
在过去几年里, 开源流处理的创新出现了爆炸式增长。apache spark 和 apache storm 等框架为开发人员提供了可用于开发应用程序的流抽象;apachebeam 提供了一个 api 抽象, 使开发人员能够独立于底层框架编写代码, 而 apache nifi 和 streamset 数据收集器等工具提供了用户界面抽象, 允许数据工程师定义数据流从高层构建块, 很少或没有编码。
在本文中, 我将提出一个用于组织流处理项目的框架, 并简要描述每个区域。我将专注于将项目组织成一个概念模型;有许多文章比较了现实世界中应用程序的流框架–我在最后列出了一些文章。
我将介绍的特定类别包括流处理框架、流处理 api 和流数据流系统。
什么是流处理?
解释流处理的最简单方法是相对于它的前身批处理。过去的许多数据处理都是围绕着处理定期、可预测的数据批次进行的–在 “安静” 时间内处理前一天的事务的夜间工作;提供仪表板等汇总统计信息的月度报告。批处理简单、可扩展且可预测, 企业容忍模型中固有的延迟-可能需要数小时甚至数天的时间才能在下游数据存储中处理和可见事件。
随着企业要求更及时的信息, 批次越来越小, 处理频率也更高。由于批处理大小倾向于单个记录, 出现了流处理。在流处理模型中, 事件在发生时进行处理。这种更动态的模型带来了更多的复杂性。通常情况处理是不可预知的 , 事件以突发状态到达 , 因此系统必须能够应用背压、缓冲事件进行处理 , 或者更好的是 , 动态扩展以满足负载。更复杂的方案需要处理无序事件、异构事件流以及重复或丢失的事件数据。
在批处理大小不断缩小的同时, 数据量也在增长, 同时对容错能力也有需求。分布式存储架构随着hadoop、 cassandra、 s3和许多其他技术的发展而发展。hadoop 的文件系统 (hdfs) 为将数据写入群集带来了一个简单的 api, 而mapreduce使开发人员能够编写可扩展的批处理作业, 这些作业将使用简单的编程模型处理数十亿条记录。
mapreduce 是扩展数据处理的有力工具, 但其模型在一定程度上是有限的;加州大学伯克利分校 amplab的开发人员创建了 apache spark,通过提供更广泛的操作来改进 mapasholet, 而不仅仅是映射和减少, 并允许将中间结果保存在内存中, 而不是存储在磁盘上, 这大大地提高性能。spark 还提供了一致的 api, 无论是在群集上运行还是作为独立应用程序运行。现在, 开发人员可以编写分布式应用程序并对其进行小规模的测试, 即使是在他们自己的笔记本电脑上也是如此!-在将它们展开到由数百个或数千个节点组成的群集之前。
批量缩小和数据量不断增加的趋势在apacheflink提供了低延迟处理 , 并提供了精确的一次付保证。
快到今天, flink 和 spark 流只是流式传输框架的两个例子。流框架允许开发人员构建应用程序来处理近乎实时的分析用例, 如复杂事件处理 (cep)。cep 结合来自多个源的数据来识别各种事件之间的模式和复杂关系。cep 的一个例子是通过滑动时间窗口分析一组医疗监视器的参数, 如温度、心率和呼吸率, 以确定关键条件, 如患者进入休克状态。
在很大程度上, 各种框架提供了类似的功能: 能够在集群中分发代码和数据、配置数据源和目标、加入事件流、将事件传递到应用程序代码等。它们执行此操作的方式不同, 在延迟、吞吐量、部署复杂性等方面提供了权衡。
流式框架和 api 是针对开发人员的, 但有大量数据工程师希望使用更高级别的工具来构建数据管道–将事件从生成位置移动到可分析的管道。流数据流系统 (如streamset 数据收集器和 apache nifi ) 为用户设计管道提供了基于浏览器的 ui, 提供了一系列现成的连接器和处理器, 以及用于添加扩展点的扩展点自定义代码。
流处理框架
至少有七个开源流处理框架。大多数都在 apache 横幅下, 每个都实现了自己的流抽象, 并在延迟和吞吐量方面进行了权衡:
在思想共享和采用方面, 阿帕奇斯派克是这里800磅的大猩猩, 但每个框架都有它的追随者。在不同的框架中, 在延迟、吞吐量、代码复杂性、编程语言等方面存在权衡, 但它们都有一个共同点: 它们都提供了一个环境, 开发人员可以在其中实现其业务逻辑。代码。
作为流处理框架的开发人员的一个视图的示例, 下面是 spark 文档中的单词计数应用程序, 它相当于 “hello world” 的流式传输:
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = sscval map (_ 分割 (“”) val 单词 = 输液. map (“” “) val 单词等值线 (x = & gt; (x & gt; (x, 1)).reduceByKey(_ _) 字句. print. print. sc. start () ssc.start () s社会上)
流式框架为 cep 等用例的流式处理应用程序进行编码提供了强大的功能和灵活性, 但进入的障碍很大, 只有开发人员需要申请。
流处理 api
流框架在事件处理延迟和吞吐量等方面有所不同, 但在功能上有许多相似之处-它们都提供了一种在连续事件流上运行的方法, 而且它们都提供了自己的 api。此外, 流处理 api 抽象提供了超出框架自己的 api 的另一个抽象级别, 允许单个应用在各种环境中运行。
apache beam 是apache beam的一个很好的例子, 它起源于谷歌, 是数据流模型的实现。beam 提供了一个统一的编程模型, 允许开发人员实现可以在各种框架上运行的流 (和批处理!) 作业。目前, 有针对 apex、弗林克、火花和谷歌自己的云数据流的梁 ‘ 跑步者 ‘。
beam 的最小字数示例 (删除了其丰富的空间注释!) 与 spark 代码没有那么大的区别, 即使它是在 java 中而不是 scla 中:
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.from("gs://apache-beam-samples/shakespeare/*"))
.apply("ExtractWords", ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.perElement())
.apply("FormatResults", MapElements.via(new SimpleFunction<KV<String, Long>, String>() {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}))
.apply(TextIO.Write.to("wordcounts"));
p.run().waitUntilFinish();
}因此, beam 为开发人员提供了一些独立于底层流框架的独立性, 但您仍将编写代码来利用它。
卡夫卡流是一个更专业的流处理 api。与梁来不同, 卡夫卡流提供了特定的抽象, 专门与 apache 卡卡作为您的数据流的源和目的地一起工作。卡夫卡流不是一个框架, 而是一个客户端库, 可用于实现您自己的流处理应用程序, 然后可以部署在群集框架 (如 mesos) 之上。卡夫卡连接是连接软件, 它弥合了卡夫卡与一系列其他系统之间的差距, api 允许开发人员创建卡夫卡消费者和生产商。
流数据流系统
流处理框架和 api 允许开发人员为 cep 等用例构建流分析应用程序, 但当您只想从某些源获取数据、应用一系列单事件转换以及写入一个或多个数据时, 可能会过度使用目的地
apache flume正是为这种过程创建的。flume 允许您配置数据管道以从各种来源获取数据管道、应用转换以及写入多个目标。flume 是一个经过战斗考验的可靠工具, 但它不是最容易设置的。用户界面并不十分友好, 如下所示:
# Sample Flume configuration to copy lines from
# log files to Hadoop FS
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /Users/pat/flumeSpool
a1.channels.c1.type = memory
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.path = /flume/events
a1.sinks.k1.hdfs.useLocalTimeStamp = true有关 flume 简化数据收集器的更广泛比较, 请参阅此博客条目。
简化数据收集器另一方面, 每个应用程序都提供了基于浏览器的 ui 来构建数据管道, 从而使数据工程师和数据科学家能够构建可以在计算机群集上执行的数据流, 而无需编写代码。虽然 sdc 不是 apache 管理的项目, 但它是开源的, 并且在与 nifi、spark 等相同的 apache2.0 许可证下免费提供。
此管道取自sdc 教程, 从本地磁盘存储中读取 csv 格式的事务数据, 从信用卡号计算信用卡颁发网络, 屏蔽信用卡号以外的所有数字, 并写入hadoop 的结果数据:
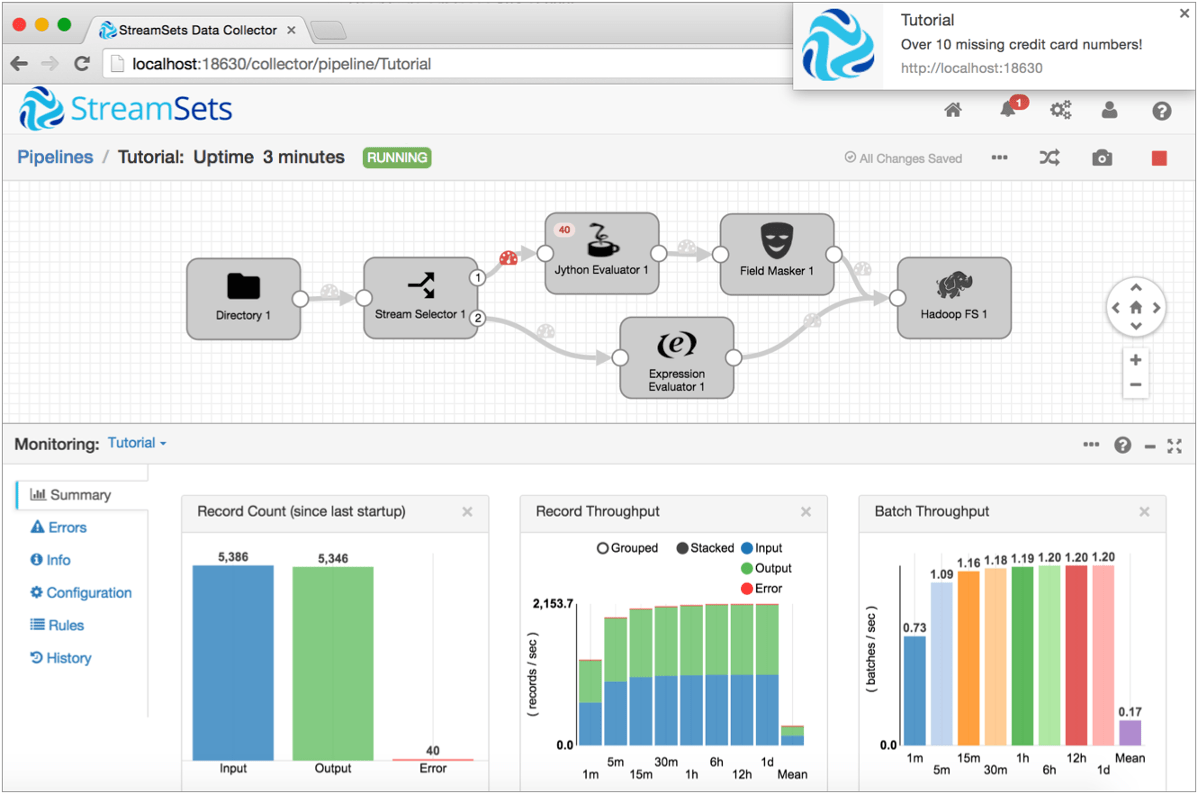
当然, 并不是每个问题都可以通过连接预构建的处理阶段来解决, 因此 sdc 和 nifi 都允许通过脚本语言 (如 scora、groovy、python 和 javascript) 以及它们的通用实现语言 java 进行自定义。
除了 ui 之外, 流处理工具从 flume 到 nifi 和 sdc 的演变的另一个方面是分布式处理。flume 没有对群集的直接支持, 您可以在它们之间部署和管理多个 flume 实例和分区数据。nifi 可以作为独立实例运行, 也可以通过自己的群集机制进行分发, 尽管人们可能会期望 nifi 在某个时候过渡到 hadoop 群集资源管理器 yarn。
sdc 同样可以独立运行, 如在 yar 上的 mapreduce 作业, 或作为 yarn 和 mesos 上的火花流应用程序。此外, 为了将流处理合并到管道中, sdc 还包括一个 spark 评估器, 允许开发人员将现有的 spark 代码集成为管道阶段。
那么我应该使用什么呢?
为您的特定工作负载选择合适的系统取决于一系列因素, 从功能处理要求到解决方案必须遵守的服务级别协议。适用一些一般准则:
- 如果要为分析用例 (如 cep) 从零开始实现自己的流处理应用程序, 则应使用其中一个流处理框架或 api。
- 如果您的工作负载位于群集上, 并且您希望设置连续的数据流以将数据引入群集中, 则使用流处理框架或 api 可能会过度使用。在这种情况下, 最好部署流数据流系统, 如 flume、nifi 或 sdc
实际上, 我们看到企业在后端使用流处理和批量交互式分析应用程序的组合。在此环境中, 单事件处理由 sdc 等系统处理, 将正确的数据存储在数据存储中, 随时为分析应用程序提供干净、新鲜的数据。
结论
流处理环境非常复杂, 但可以通过将各种项目划分为框架、api 和流数据流系统来简化。对于更复杂的用例, 开发人员在框架和 api 中有各种各样的选择, 而更高级别的工具允许数据工程师和数据科学家为大数据获取创建管道。
引用
本文重点介绍了总体情况以及所有这些项目之间的关系。有许多文章深入了解, 为选择一种或多种评估技术提供了基础。以下是一些, 没有特别的顺序: