
据估计,2010-2020年,数字世界的数据将增加50倍。Gartner预计,2018 年全球连接内容将达到 64 亿件,比 2015 年增加 30%,到 2020 年将达到 208 亿件。
从各方面来说,大数据都比你想象的要大,但此外,它正在加速。
在 IoT 方面,这涉及越来越多的复杂项目,包括数百个供应商、设备和技术。Forrester的米歇尔·佩利诺和弗兰克·吉列预测了在政府、库存和仓库管理应用中的运输、安全和监控应用中的车队管理,以及零售和工业中的库存和仓库管理应用初级制造业的资产管理将是物联网增长最热门的领域。
增加数据量的影响是速度的提高,我们必须在速度中引入这些数据、执行数据分析和筛选相关信息。由于每秒有数百万个事件来自 IoT 设备,因此组织必须为其 IoT 需求配备灵活、全面且经济高效的解决方案。
在GigaSpaces,我们意识到,解决这一日益增长的需求的解决方案不是从根本上改变现有的架构,而是通过内存计算扩展它,以便对快速数据进行快速分析和控制。低延迟流分析与事务工作流触发器相结合,可随时对 IoT 数据执行操作。这包括预测性维护和异常检测,以及数百万个传感器数据点。
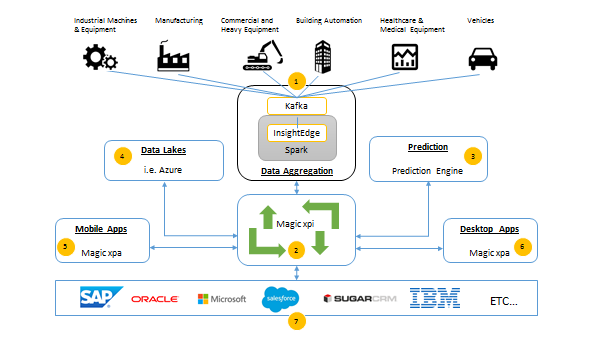
InsightEdge 为魔术的预测引擎提供动力,满足所有物联网需求
挑战
Magic软件企业是企业级应用程序开发和业务流程集成软件解决方案的全球提供商,也是各种软件和IT服务的供应商,多年来一直在利用GigaSpaces XAP。
当Magic推出他们的xpi集成平台时,他们正在寻找一个数据聚合解决方案,在Magicxpi前面形成一个物联网中心。无论数据和速度要求如何,此解决方案都需要足够灵活,以满足各种应用。
在快速数据时代,xpi平台虽然证明了可操作的互操作性,但它仍然面临着许多现有平台的挑战,这些平台还没有准备好处理快速数据引入方案。魔术正在寻找一个POC,可以尽快实施,同时提供快速的结果。
解决方案
InsightEdge 是帮助 Magic IoT 解决方案应对所有困难数据转型挑战的完美选择,使客户能够集中精力设计最佳流程和流程,以支持其业务目标。该解决方案需要灵活且对任何类型的数据输入开放,无论数据类型和结构、速度、内存中运行情况如何。那是我们进来的地方在会议期间,我们提出了基于 Kafka 和 InsightEdge 的简单解决方案,以帮助促进 IoT 用例中的数据速度和多样性。
好处
InsightEdge 为魔术提供了一些关键优势:
- 性能:能够从多个 IoT 传感器中摄录快速数据。
- 数据聚合:InsightEdge 能够以高吞吐量处理流式传感器数据,并将其聚合到与每个传感器的通知节奏相关的时间窗口中。
- 快速数据存储:然后,流的数据将结构化为语义丰富的数据模型,可以从任何应用程序查询。
- 大数据架构的简化:InsightEdge 可轻松使 Magic 能够将 Apache Spark 和快速数据分析的强大功能相结合,而无需大规模数据源集成或数据复制 (ETL)。
结果
使用 InsightEdge,Magic 能够为客户提供快速的数据流,并能够在内存网格上执行聚合和计算功能。使用 XAP 数据网格可使流式处理速度更快,因此无需 Hadoop。
InsightEdge 设施 Magic 的客户需要通过预测性制造和维护实现物联网部署,使他们能够从系统接收实时、快速、数据驱动的事件。
InsightEdge用例:使用魔法xpi的汽车遥测引入和数据预测
实时 InsightEdge 用例是使用 Magic xpi 的汽车遥测引入和数据预测。对于汽车遥测数据,很难提前预测哪些数据会有用。在数据预测的情况下,我们不仅要考虑设备遥测,还要考虑诊断遥测。
预测性汽车维护需要汽车遥测引入和数据预测。Magic 的解决方案堆栈需要在体系结构中再增加一个组件,才能完全兼容快速数据和可扩展的方案,需要确保创新,并适合正确的拼图。
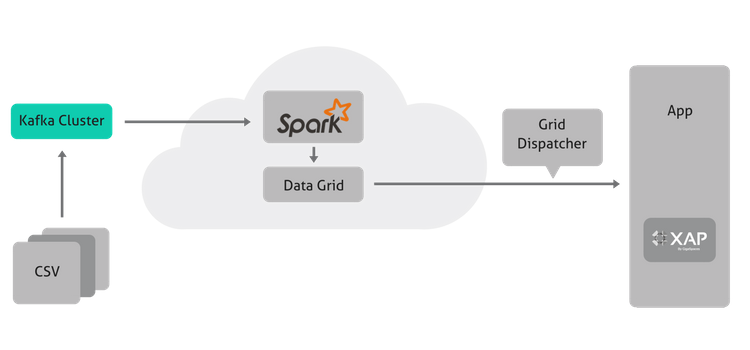
在此用例中,我们将介绍数据收集后(假设我们有 CSV 文件,但可能一直流式传输),直到数据发送到 Magic 的 xpi 集成平台。
我们如何构建它
卡 夫 卡
Apache Kafka是一个分布式流媒体平台, 或类固醇上可靠的消息代理, 但不限于这一点.它支持构建实时流数据管道,在系统或应用程序之间可靠地获取数据,并构建转换或响应数据流的实时流式处理应用程序。

我们将使用版本”kafka_2.10-0.9.0.0″来运行我们的测试,但是,新的卡夫卡版本在那里。您可以在这里下载卡夫卡或Kafdrop 是消息代理的简单 UI 监视工具。在这种情况下,我们将使用它为 Kafka 在开发期间调节主题和消息内容。使用Git 页面上的说明下载 Kafdrop 并按照说明进行安装。
洞察边缘
InsightEdge 是一款高性能 Spark 分发,专为低延迟工作负载和在一个统一解决方案中进行极端分析处理而设计。InsightEdge 具有强大的分析容量和几乎无延迟,可提供即时结果。
GigaSpaces 的 Spark 分布消除了对 Hadoop 分布式文件系统 (HDFS) 的依赖,从而突破了”链式”Spark 产品中嵌入式性能”玻璃天花板”。为此,GigaSpaces 增加了企业级功能,如高可用性和安全性。结果是硬化的 Spark 分布比标准 Spark 快三十倍。
下载洞察力边缘在这里。无需安装,只需将文件解压缩到所需位置即可。(注:与 Windows 不兼容)
代码深度潜水
管理工作
首先,我们需要启动 Kafka 和 InsightEdge,因此我们将使用以下两个脚本:
- start-kafka.sh
#!/usr/bin/env bash
echo "KAFKA_HOME=$KAFKA_HOME"
mkdir $KAFKA_HOME/logs
export ZLOGS=$KAFKA_HOME/logs/zookeeper.log
echo "Starting ZooKeeper, logs: $ZLOGS"
nohup $KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties > $ZLOGS 2>&1 &
echo "Waiting 10 seconds..."
sleep 10
export KLOGS=$KAFKA_HOME/logs/kafka.log
echo "Starting Kafka, logs: $KLOGS"
nohup $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties > $KLOGS 2>&1 &
echo "Waiting 15 seconds..."
sleep 15
echo "Creating Kafka topics for car_events"
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic car_events- start-insightedge.sh
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
$INSIGHTEDGE_HOME/sbin/insightedge.sh --mode demo
$INSIGHTEDGE_HOME/datagrid/bin/gs-webui.sh > /dev/null 2>&1 &- 接下来,我们将启动 Kafdrop,以便我们可以在我们的 Kafka 经纪人上拥有一个 UI。要运行 Kafdrop,请浏览到目标目录并运行:
java -jar ./kafdrop-<VERSION>-SNAPSHOT.jar
--zookeeper.connect=<MACHINE>:<PORT>例如,如果我在本地和端口 2081 上运行 ZooKeeper,请使用以下内容:
java -jar ./kafdrop-1.2.2-SNAPSHOT.jar
--zookeeper.connect=localhost:2181浏览到本地实例,以确保其工作 [链接: http://localhost:9000]

模型类
现在,我们必须构建模型,因此,让我们看看它应该是什么样子:
package com.magic.insightedge.model
import java.util
import java.util.Date
import org.insightedge.scala.annotation.SpaceId
import play.api.libs.json._
import play.api.libs.json. {
Json,
Writes
}
import scala.beans.BeanProperty
import org.insightedge.scala.annotation._
import scala.beans. {
BeanProperty,
BooleanBeanProperty
}
abstract class MagicEvent(ID: Int) {
def this() = this(-1)
}
case class CarEvent(
@BeanProperty @SpaceId
var ID: Int,
@BeanProperty
var COL1: String,
@BeanProperty
var COL2: Double,
@BooleanBeanProperty
var IsSentByHttp: Boolean
) extends MagicEvent() {
def this() = this(-1, null, -1.0, false)
}接下来,我们编写事件类(用于处理传入事件):
package com.magic.events
import java.io.Serializable
import play.api.libs.json. {
Json,
Writes
}
object Events {
case class CarEvent(ID: Int,
COL1: String,
COL2: Double,
IsSentByHttp: Boolean)
implicit val CarEventWrites = new Writes[CarEvent] {
def writes(carEvent: CarEvent) = Json.obj(
"ID" - > carEvent.ID,
"COL1" - > carEvent.COL1,
"COL2" - > carEvent.COL2,
"IsSentByHttp" - > carEvent.IsSentByHttp
)
}
}代码
现在,我们已经有了模型和事件模型,我们可以编写我们想要部署到 Spark 的代码(它实际上将从 Kafka 读取到 Spark 并保存到网格中):
package com.magic.insightedge
import com.magic.events.Events
import com.magic.events.Events.CarEvent
import kafka.serializer.StringDecoder
import org.apache.log4j. {
Level,
Logger
}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming. {
Seconds,
StreamingContext
}
import org.apache.spark.SparkConf
import org.insightedge.spark.context.InsightEdgeConfig
import org.insightedge.spark.implicits.all._
import org.rogach.scallop.ScallopConf
import play.api.libs.json.Json
object EventsStreamApp {
implicit val carEventReads = Json.reads[CarEvent]
def main(args: Array[String]): Unit = {
println("Starting Car Events Stream")
println(s "with params: ${args.toList}")
val conf = new Conf(args)
println(s "conf=${conf}")
println(s "checkpointDir=${conf.checkpointDir()}")
val ssc = StreamingContext.getOrCreate(conf.checkpointDir(), () => createContext(conf))
ssc.start()
ssc.awaitTermination()
println("done")
}
class Conf(args: Array[String]) extends ScallopConf(args) {
val masterUrl = opt[String]("master-url", required = true)
val spaceName = opt[String]("space-name", required = true)
val lookupGroups = opt[String]("lookup-groups", required = true)
val lookupLocators = opt[String]("lookup-locators", required = true)
val zookeeper = opt[String]("zookeeper", required = true)
val groupId = opt[String]("group-id", required = true)
val batchDuration = opt[String]("batch-duration", required = true)
val checkpointDir = opt[String]("checkpoint-dir", required = true)
verify()
}
def createContext(conf: Conf): StreamingContext = {
val ieConfig = InsightEdgeConfig(conf查找组()),一些(conf.查找定位器))
val scConfig = 新的 SparkConf(.setAppName(“事件流”setMaster(conf.masterUrl())。setInsightEdgeConfig(即Config)
瓦尔卡夫卡帕拉姆斯 = 地图(“zookeeper.connect” – > conf.zoos.zoos.),”group.id” – > conf.groupId())
val ssc = 新的流上下文(scConfig,秒(合一.batch持续时间()。到Int))
ssc.检查点(conf.检查点迪尔())
瓦尔 sc = ssc.spark 上下文
瓦尔根记录器 » 记录器.获取根记录器
根记录器.set 级别(级别.ERROR)
打开卡夫卡流
瓦尔车流 – 创建汽车流(sc,卡夫卡帕拉姆斯)
汽车流
.地图分区 |
分区 >
分区.map |
e >
打印(“\”-“=e)
模型。汽车事件(
e.ID,
e.COL1,
e.COL2,
e.IsSentByHttp)
}
}
.savetoGrid()
斯克
}
def 创建CarStream(sc:流式上下文,卡夫卡参数:映射[字符串,字符串]):DStream[CarEvent] |
KafkaUtils.createStream_String,字符串,字符串解码器,字符串装饰器*(sc,卡夫卡帕拉姆斯,
地图(“car_事件” – > 1),存储级别.MEMORY_ONLY)
.map(*.#2)
.map(消息 > Json.parse(消息)作为 [CarEvent])
}
}
现在,我们有三个运行逻辑的选项:
- 火花作业
- 网格作业(事件驱动)
- 针对网格的外部作业(暂时”保留”Spark 的数据)
我们选择使用第三个选项,因为我们有可扩展性和增长方面的考虑。我们需要考虑正在运行的外部进程,而不是在网格上出现一个很长的事件。这是一个简单的推/拉决定,我们决定拉(如果你想实现处理单元(PU),见附录1)。
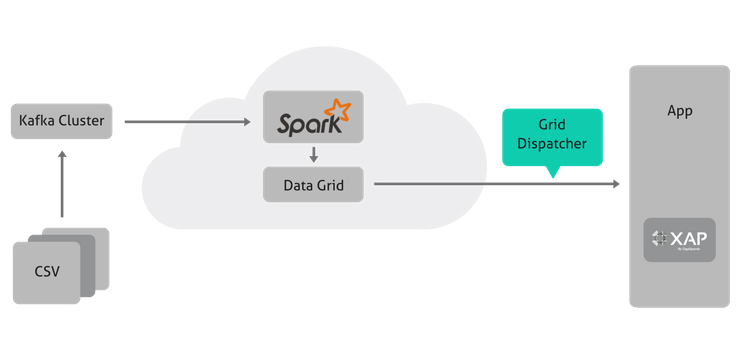
对 Grid 执行外部作业完全是一个有趣的选择,因为它是可以从任何集成端点开始的,从一个简单的 JAR 文件开始,并在任何自定义的代码或集成平台中实现它:
package com.magic;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.mime.MultipartEntityBuilder;
import org.apache.http.impl.client.DefaultHttpClient;
import org.openspaces.core.GigaSpace;
import org.openspaces.core.GigaSpaceConfigurer;
import org.openspaces.core.space.UrlSpaceConfigurer;
import com.j_spaces.core.client.SQLQuery;
import com.magic.insightedge.model.CarEvent;
public class CarEventDispatcher {
private static String postUrl;
public static void main(String[] args) throws InterruptedException {
if (args.length < 2) {
System.out.println("\tNot enough arguments. Usage: java -jar events-dispatcher.jar <post-url> <remove-dispatched-from-space true|false>");
System.exit(1);
}
postUrl = args[0];
System.out.println("\tPOST URL: " + postUrl);
// remove dispatched from the space or update field 'isSentByHttp' to 'true'
boolean removeDispatchedFromSpace = Boolean.parseBoolean(args[1]);
System.out.println("\tRemove dispatched events from space: " + removeDispatchedFromSpace);
UrlSpaceConfigurer spaceConfigurer = new UrlSpaceConfigurer("jini://localhost/*/insightedge-space");
GigaSpace gigaSpace = new GigaSpaceConfigurer(spaceConfigurer)类,”isSentByHttp = false,WIP = 0″);
CarEvent_ 事件;
如果(删除已调度的Space)|如果(删除已调度的Space) |
事件 = gigaSpace.取多(查询);
* 其他 *
事件 = gigaSpace.read 多(查询);
}
如果(事件.长度 > 0) |
System.out.println(“调度”= 事件.length = “来自空间的汽车事件”);
(CarEvent e : 事件) |
System.out.println(“张贴”= e);
尝试 |
httpPost(后Url,e.toString());
线程.睡眠(1000);
• 渔获量(IO异常(前)
ex.printStackTrace();
终于
如果 (!删除从空间已调度) |
e.setIsSentByHttp(真实);
gigaSpace.write(e);
}
}
}
* 其他 *
System.out.println(“没有要调度的,空间中的 0 个事件”);
}
}
公共静态 void httpPost(字符串后 Url、字符串负载)引发 IO 异常 |
httpClient httpclient = 新的默认HttpClient();
httpPost httppost = 新的 httpPost(帖子)
httpEntity 实体 = 多部分实体构建器
.create()
.添加文本正文(“应用程序名称”,”IFSIoTDemo”)
.addTextBody(“prgname”,”HTTP”)
.addTextBody(“参数”,”-AHTTP_IoTDemo_机器人传输,传输XML”)
.addTextBody(“传输XML”,有效负载)
.build();
httppost.setEntity(实体);
http响应响应 = httpclient.执行(httppost);
System.out.println(“HTTP 响应代码 = ” = 响应.getStatusline(.getStatusCode());
缓冲阅读器阅读器 = 新的缓冲阅读器(新的输入流阅读器(响应.getEntity(.getContent(getContent));
字符串行;
而((行 = respReader.readLine())!= 空) |
系统.out.println(行);
}
}
}
为了运行上述代码,我们将使用一个简单的脚本来调用生成的 JAR 文件:
#!/usr/bin/env bash
# Run dispatcher every 5 seconds
SLEEP_TIME=5
POST_URL=http://cloud.magicsoftware.de/Magicxpi4.5/MgWebRequester.dll
# whether to delete dispatched events from the space OR update 'isSentByHttp' field. Possible values: 'true' - remove, 'false' - update
REMOVE_DISPATCHED_FROM_SPACE=false
echo " DISPATCHER will run every $SLEEP_TIME seconds:"
while true
do
sleep $SLEEP_TIME
echo "*** Running dispatcher: "
java -jar ../events-dispatcher/target/events-dispatcher.jar $POST_URL $REMOVE_DISPATCHED_FROM_SPACE
done作为奖励,下面是从空间中删除所有汽车事件的代码(网格即:
package com.magic;
import com.j_spaces.core.client.SQLQuery;
import com.magic.insightedge.model.CarEvent;
import org.openspaces.core.GigaSpace;
import org.openspaces.core.GigaSpaceConfigurer;
import org.openspaces.core.space.UrlSpaceConfigurer;
public class DeleteCarEventsUtil {
public static void main(String[] args) {
System.out.println("DELETING all CarEvent's from the space");
UrlSpaceConfigurer spaceConfigurer = new UrlSpaceConfigurer("jini://localhost/*/insightedge-space");
GigaSpace gigaSpace = new GigaSpaceConfigurer(spaceConfigurer).gigaSpace();
SQLQuery<CarEvent> query = new SQLQuery<CarEvent>(CarEvent.class, "");
gigaSpace.takeMultiple(query);
}
}现在,我们可以从 Grid 调度事件,让我们在部署火花作业时向后工作,以便它可以侦听 Kafka 主题并引入数据:
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
streamJar="../events-streaming/target/events-streaming.jar"
ieHost=localhost
zookeeper=localhost:2181
nohup $INSIGHTEDGE_HOME/bin/insightedge-submit \
--class com.magic.insightedge.EventsStreamApp \
--master spark://$ieHost:7077 \
--executor-cores 2 \
$streamJar \
--master-url spark://$ieHost:7077 \
--zookeeper $zookeeper \
--group-id events-processing \
--space-name insightedge-space \
--lookup-groups insightedge \
--lookup-locators $ieHost \
--batch-duration 1 \
--checkpoint-dir "C1" &现在,除了两件事之外,我们所有的事情都运行在:从 CSV 文件收集数据的代码以及如何运行它魔术.制作人
导入 java.util.属性
对象生产者应用程序扩展应用程序 |
println(“-运行卡夫卡生产商”)
println(“-参数:”=args.mkString(\”,”,”\”))
瓦尔德利姆 = “=”
args.find(!._.包含(德利姆))
抛出新的非法参数异常(“不正确的参数” = a))
val mapArgs = args.map(a > a.trim.split(delim)))))))映射(a > a(0) – > a(1)到Map。
瓦尔·卡夫卡·康菲克 ·
val 道具 = 新属性()
props.put(BOOTSTRAP_SERVERS,mapArgs.getOrElse(BOOTSTRAP_SERVERS,”本地主机:9092″))
prop.put(“键.序列化器”,”org.apache.kafka.common.系列化.String序列化器”)
prop.put(“value.序列化器”,”org.apache.kafka.common.系列化.String序列化器”)
prop.put(CSV_位置,mapArgs.getOrElse(CSV_位置,”/家庭/选择/魔法/千兆空间-洞察-1.0.0-溢价/温度2.csv”)
道具.put(比托卡,地图Args.getOrElse(比托卡,”汽车+事件”))
道具
}
println(“-卡夫卡康菲格$kafkaConfig”
CSVProducer.run(卡夫卡康菲克)
}
所以,你可能会问自己什么是CSV生产者?嗯,这里是:
package com.magic.producer
import scala.io
import scala.util.Random
import java.util. {
Properties,
UUID
}
import com.magic.events.Events._
import org.apache.kafka.clients.producer. {
KafkaProducer,
ProducerRecord
}
import play.api.libs.json.Json
object CSVProducer {
def run(kafkaConfig: Properties): Unit = {
println("-- Running CSV producer")
println("------- first arg:" + kafkaConfig.getProperty(CSV_LOCATION))
val bufferedSource = io.Source.fromFile(kafkaConfig.getProperty(CSV_LOCATION))
val producer = new KafkaProducer[String, String](kafkaConfig)
val topic = kafkaConfig.getProperty(TOPIC_CAR)
Thread.sleep(1000)
//drop the headers first line
for (line < -bufferedSource.getLines.drop(1)) {
val cols = line.split(",").map(_.trim)
// do whatever you want with the columns here
val eventJson = Json.toJson(CarEvent(
cols(0).toInt,
cols(1),
cols(2).toDouble,
false)).toString()
println(s "sending event to $topic $eventJson")
producer.send(new ProducerRecord[String, String](topic, eventJson))
producer.flush()
println(s "JSON is: $eventJson")
}
bufferedSource.close
Thread.sleep(1000) //add two more zeros to wait a whole second
}
}使用以下脚本运行它:
#!/usr/bin/env bash
echo "INSIGHTEDGE_HOME=$INSIGHTEDGE_HOME"
producerJar="../events-producer/target/magic-events-producer.jar"
java -jar $producerJar csv.location="../KafkaInput.csv"附录 1
这是如何实现 PU 的通用模板。
package com.magic;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.net.URLConnection;
import org.openspaces.events.EventDriven;
import org.openspaces.events.EventTemplate;
import org.openspaces.events.adapter.SpaceDataEvent;
import org.openspaces.events.polling.Polling;
import com.j_spaces.core.client.SQLQuery;
import com.magic.insightedge.model.CarEvent;
@EventDriven
@Polling
public class CarEventProcessor {
@EventTemplate
SQLQuery<CarEvent> unprocessedData() {
SQLQuery<CarEvent> template = new SQLQuery<CarEvent>(CarEvent.class, "IsSentByHttp = false");
return template;
}
@SpaceDataEvent
public void eventListener(CarEvent event) {
System.out.println("Do something for car event: " + event打开连接();
conn.setDooutput(真实);
输出流编写器编写器 = 新的输出流编写器(conn.getoutputStream());
编写器.写入(事件)。COL1());
编写器.flush();
字符串行;
缓冲阅读器 = 新的缓冲阅读器(新的输入流阅读器(conn.getInputStream());
而(行 = 读取器.readLine())!= 空) |
系统.out.println(行);
}
编写器.close();
读取器.close();
[ 渔获量 (例外 e) ]
}
}
}
魔术的物联网平台
Magic xpi 是一个连接 IT 系统的集成平台,使您能够协调支持业务目标的数据流。它支持广泛的业务生态系统,实施开箱即用的经过认证和优化的连接器和适配器,以扩展领先的 ERP、CRM、财务和其他企业系统的功能。
Magic xpi 充当所有相关部件之间的协调引擎:知识库、机器学习、资产管理和服务案例。Magic xpi 使用 HTTP 触发器 (XML) 和 ODATA 提供程序基于服务协调和连接数据。魔术xpi使用Magicxpi连接器与专用生态系统交互。
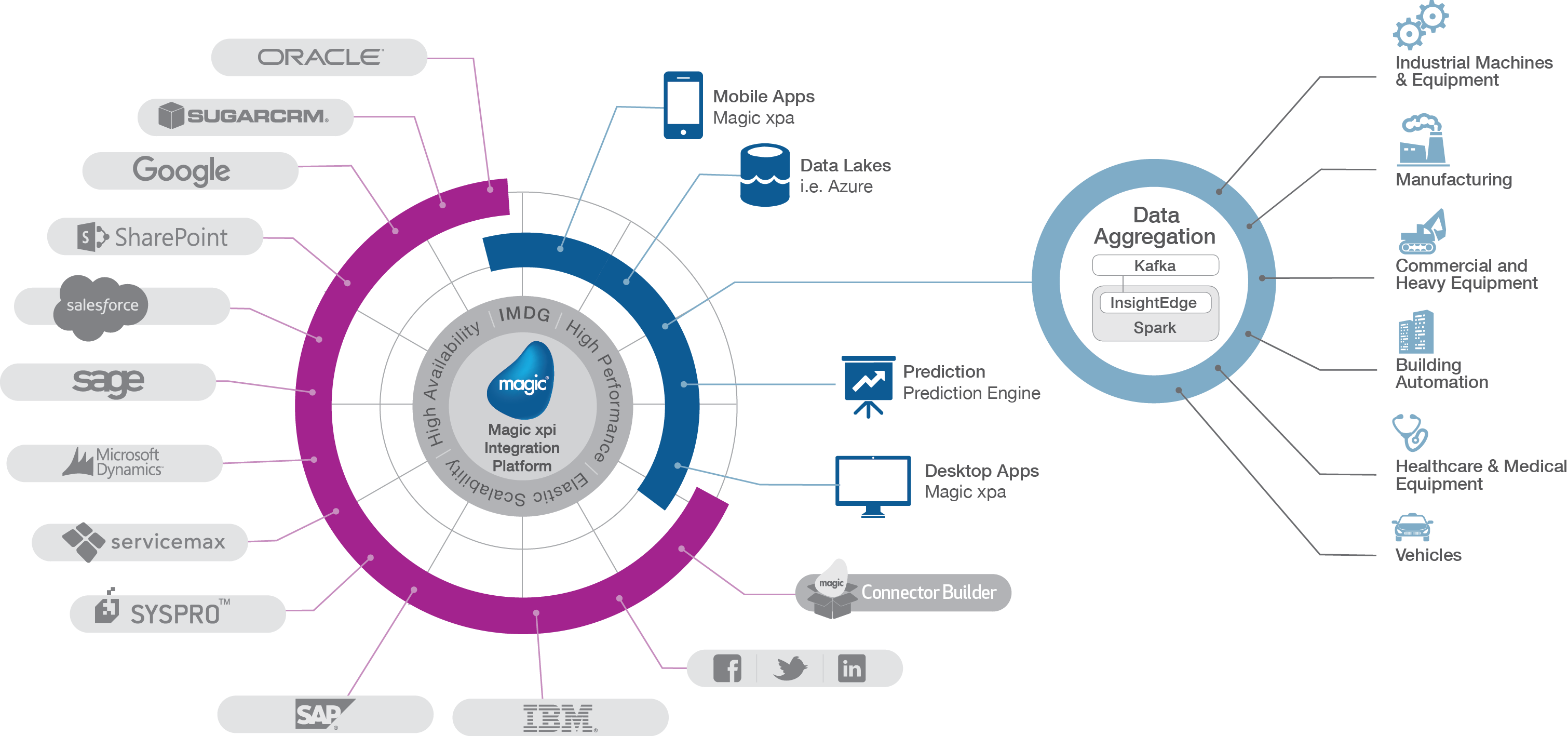
最终想法
据估计,到 2017 年,全球 60% 的制造商将使用分析来检测和分析来自互联产品和制造的数据,并优化日益复杂的产品组合。到 2018 年,与 IoT 相一致的高级、专用分析应用程序的激增,将使制造商在创新交付和供应链性能方面提高 15% 的生产率。
InsightEdge 和 XAP 提供的事务和分析功能组合的灵活性是将 GigaSpaces 与其余功能区分开来。借助 Magic 的用例,我们通过中心、边缘和云的开源组件大规模支持 IoT 应用程序。
Gigaspace 最新的数据产品 InsightEdge 提供了一个支持 Apache Spark 的分析平台,可帮助促进 IoT 用例中的全频谱分析(流式分析、机器学习和图形处理)。我们很高兴集成到 Magic 的解决方案堆栈中,这需要完全符合快速数据和可扩展方案。
