Posted by Socrates on | Featured
虽然SQL是为关系模型而发明的,但它对于许多形式来说都非常有效数据,包括类型异构、嵌套和无模式的文档数据。 Couchbase Capella 拥有操作引擎和分析引擎。操作和分析引擎都支持用于数据建模的 JSON 和用于查询的 SQL++。由于操作和分析用例具有不同的工作负载要求,因此 Couchbase 的两个引擎具有不同的功能,这些功能专为满足每个工作负载的要求而定制。本文重点介绍了 Couchbase 的新分析服务 Capella Columnar 服务的一些新特性和功能。
为了改进实时数据处理,Couchbase 推出了 Capella Columnar 服务。这项新服务有许多差异化技术,包括无模式数据引擎的按列存储及其处理。在本文中,我们将概述为 JSON 实现按列存储的挑战以及 柱状服务来应对这些挑战。
数据的行式和列式存储
按行存储
使用按行存储,表的每一行都存储为表数据页内的连续单元。单行的所有字段连续存储在一起,后面是下一行的字段,依此类推。每行可以有 1 到 N 列,要访问任何一列,整行都会被放入内存并进行处理。这对于事务操作非常有效,因为通常需要所有或大多数字段。
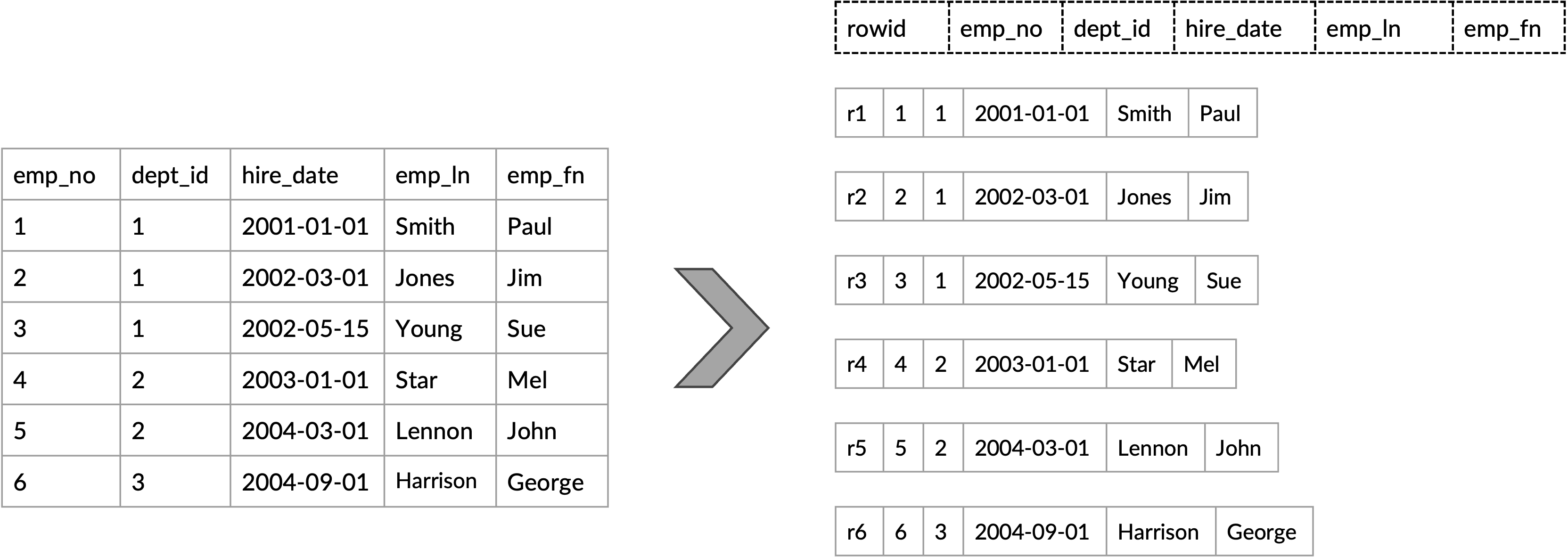 图 1:逻辑表到物理行的表示
图 1:逻辑表到物理行的表示
按列存储
按列存储,另一方面,存储数据的每一列(也称为 JSON 文档中的字段)分别。单列的所有值都是连续存储的。这种格式对于涉及查询多行上的几列的分析和大量读取操作特别有效,因为它可以更快地读取相关数据、更好的压缩以及更有效地使用磁盘 I/O 请求等资源。![图 2:逻辑表到物理按列表示]()
图 2:逻辑表到物理按列表示
文档方式(类似于行方式)存储
集合中的每个文档都存储为连续的单元。这意味着单个文档的所有字段子字段存储在一起,后面是下一个文档的字段,依此类推。这种方法对于事务操作非常有效,因为它允许快速检索完整的文档。但是,对于仅访问多个文档中的少数字段的分析查询来说,效率可能较低,因为还会读取每个文档中不必要的数据。
使用 JSON(文档)数据模型时,与关系表中的单行相比,每个文档中通常会包含更多字段。但是,对于分析工作负载,每个查询仍然从每个文档中读取一些字段。因此,按列存储对文档存储的潜在好处甚至超过了关系数据库。但是,实施起来也不容易!在平面关系表中,模式是明确定义的,并且列的类型是先验已知的,用于存储和查询此类表的数据的技术是很好理解的。然而,为 JSON 文档存储实现按列存储引擎很困难,因为许多使 JSON 成为现代应用程序理想选择的因素却让按列存储变得困难!以下是主要原因:
- 架构灵活性
- 嵌套和复杂的结构
- 处理异构类型
- 动态架构更改
- 压缩和编码挑战
让我们简要研究一下这些挑战:
- 架构灵活性:JSON 是无架构的,这意味着每个文档都是自描述的,并且可以具有包含不同字段的不同结构。这种灵活性与传统关系数据库僵化的预定义模式形成鲜明对比。在客户文档的 JSON 模型中,在不同的子结构中,一条记录可能具有地址字段,而另一条记录可能没有,如下例所示。在列式数据库中,这种不可预测性使得定义一致的列结构变得具有挑战性。
{
“客户 ID”:101,
“名称”:“爱丽丝·史密斯”,
“电子邮件”:“alice.smith@example.com”,
“地址”: {
“街道”:“苹果街 123 号”,
“城市”:“仙境”,
“邮编”:“12345”
}
}
{
“客户 ID”:102,
“姓名”:“鲍勃·琼斯”,
“电子邮件”:“bob.jones@example.com”
// 注意:没有地址字段
}
{
“客户 ID”:103,
“姓名”:“詹姆斯·布朗”,
“电子邮件”:“james.brown@example.com”,
“地址”: {
"street": "Kenmare House, The Fossa Way",
// 县首次出现
"county": "凯里郡",
// 邮政编码而不是 zip
“邮政编码”:“V93 A0XH”,
// 国家首次出现
“国家”:“爱尔兰”
}
}
清单 1:客户数据
嵌套和复杂结构:JSON 支持任意嵌套结构,例如对象内数组内的对象。列式存储通常最适合平面表格数据,并且将这些复杂的分层结构映射到列可能非常复杂。如下例所示,单个 JSON orders 文档可能包含一个 items 列表,并且每个项目可能有自己的属性。简单地将其展平为列将具有挑战性,并且可能会导致大量稀疏列。在下面的示例中,带有 item_id = 1001 的订购商品是唯一具有适用促销代码的商品,因此在所有其他商品中都缺少该代码(类似于关系数据库中的 NULL)。
{
“订单id”:5002,
“客户 ID”:101,
“日期”:“2023-11-24”,
“项目”: [
{
“项目 ID”:1001,
“数量”:1,
“购买价格”:1200.00,
// 唯一具有适用促销代码的商品
“促销”:“黑色星期五”
},
{
“项目 ID”:1002,
“数量”:1,
“购买价格”:30.00
}
]
}
{
“订单id”:5003,
“客户 ID”:103,
“日期”:“2023-02-15”,
“项目”: [
{
“项目 ID”:1003,
“数量”:1,
“购买价格”:80.00
},
{
“项目 ID”:1004,
“数量”:2,
“购买价格”:300.00
},
{
“项目 ID”:1005,
“数量”:1,
“购买价格”:99.00
}
]
}
清单 2:订单数据
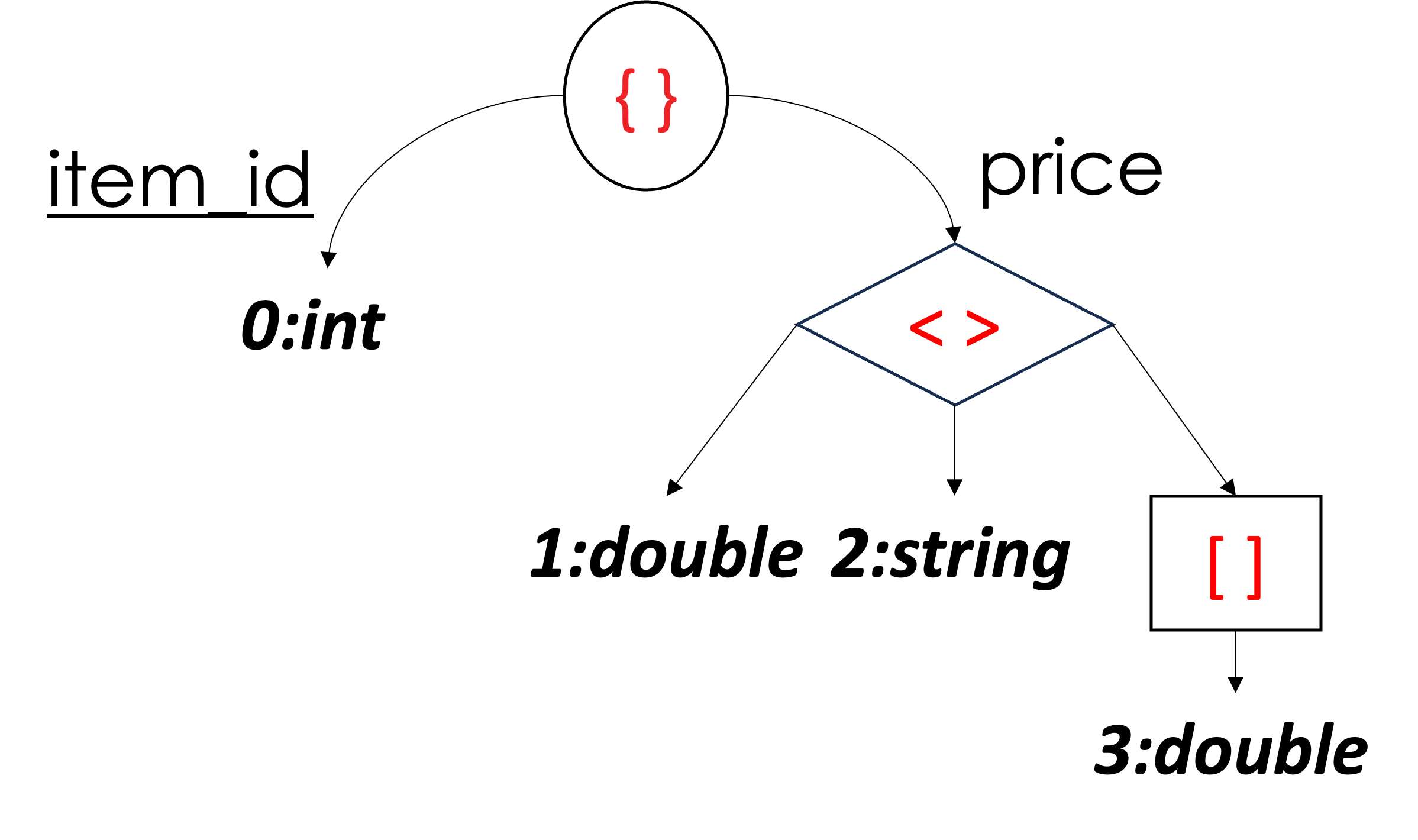
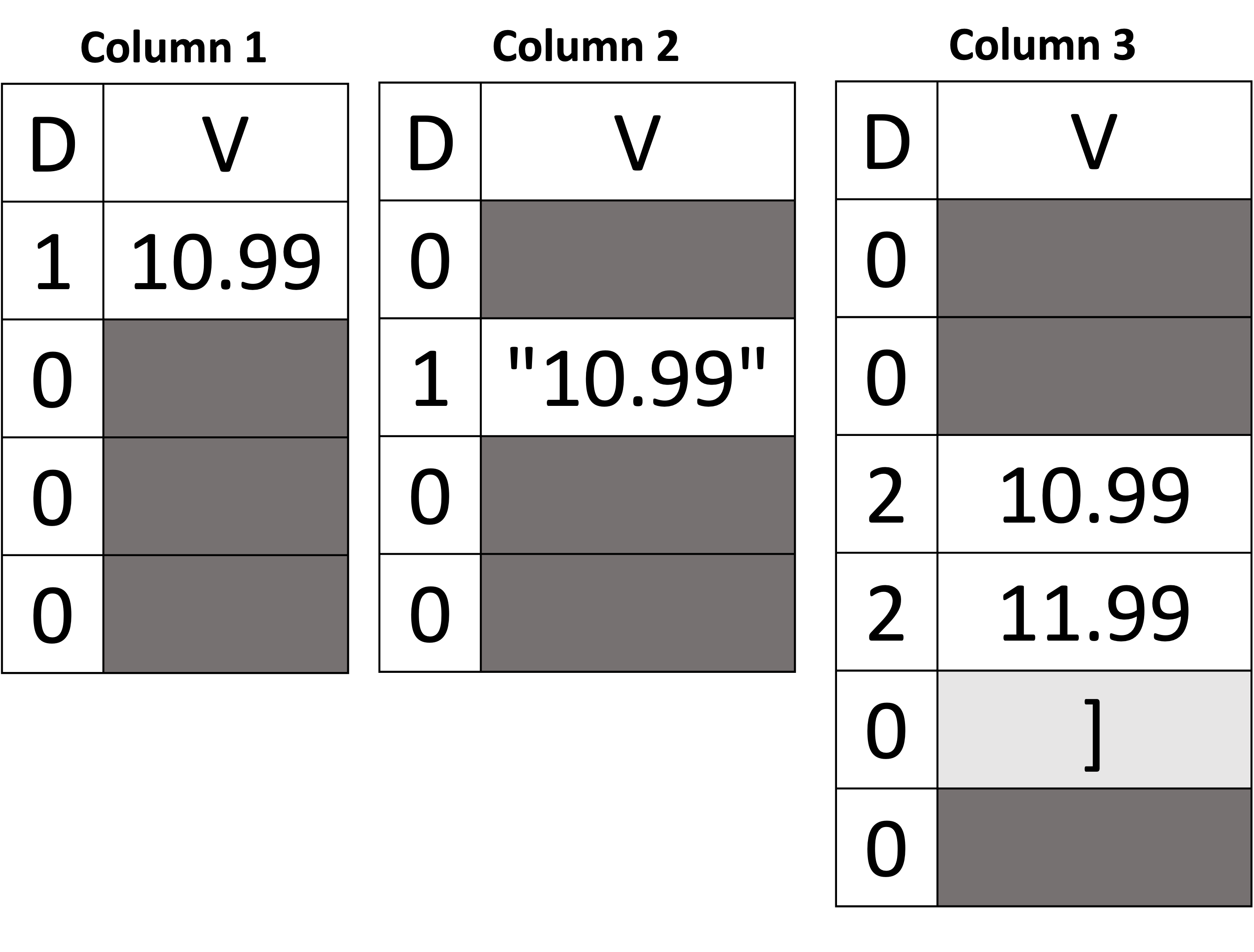
处理异构类型:JSON 值可以是不同的类型(例如字符串、数字、布尔值,甚至是对象和数组等复杂类型)。在不同文档的单个字段中,数据类型可能会有所不同,而列式关系数据库甚至列式文件格式通常要求列中的所有数据都具有相同的类型。如果“价格”字段有时存储为字符串(“10.99”),有时存储为数字(10.99),甚至存储为数组([10.99, 11.99])(假设存储所有季节性价格),这会使过程变得复杂从以列式格式存储此类数据的源中存储和检索数据,其中数据类型预计是统一的。
{
“项目id”:3003,
「价格」:10.99
}
{
“项目id”:3004,
“价格”:“10.99”
}
{
“项目id”:3005,
“价格”:[10.99,11.99]
}
{
“项目id”:3006,
// 价格缺失(可能表示价格不可用或未知)
}
清单 3:项目数据
动态架构更改:由于 JSON 是无架构的,因此数据结构可能会随着时间的推移而发生变化。这种灵活性是 JSON 对于现代应用程序的吸引力之一。对于架构不经常更改的列式关系数据库来说,这可能会出现问题。然而,在无模式文档存储中,添加新字段甚至更改现有字段都很简单。例如,应用程序可能开始捕获其他用户数据,例如客户地址,或将价格从一种数据类型更改为另一种数据类型。在关系列式数据库中,这需要添加一个新列,这可能是一项相对繁重的操作(尤其是在数据仓库中),或者在更改字段的数据类型的情况下甚至是不可能的。
<表格样式=“最大宽度:100%;宽度:自动;表格布局:固定;显示:表格;”宽度=“自动”>
<标题>
|
添加新字段:客户 |
字段的数据类型更改:Items |
<正文>
| Upsert |
之前
{
“客户 ID”:102,
“姓名”:“鲍勃·琼斯”,
“电子邮件”:“bob.jones@example.com”
// 注意:没有地址字段
}
|
{
“项目 ID”:4004,
“价格”:99.00
}
|
| 更新插入后 |
{
“客户 ID”:102,
“姓名”:“鲍勃·琼斯”,
“电子邮件”:“bob.jones@example.com”,
// 添加地址
“地址”: {
“城市”:“哥谭”,
"country": "神秘之地",
“邮编”:54321
}
}
|
{
“项目 ID”:4004,
// 价格更改为
// 数组(季节性定价)
“价格”:[99.99,109.99]
}
|
压缩和编码挑战:关系数据库中列式存储的优势之一是能够使用非常高效的编码方案,因为相同类型和相同域的值是连续存储的,并且架构与数据分开存储。然而,JSON 的多样性和复杂性使得有效应用它们变得困难。对于纯数字列,简单的编码和压缩技术可能非常有效。但是,如果列以不可预测的方式混合字符串、数字、空值和缺失(甚至数组和对象),那么找到有效的编码策略就会变得更加复杂甚至不可能。
Capella Columnar 中的列式存储引擎
对于按列存储,Capella Columnar 使用本技术论文中描述的技术和方法的扩展版本:基于无模式 LSM 的文档存储的列格式。您可以在 Wail Alkowaileet 的博士论文走向分析优化的文档存储中找到更多详细信息。这些技术最初是为 Apache AsterixDB 实现的,现在是 Couchbase Capella Columnar 的一部分。
存储概述
Capella Columnar 中的列式技术解决了文档存储数据库在分析大量半结构化数据时的局限性,因为它们无法有效地使用列主布局,当然,这对于分析工作负载来说更有效。目标是为 JSON 提供高效的列存储,同时保留 JSON 数据模型的所有优点并改进查询处理。在本文的这一部分中,我们将描述这些领域的增强和改进,以克服前面描述的挑战。请参阅上述论文和论文了解更多详细信息。
本文的其余部分介绍了新的 Capella 柱状服务产品的以下方面:
- JSON 数据提取和列化管道
- 柱状 JSON 表示
- 列式存储物理布局
- 柱状集合的查询处理
JSON 数据摄取和列化管道
Capella Columnar 可以从各种数据源(例如 Capella 数据服务)或其他外部源(例如其他文档存储和关系数据库)获取数据。 Capella Columnar 的存储引擎是一种基于日志结构合并树 (LSM) 的引擎,其工作原理如图 3 所示。当 JSON 文档从受支持的源之一到达 Capella Columnar 时,这些文档将被插入到内存组件中 (在文献中也称为内存表),它是完全存储在内存中的 B+ 树。一旦内存组件满了,插入的文档就会被写入磁盘(通过刷新操作)到磁盘组件(在文献中也称为 SSTable),这是一个 B+-树片段完全存储在磁盘上。然后,释放的内存组件可以重新用于一批新文档。
LSM 的批处理特性提供了一个机会来“重新思考”内存组件中的文档应如何写入并存储在磁盘上。在 Capella Columnar 中,我们借此机会 (1) 推断数据的架构,以及 (2) 从摄取的 JSON 文档中提取值并将其存储到列中 – 两者均由Columnar Transformer 执行,如图所示如图 3 所示。推断的模式用于识别这些文档中出现的列 – 稍后将讨论更多内容。请注意,Capella Columnar 同时执行 (1) 和 (2)(即,在每个刷新的 JSON 文档上一次传递)。在刷新操作结束时,推断的架构将持久保存到新创建的磁盘 LSM 组件中,以便在需要时进行检索。

图 3:数据摄取工作流程
Capella Columnar 中的柱状 JSON 表示
现在我们知道我们有机会 (1) 推断架构并 (2) 对摄取的 JSON 文档进行列化,主要问题是:我们如何将这些摄取的 JSON 文档表示为列并允许存储它们、更新和检索——考虑到 JSON 数据模型带来的五个挑战?
Capella Columnar 使用本文中描述的方法表示摄取的 JSON 文档,该方法扩展了Dremel 格式(由 Google 在论文 Dremel:Web 的交互式分析-扩展数据集)来应对这五个挑战。值得注意的是,Apache Parquet 是 schema-ful Dremel 格式的开源实现,因此,如果没有我们的扩展,它无法在文档数据库中按原样使用 Apache Parquet。接下来,我们将描述 Capella Columnar 如何使用我们的扩展 Dremel 格式以柱状布局表示摄取的 JSON 文档。
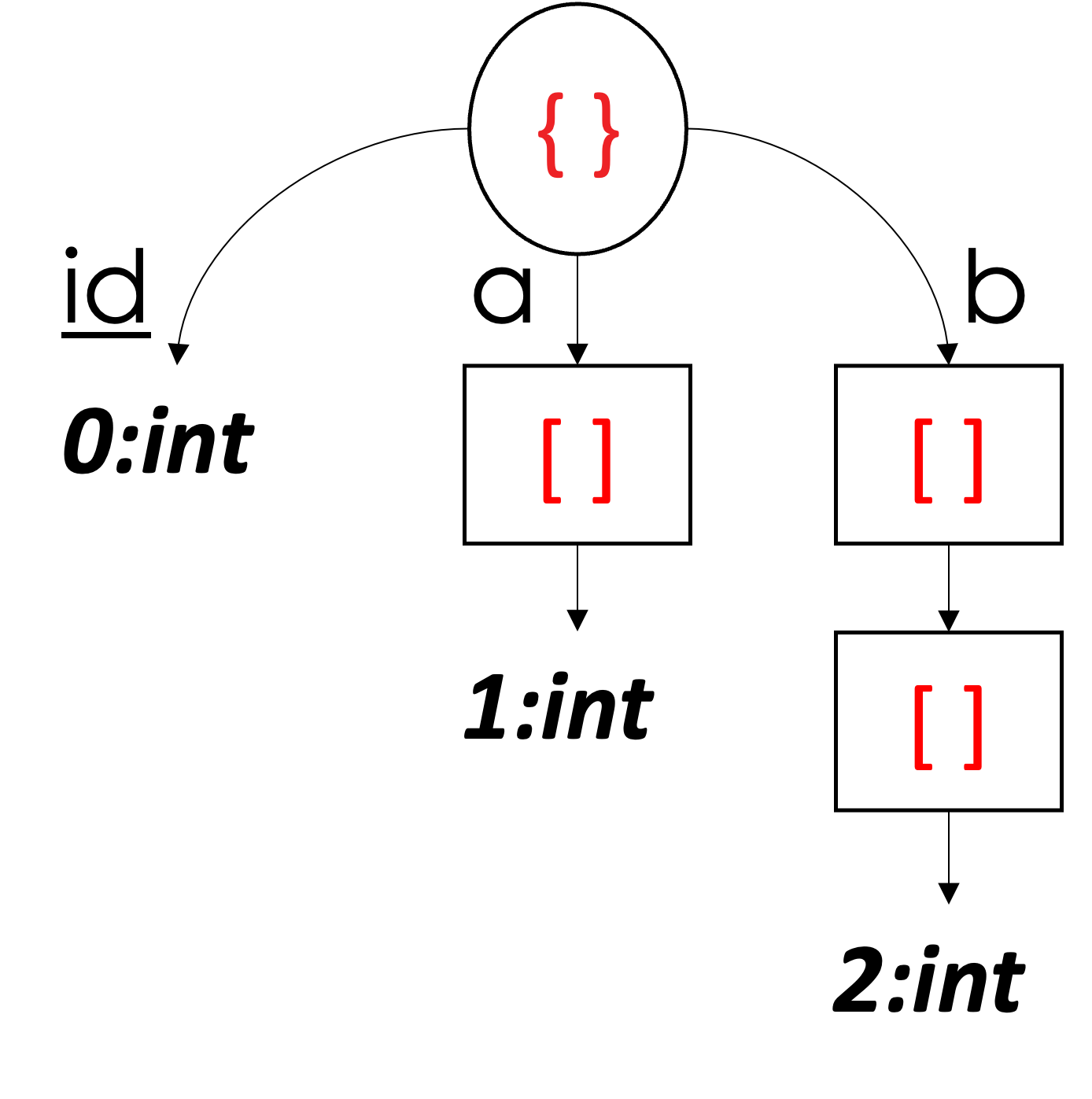
让我们首先通过一个简单的示例来说明如何表示清单 1 中的第一个 Customers JSON 文档,如下面的图 4 所示。
<表格样式=“最大宽度:100%;宽度:自动;表格布局:固定;显示:表格;”宽度=“自动”>
<标题>
|
文档
|
推断模式
|
<正文>
{
“客户 ID”:101,
“名称”:“爱丽丝·史密斯”,
“电子邮件”:“alice.smith@example.com”,
“地址”: {
“街道”:“苹果街 123 号”,
“城市”:“仙境”,
“邮编”:“12345”
}
}
|

数据列

图 4:将第一个 Customers JSON 文档表示为列
首先,我们看到架构是一个树结构,描述了 Customers 文档中的内容。从树的根(JSON 对象或文档)开始,我们看到它有四个子节点。根的子级代表根的字段,即 customer_id、name、email 和 address。请注意,地址也是嵌套在主文档中的一个对象(或子文档),并且对象地址有三个子对象:street >、城市和邮政编码。我们可以看到标量值是模式树结构的叶子——无论是根文档还是地址的子文档。每个标量值都分配有我们所说的“列索引”。例如,叶 0:int 告诉我们,字段 customer_id(集合的主键 (PK))是一个整数,并被分配列索引 0。同样,4:string 告诉我们 address 对象中的 city 值的类型string 并被分配列索引 4。从模式中,我们可以推断出我们有六列(即六个叶子,每个叶子被分配一个范围 [0, 5] 内的列索引)。
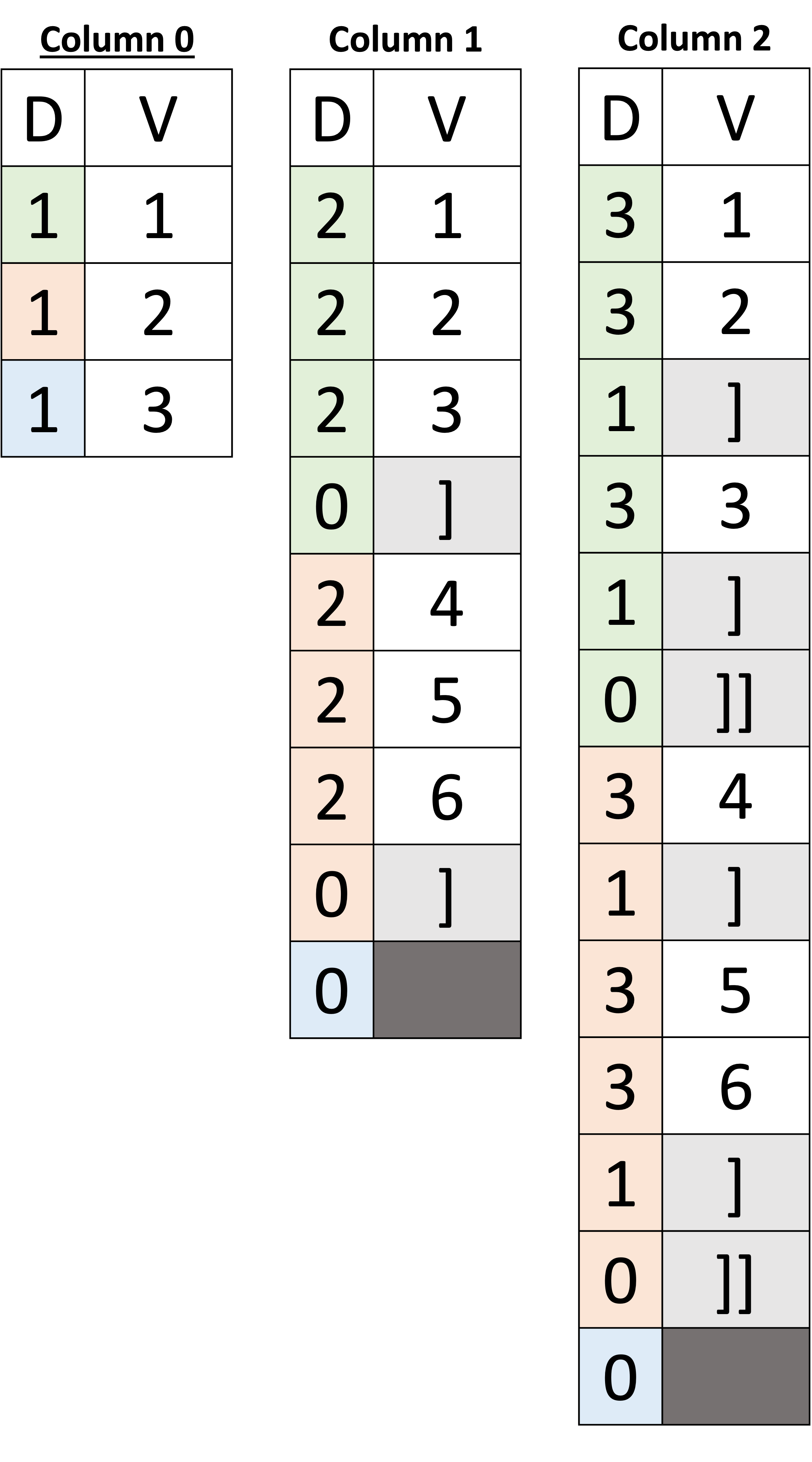
因此,模式为我们提供了文档结构和值类型的描述,但不是值本身。在 Capella Columnar 中,文档的值作为列与模式分开存储。图 4 显示了“数据列”(准确地说是六列),每列表示为两个向量(在图中描绘为具有两列的表格,以便读者更容易理解),称为“D”和“V” ”。每列中的“D”向量就是我们所说的(如 Dremel)是D定义级向量,“V”是V价值向量。从图中可以推断,Value 的向量存储 JSON 文档中的实际值。另一方面,定义级别的向量用作“元值”来确定特定值是否存在或不存在(即 NULL 或缺失)。我们以第 1 列为例,它对应于示例中的 name 字段。我们看到值“Alice Smith”的定义级别等于 1,这告诉我们第 1 列的该特定值存在,并且其关联值为“Alice Smith”。现在,我们来看第 4 列,它对应于 address 子文档中的 city。它的定义级别等于2,值为“Wonderland”。那么,为什么子文档address的name定义级别为1,而city定义级别为2呢?定义级别(顾名思义)告诉我们在给定该特定值的推断模式定义的情况下,值出现在哪个(嵌套)级别。因此,名称是根文档的子文档。因此,它是从根开始的一级,而城市是子文档地址的子级,因此,它是从根开始的两级(根→名称与根→地址→城市)。
为了更好地理解缺失值的处理,我们现在添加以下文档:
<表格样式=“最大宽度:100%;宽度:自动;表格布局:固定;显示:表格;”宽度=“自动”>
<标题>
|
文档
|
数据列
|
<正文>
{
“客户 ID”:201,
“名称”:“蝙蝠侠”,
“地址”: {
“城市”:“哥谭”
}
}
|