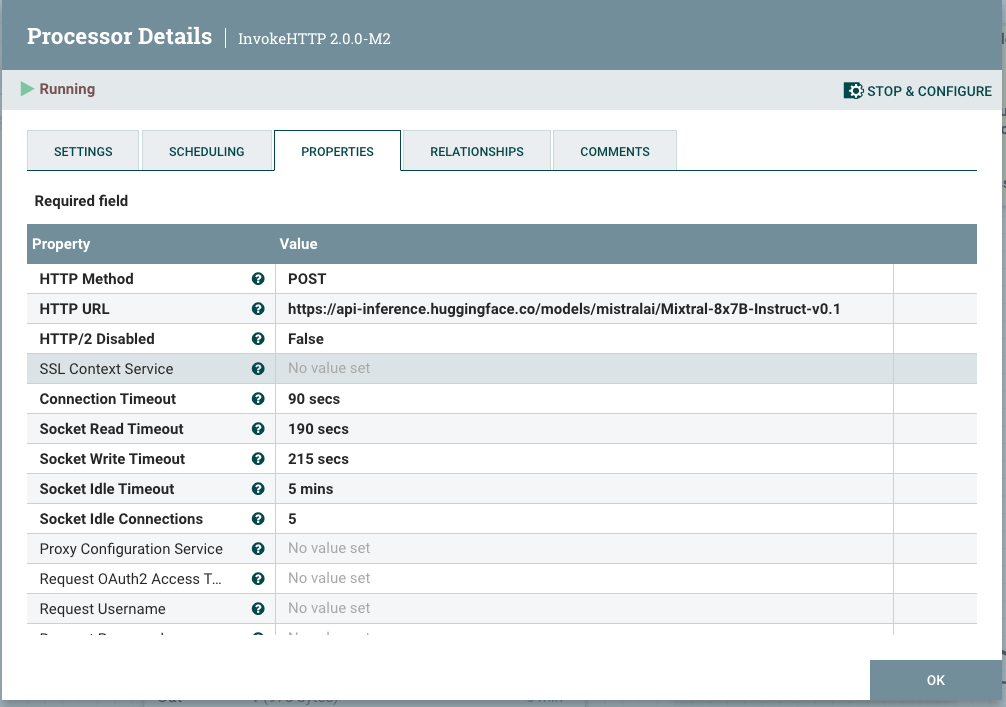
向您的流程添加一个InvokeHTTP处理器,将HTTP URL设置为Mixtral API URL。
![向流程中添加 InvokeHTTP 处理器,将 HTTP URL 设置为 Mixtral API URL]() 第 3 步: 查询以转换和清理结果
第 3 步: 查询以转换和清理结果
我们使用 QueryRecord 处理器来清理和转换抓取 generated_text 字段的 HuggingFace 结果。

第 4 步:添加元数据字段
我们使用 UpdateRecord 处理器添加元数据字段、JSON 读取器和写入器以及文字值替换值策略。 我们添加的字段正在添加属性。
![使用 UpdateRecord 处理器添加元数据字段、JSON 读取器和写入器以及文字值替换值策略。]()
发送到 Kafka 和 Slack 的概述:
![发送到 Kafka 和 Slack 的概述]()
第 5 步:将元数据添加到流
我们使用UpdateAttribute处理器添加正确的“application/json内容类型”,并将模型类型设置为Mixtral。
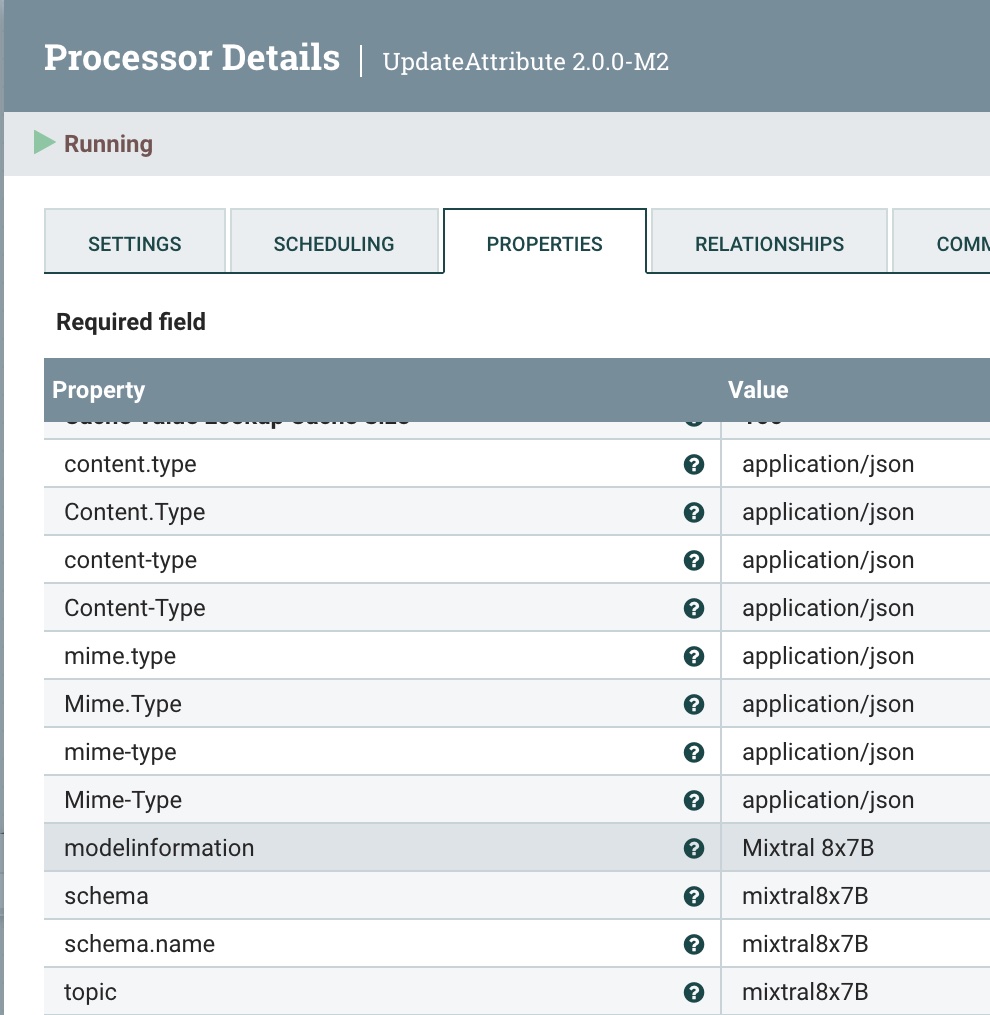
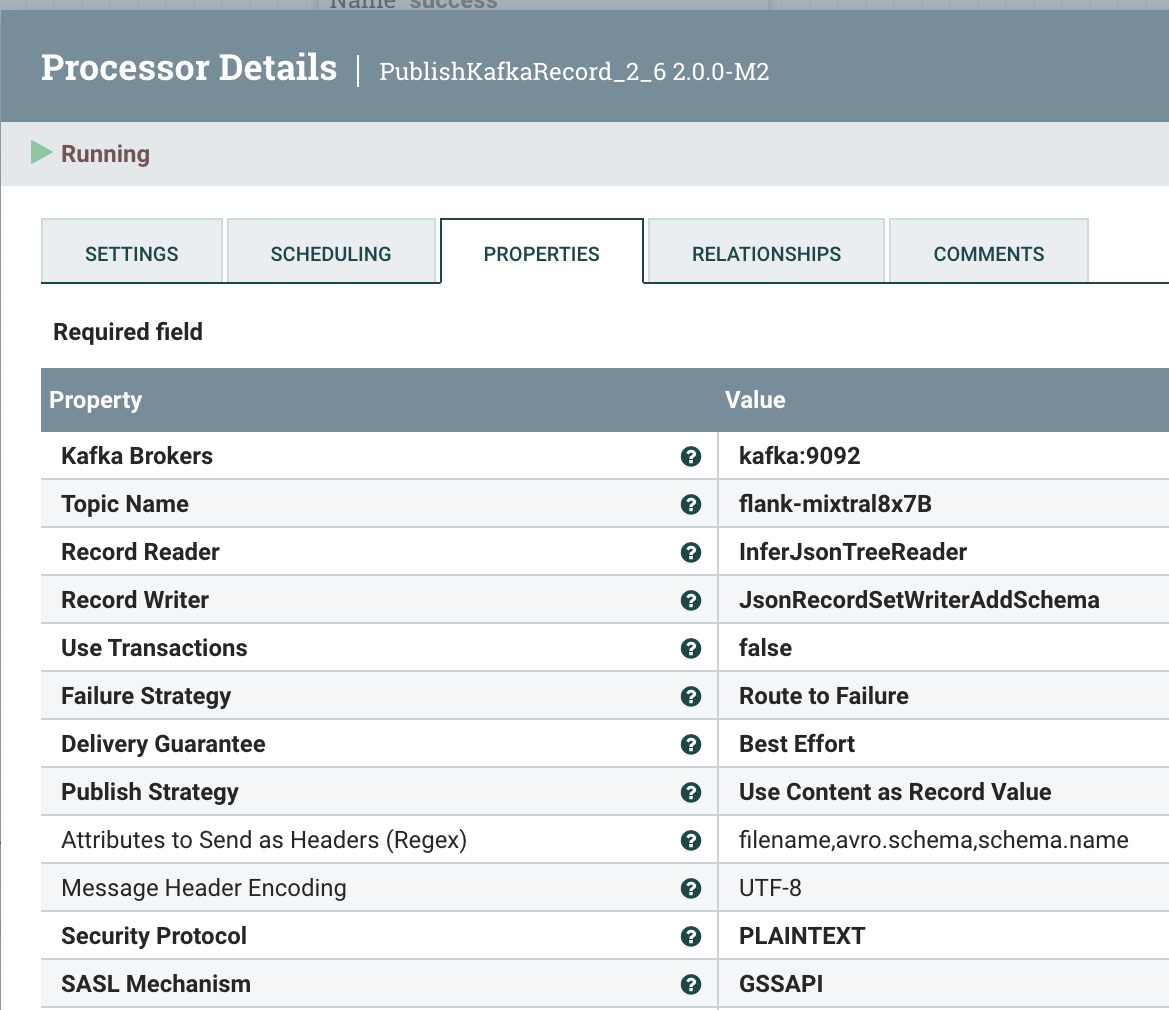
第 6 步:将此清理后的记录发布到 Kafka 主题
我们将其发送到本地 Kafka 代理(可以是 Docker 或其他)和我们的flank-mixtral8x7B主题。如果这个不存在,NiFi 和 Kafka 会自动为您创建一个。
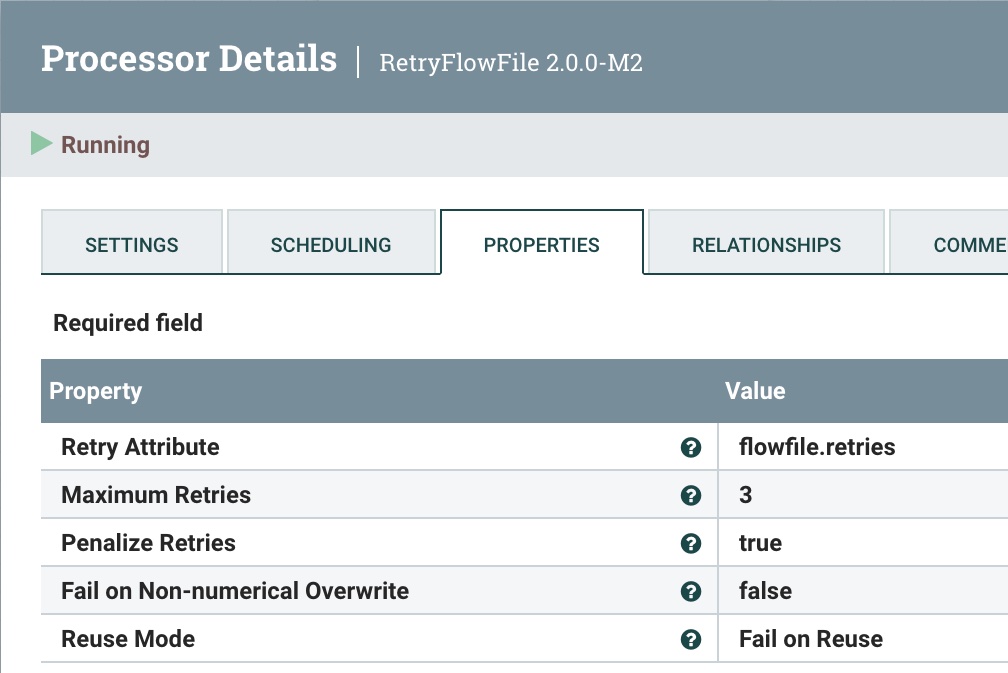
第 7 步:重试发送
如果出现问题,我们会尝试重新发送 3 次,然后失败。
将数据推送到 Slack 的概述:
![将数据推送到 Slack 的概述]() < /p>
< /p>
第 8 步:将相同的数据发送到 Slack 以供用户回复
第一步是拆分成一条记录以一次发送一个。为此,我们使用 SplitRecord 处理器。
![使用 SplitRecord 处理器拆分为一条记录,一次发送一条]()
和以前一样,重用 JSON 树读取器和 JSON 记录集写入器。像往常一样,选择“1”作为每个拆分的记录。
第 9 步:使生成的文本可用于消息传递
我们利用 EvaluateJsonPath 从 Mixtral 中提取生成的文本(在 HuggingFace 上)。

为了对用户进行最终回复,我们需要一个根据我们希望的沟通方式进行格式化的 Slack Response 模板。下面是一个具有基础知识的示例。
Slack 响应模板
=============== =================================================== ===============================================
HuggingFace ${modelinformation} ${date} 结果:
问题:${输入}
回答:
${生成的文本}
============================================= 书呆子数据====
HF URL:${invokehttp.request.url}
TXID:${invokehttp.tx.id}
== Slack 消息元数据 ==
ID:${messageid} 名称:${messagerealname} [${messageusername}]
时区:${messageusertz}
== HF ${modelinformation} 元数据 ==
计算字符/时间/类型:${x-compute-characters} / ${x-compute-time}/${x-compute-type}
生成/提示令牌/每个令牌的时间:${x-generate-tokens} / ${x-prompt-tokens} : ${x-time-per-token}
推理时间:${x-inference-time} // 队列时间:${x-queue-time}
请求 ID/SHA:${x-request-id} / ${x-sha}
验证/总时间:${x-validation-time} / ${x-total-time}
=================================================== =================================================== ===========
<图名称=“51c0”>
<图名称=“51c0”>
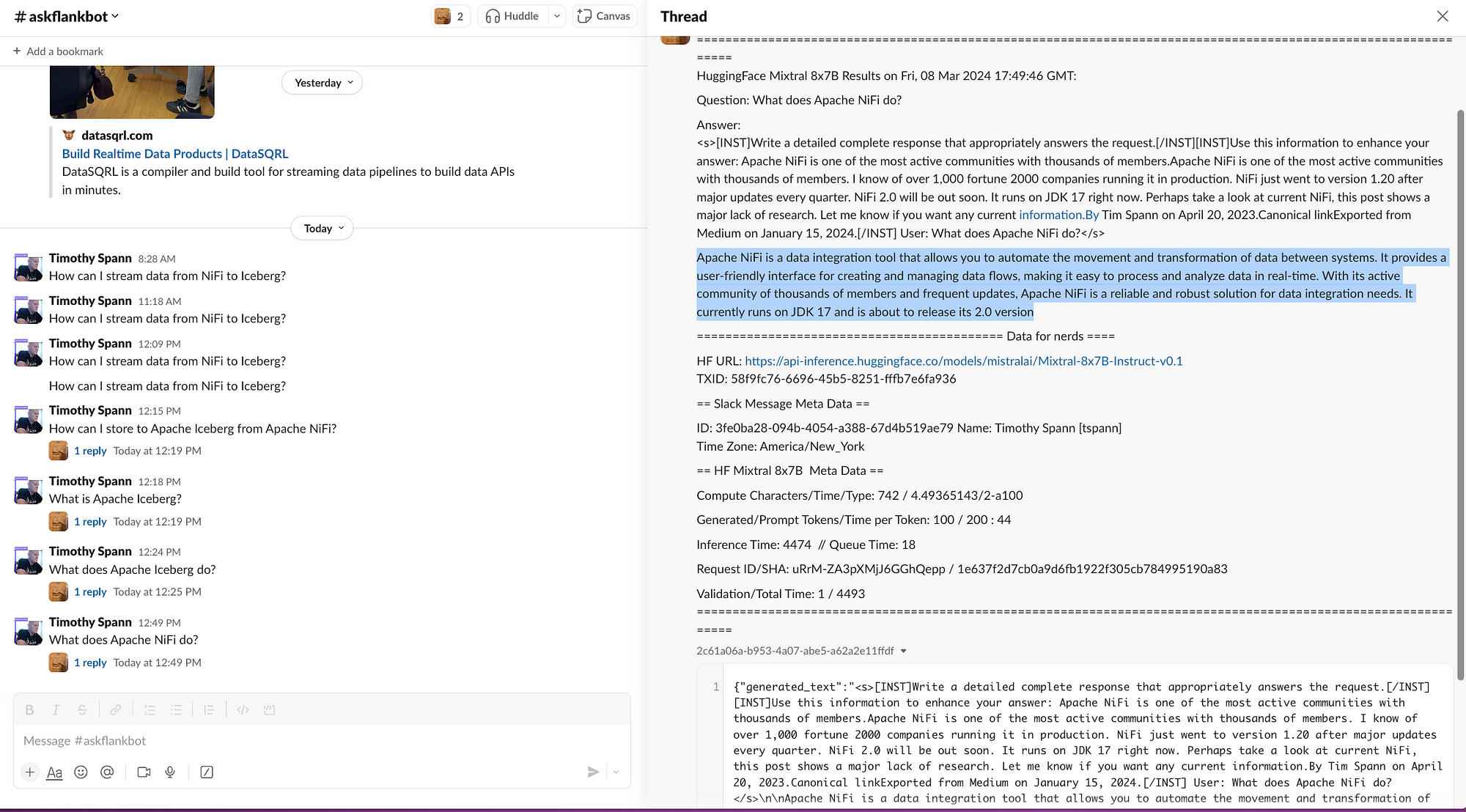
运行后,它在 Slack 中将如下图所示。
![对“Apache NiFi 做什么?”问题的 Slack 响应]() 您现在已向 Hugging Face 发送提示,让它针对 Mixtral 运行,将结果发送到 Kafka,并通过 Slack 响应用户。
您现在已向 Hugging Face 发送提示,让它针对 Mixtral 运行,将结果发送到 Kafka,并通过 Slack 响应用户。
我们现在已经用零代码完成了完整的 Mixtral 应用程序。
结论
您现在已经利用 Apache NiFi、HuggingFace 和 Slack 构建了完整的往返行程,以利用新的 Mixtral 模型构建聊天机器人。
学习总结
- 了解如何为 HuggingFace Mixtral 构建合适的提示
- 了解如何清理流数据
- 构建了可重复使用的 HuggingFace REST 调用
- 处理后的 HuggingFace 模型调用结果
- 发送您的第一条 Kafka 消息
- 格式化和构建的 Slack 调用
- 为 GenAI 构建完整的数据流
如果您需要有关使用新 Apache NiFi 2.0 的其他教程,请查看:
 第 3 步: 查询以转换和清理结果
第 3 步: 查询以转换和清理结果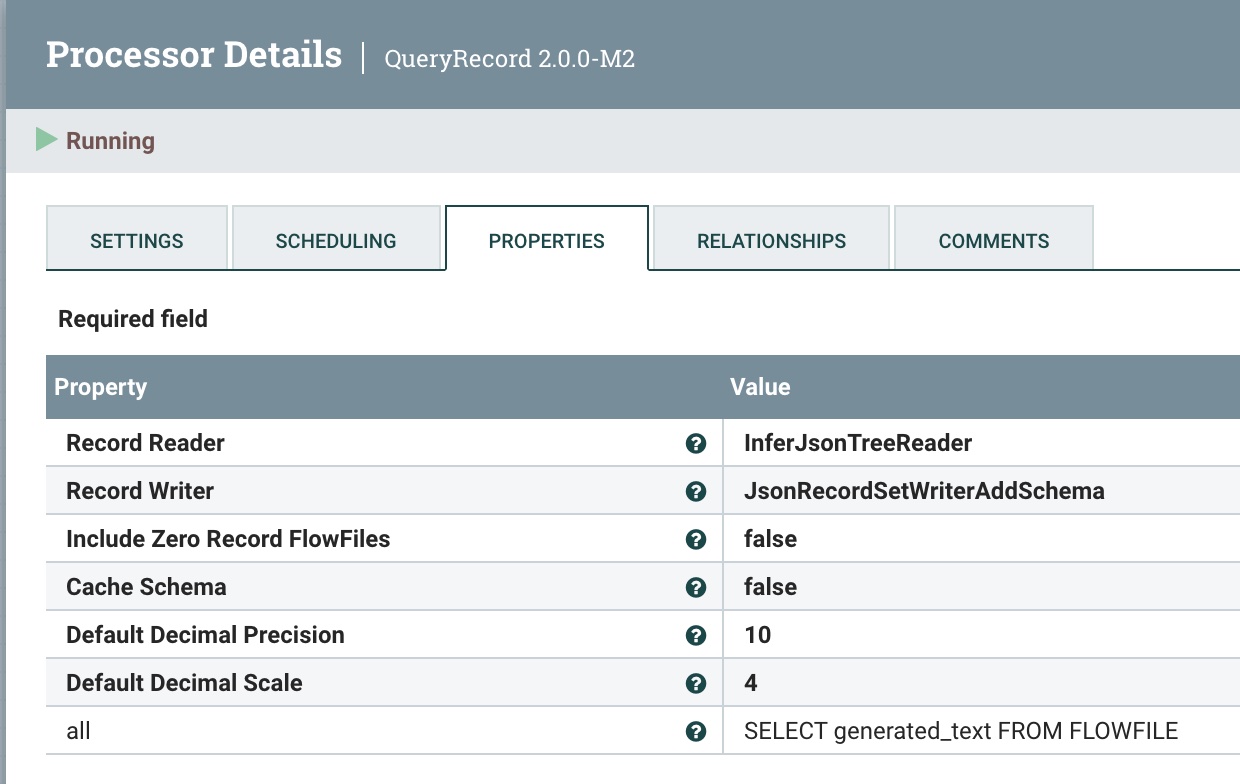


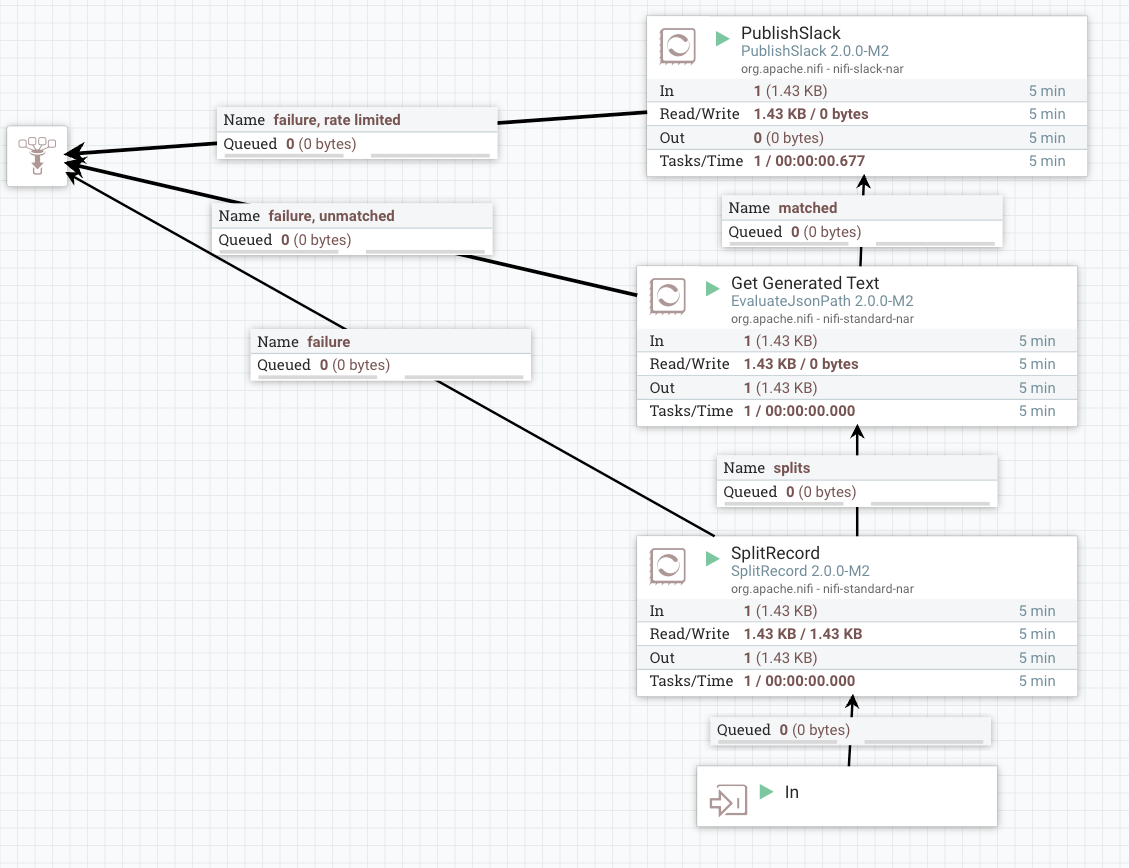 < /p>
< /p>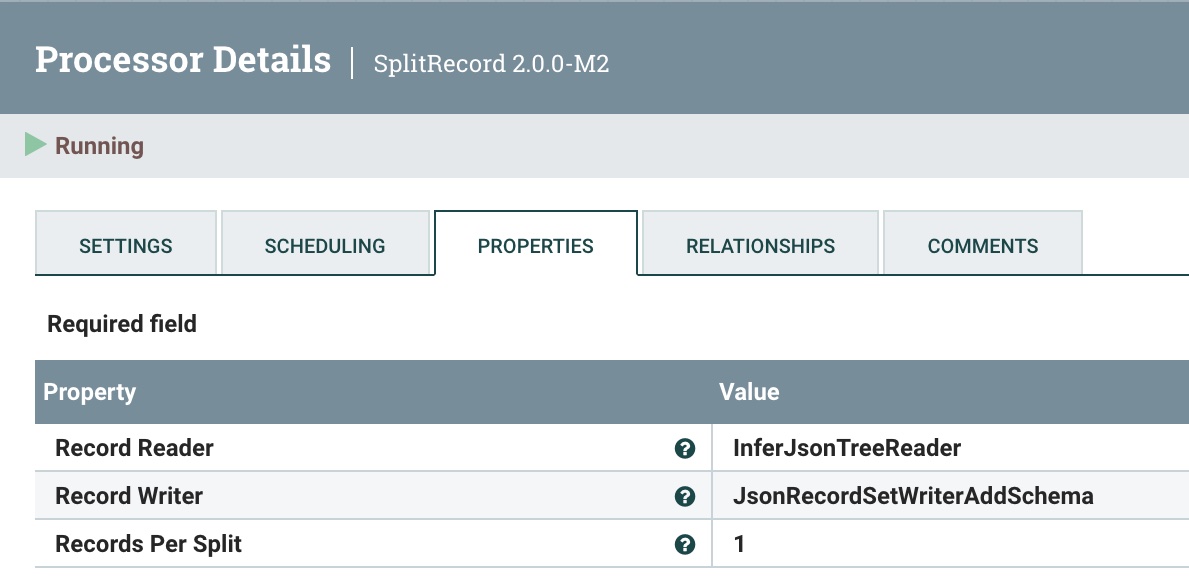
 您现在已向 Hugging Face 发送提示,让它针对 Mixtral 运行,将结果发送到 Kafka,并通过 Slack 响应用户。
您现在已向 Hugging Face 发送提示,让它针对 Mixtral 运行,将结果发送到 Kafka,并通过 Slack 响应用户。有关构建 Slack 机器人的更多信息:
另外,感谢您关注我的教程。我正在编写其他 Apache NiFi 2 和生成式 AI 教程,这些教程将发布到 DZone。
<图名称=“9e71”>
最后,如果您在普林斯顿、费城或纽约市,请访问 我的聚会,用于亲自实践这些技术。