
导语:掐指一算自己从研究生开始投入到Linux的海洋也有几年的时间,即便如此依然对其各种功能模块一知半解。无数次看了Linux内核的技术文章后一头雾水,为了更系统地更有方法的学Linux,特此记录。
历史
1991年,还在芬兰赫尔辛基大学上学的Linus Torvalds在自己的Intel 386计算机上开发了属于他自己的第一个程序,并利用Internet发布了他开发的源代码,将其命名为Linux,从而创建了Linux操作系统,并在同年公开了Linux的代码,从而开启了一个伟大的时代。在之后的将近30年的时间里,越来越多的工程师投入到Linux,帮助不断完善Linux的功能。现在的Linux系统架构凭借优秀的分层和模块化的设计,融合了大量的设备和不同的物理架构。
写这篇文章,也是对Linux系统的一个非常简单的介绍,主要讲解Linux的进程调度、内存管理、设备驱动、文件系统、网络模块。
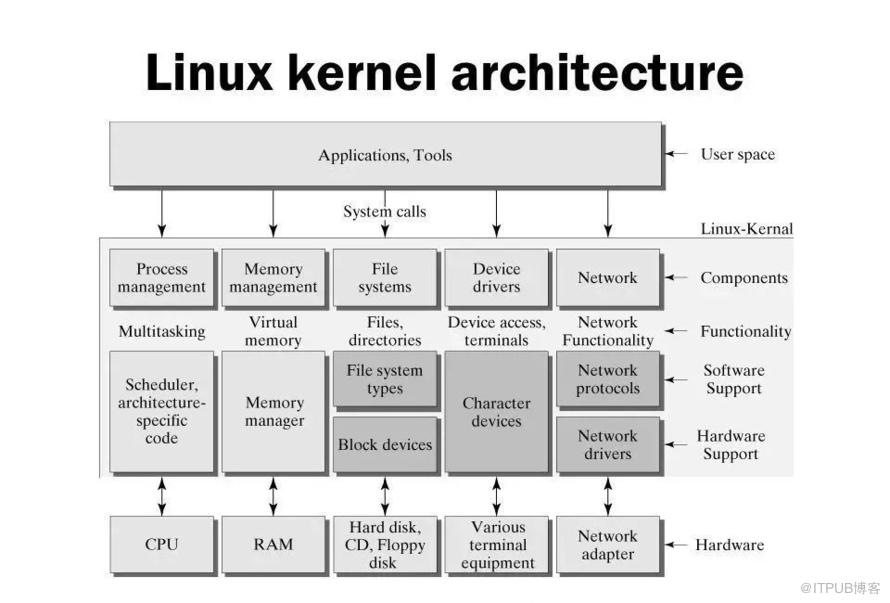
Linux内核架构图
上图就是Linux内核的架构图,从硬件层—>操作系统内核—>应用层,这套系统架构的设计应用于各类软硬件结合的系统上,比如物联网系统,单片机系统、机器人等领域。
进程调度
进程在Linux系统中称为process或task。操作系统中进程的数据结构包含很多元素,诸如:地址空间、进程优先级、进程状态、信号量、占用的文件等,往往用链表链接。
CPU在每个系统滴答(Tick)中断产生的时候检查就绪队列里边的进程(遍历链表中的进程结构体),如有符合调度算法的新进程需要切换,保存当前运行的进程的信息(包括栈、地址等)后挂起当前进程,然后运行新的进程,这就是进程调度。
CPU调度的基本依据是进程的优先级。调度的终极目标是让高优先级的进程能及时得到CPU的资源,低优先级的任务也能公平的分配到CPU资源。不过因为保存当前进程的信息所以进程的切换本身是有成本的,调度算法同样需要考虑效率。
在早期Linux内核中,就是采用轮询算法来实习的,内核在就绪的进程队列中选择高优先级的进程执行,每次运行相等时间,该算法简单直观,但仍然会导致一些低优先级的进程长时间不能执行。为了提高调度的公平性,在后来Linux内核(2.6)中,引入了CFS调度器算法。
CFS引入虚拟运行时间的概念,虚拟运行时间用task_struct->se.vruntime表示,通过它来记录和度量进程应该获得的CPU运行时间。在理想的调度情况下,任何时候所有的进程都应该有相同的task_struct->se.vruntime值。因为每个进程都是并发执行,没有进程会超过理想状态下应该占有的CPU时间。CFS选择需要运行的进程的逻辑基于task_struct->se.vruntime值,它总是选择task_struct->se.vruntime值最小的进程来运行(为了公平)。
CFS使用基于时间排序的红黑树来为将来进程的执行时间线。所有的进程按task_struct->se.vruntime关键字排序。CFS从树中选择最左边的任务执行。随着系统运行,执行过的进程会被放到树的右侧,逐步让每个任务都有机会成为最左边的进程,从而让每个进程都能获取CPU资源。
总的来说,CFS算法首先选一个进程,当进程切换时,该进程使用的CPU时间会加到该进程task_struct->se.vruntime里,当task_struct->se.vruntime的值逐渐增大到别的进程变成了红黑树最左边的进程时,最左边的进程被选中执行,当前的进程被抢占。
内存管理
内存,一种硬件设备,操作系统对其寻址,找到对应的内存单元,然后对其操作。CPU的字节长度决定了最大的可寻址空间,32位机器最大寻址空间是4G Bytes,64位机器最大寻址空间是2^64 Bytes。
最大寻址空间和物理内存大小无关,称之为虚拟地址空间。Linux内核把虚拟地址空间分为内核空间和用户空间。每个用户进程的虚拟地址空间范围是0~TASK_SIZE。从TASK_SIZE~2^32或2^64的区域保留给内核,不能被用户进程访问。
虚拟地址空间与物理内存的映射
绝大多数情况下,虚拟地址空间比实际物理内存大,操作系统需要考虑如何将实际可用的物理内存映射到虚拟地址空间。
Linux内核采用页表(page table)将虚拟地址映射到物理地址。虚拟地址和进程使用的用户&内核地址有关,物理地址用来寻址实际使用的内存。
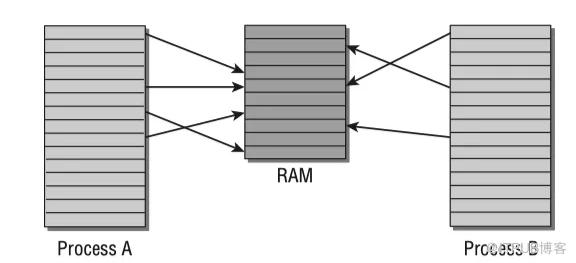
示例图上图所示,A和B进程的虚拟地址空间被分为大小相等的等份,称为页(page)。物理内存同样被分割为大小相等的页(page frame)。
进程A第1个内存页映射到物理内存(RAM)的第4页;进程B第1个内存页映射到物理内存第5页。进程A第5个内存页和进程B第1个内存页都映射到物理内存的第5页(内核可决定哪些内存空间被不同进程共享)。页表将虚拟地址空间映射到物理地址空间。
文件系统
Linux的核心理念:everything is file。Linux系统存在很多文件系统,比如EXT2,EXT3,EXT4,rootfs,proc等等,每一种文件系统都是独立的,有自己的组织方式、操作方法。为了支持不同的文件系统,内核在用户态和文件系统之间包含了一层虚拟文件系统(Virtual File System)。大多数内核提供的函数都能通过VFS定义的接口来访问。例如内核的子系统:字符设备、块设备,管道,socket等。另外,用于操作字符和块设备的文件是在/dev目录下真实文件,当读写操作执行的时候,其会被对应的驱动程序创建。
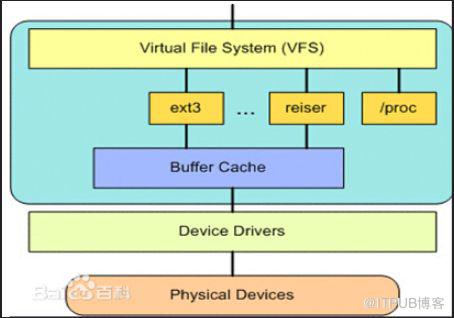
VFS结构图
Linux的虚拟文件系统四大对象:1. super block(超级块)2. inode(节点)3. dentry(目录)4. block(具体的数据块)
super block
代表一个具体的已经安装的文件系统,包含文件系统的类型、大小、状态等等。
inode
代表一个具体的文件,在Linux文件管理中,一个文件除了自身的数据外,还有一个附属信息,即文件的元数据(metadata),这个元数据用于记录文件的许多信息比如文件大小、创建人、创建时间等,这个元数据就包含在inode中。inode是文件从抽象—>具体的关键。inode存储了一些指针,这些指针指向存储设备的一些数据块,文件的内容就存储在这些数据块中。Linux想打开一个文件时,只需要找到文件对应的inode,然后沿着指针,将所有的数据块攒起来,就可以在内存中组成一个文件的数据了。
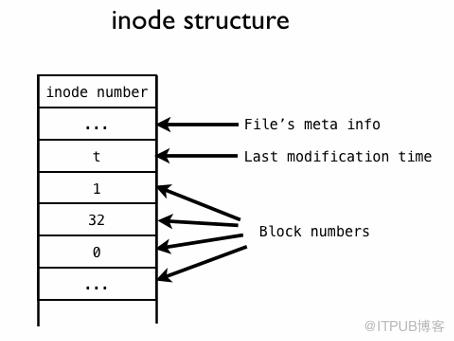
inode 结构
inode并不是组织文件的唯一方式,最简单的组织文件的方式,是把文件依次顺序的放入存储设备,但如果有删除操作的话,删除造成的空余空间夹杂在正常文件之间,很难利用和管理;复杂方式可以用来链表来做,每个数据块有个指针,指向属于同一文件的下一个数据块,这样的好处是可以利用零散的空余空间,坏处是对文件的操作必须按照线性方式进行,如果随机读取就必须要遍历链表,直到目标位置。由于这一遍历不是在内存进行,所以速度很慢。
inode既可以充分利用空间,在内存占据空间不与存储设备相关,解决了上面的问题。但inode也有自己的问题。每个inode能够存储的数据块指针总数是固定的。如果一个文件需要的数据块超过这一总数,inode需要额外的空间来存储多出来的指针。
dentry
代表一个目录项,是路径的一部分,比如一个路径/home/jackycao/hello.txt,那么目录项就有home、jackycao、hello.txt。
block
代表具体的数据,一个文件由分散的多个block组成,组织的方式由inode来指向。
设备驱动
与外设的交互,说白了就是输入(input)、操作(operate)、输出(ouput)的操作。
内核需要完成三件事情:1. 针对不同的设备类型实现不同的方法来寻址硬件。2. 必须为用户空间提供操作不同硬件设备的方法,且需要一个统一的机制来确保尽量有限的编程工作。
3. 让用户空间知道在内核中有哪些设备。
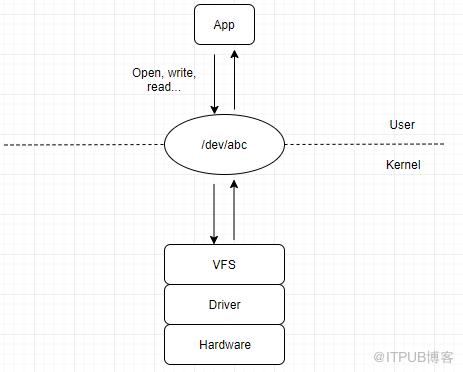
设备通信图
内核访问外设主要有两种方式:I/O端口和I/O内存映射。具体不展开介绍了。
内核动态接收外设发来的请求(数据)主要通过两种方式:轮询和中断。
轮询:周期性的访问查询设备是否有数据,如果有,便获取数据。这种方法比较浪费CPU资源。
中断:核心思想是外设有请求时主动通知CPU,中断的优先级最高,会中断CPU的当前进程运行,每个CPU都提供了中断线,每个中断由唯一的中断号识别,内核为每个应用的中断提供一个中断处理方法。当有数据已准备好可以给内核或者间接被一个应用程序使用的时候,外设出发一个中断。使用中断确保系统只有在外设需要处理器介入的时候才会通知CPU,提高了效率。
PS:块和扇区的概念:块是一个指定大小的字节序列,用于保存在内核和设备间传输的数据,块的大小可以被设置,默认是4096 bytes,扇区是存储设备操作的最小单元,默认是512 Bytes,块是一段连续的扇区。
网络
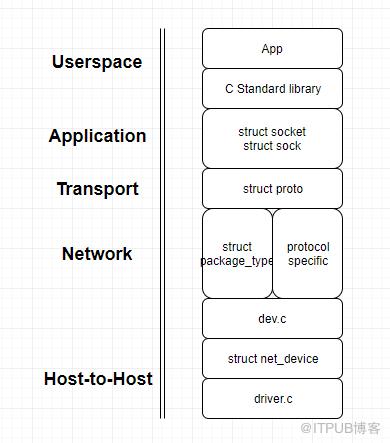
Linux的网络子系统的模型基于ISO的OSI模型,Linux内核中会简化相应层级。下图为Linux使用的TCP/IP参考模型。

网络模型
Host-to-Host层:相当于OSI模型的物理层和数据链路层,负责将数据从一个计算机传输到另一个计算机。在Linux内核的角度来看,这一层是通过网卡的设备驱动程序实现的。
Internet层:相当于OSI模型的网络层,负责让网络中的计算机可以交换数据(这些计算机并不一定是直连的)。该层同时负责传输的包分成指定的大小,因为包在传输路径上每个计算机支持的最大网络包的大小不一样,在传输时数据被分割成不同的包,在接收端再组合。该层为网络中的计算机分配唯一的网络地址。
Transprot层:相当于OSI模型的传输层,负责让两个连接的计算机上运行的应用程序之间的数据传输。比如,两台计算机上的客户端和服务端程序,通过端口号来识别通信的应用程序。
App层:相当于OSI模型的会话层、表示层、应用层,网络中不同计算机的两个应用程序建立连接后,这一层负责实际内容的传输。
Linux内核子系统的实现通过C代码实现,每个层只能和它上下层通信。
Linux网络分层图
参考资料
《Linux内核设计与实现》
《Linux内核完全剖析》《Linux设备驱动程序