
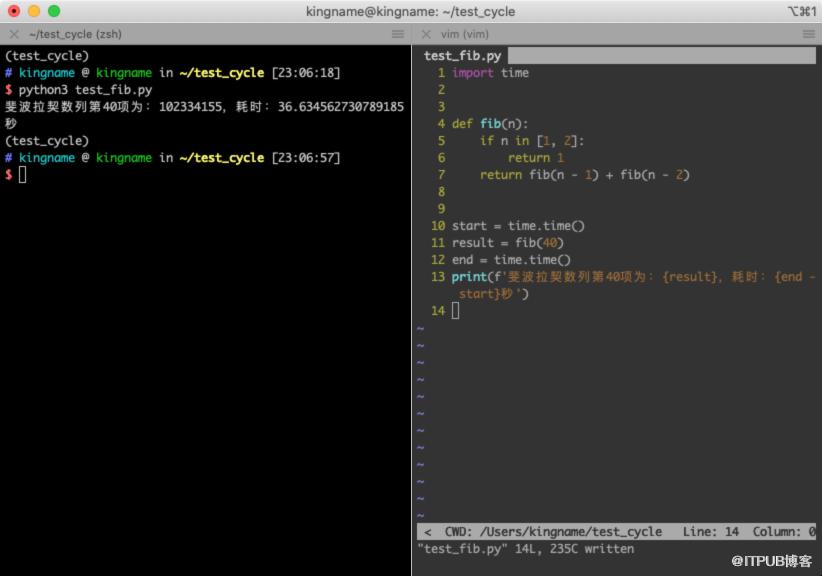
之前曾经测试计算斐波那契数列的几种方法,其中基于递归的方法是速度最慢的,例如计算第 40 项的值,需要 36 秒。如下图所示。
要提高运算速度,根本办法当然是改进算法。不过算法的提高是一个长期积累加上灵机一动的过程。我们今天要讲的,是一个不费脑筋,立竿见影的方法——把 Python 代码编译成 C 语言代码。通过 C 语言的运行效率来加速计算过程。
这个过程看起来很复杂,但实际上你并不需要编写一行 C 语言代码。你需要做的只是使用一个叫做 Cython 的库把 Python 代码编译为 C 语言代码即可。
首先我们来安装 Cython,就像安装普通的第三方库一样:
python3 -m pip install cython
安装完成以后,我们单独写计算斐波那契数列的函数:
def fib(n):
if n in [1, 2]:
return 1
return fib(n - 1) + fib(n - 2)非常简单的递归写法。然后关键来了,我们要把这个文件保存为fast_fib.pyx。注意后缀是.pyx。如下图所示:

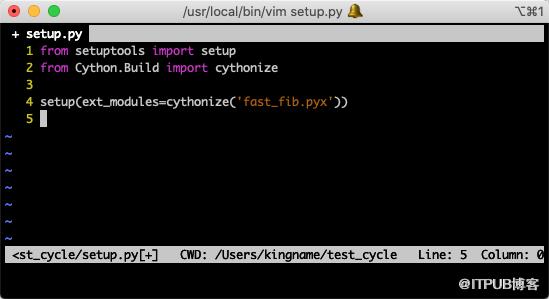
然后我们创建一个setup.py文件,文件内容如下:
from setuptools import setup
from Cython.Build import cythonize
setup(ext_modules=cythonize('fast_fib.pyx'))如下图所示:
这个文件的作用,就是调用 Cython 的cythonize函数把 Python 代码转换为 C 代码。
接下来,开始编译代码,执行如下命令:
python3 setup.py build_ext --inplace
我的 Python 是 Python3.7,所以运行完成以后,会生成一个fast_fib.cpython-37m-darwin.so,如果你的 Python 是3.8,这个文件名可能是fast_fib.cpython-38m-darwin.so。这个文件你可以改名字,例如改成fast_fib.so。
还有一个文件叫做fast_fib.c。不过你不用打开这个文件,因为它有3200多行。并且你甚至可以直接把它删掉。真正有用的只有这个fast_fib.cpython-38m-darwin.so文件。
你需要做的,仅仅是直接调用你的函数。我们另外创建一个文件test_fast_fib.py,内容如下:
import time
from fast_fib import fib
start = time.time()
result = fib(40)
end = time.time()
print(f'斐波拉契数列第40项为:{result},耗时:{end - start}秒')运行效果如下图所示:
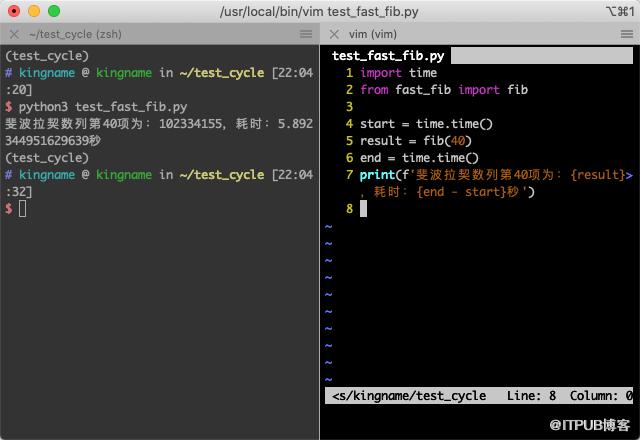
计算斐波那契数列第40项只需要5秒钟,速度妥妥变成 Python 版本的7倍。
使用 Cython,不仅可以提高程序的运行速度,还可以把你的核心代码转换为.so文件,防止别人反编译看到你的代码。
关于 Cython 的更多介绍,请阅读它的官方文档[1]
有同学可能会问,当前文件夹下面既然有fast_fib.pyx文件,为什么当我们执行from fast_fib import fib的时候,不会从这个文件里面导入 Python 版本的代码?
这是因为,import只会从后缀为.py/.pyc/.pyo/.so的文件中导入模块,不会进入.pyx文件中寻找。
参考资料
[1]
官方文档: https://cython.readthedocs.io/


