
“没有什么是肯定的, 除了死亡和税收。
这不是用玫瑰床或修剪整齐的绿草制作的数据集。更严重一点。让我们看看能不能在这里快速学到任何东西。数据集如下所示。
“名称”: “nchs-死亡的主要原因: 美国”,
“归因”: “国家卫生统计中心”,
公共数据集可在https://data.cdc.gov/api/views/bi63-dtpu/rows.json?accessType=DOWNLOAD
第1步:将文件下载到本地文件中 (例如 health. json)。将此文件上载到 couchbase 群集中的一个节点。
-optcochbase/cb导入 json-c couchbase://127.0.0.1-u 管理员-p dical-b 原因-d file://health.json-g toe:0-f 样本
>产生原因的主要指标;
步骤 2: 将数据导入到称为 “原因” 的存储桶中。创建存储桶后, 创建主索引。你需要这个来查询。
步骤 3。检查数据的结构。
所有数据都在一个 samgle json 文档中提供。正因为如此, infer 也帮不上忙。您必须手动检查和理解结构。这些数据在典型的政府数据集中, 在简单数组中包含大量数据, 并在元数据中给出每个实体的含义。
简单数组:
<strong>select data from cause ;</strong>
这只是包含一个没有架构的数据数组。对于公共数据集, 架构位于元字段中。

让我们将结构转换为简单的 json 键值对, 以便我们能够更有效地处理这些位。您可以在本文中了解有关这种魔力是如何发生的更多信息。
WITH cs AS (
SELECT
meta.`view`.columns [*].fieldName f,
data
FROM
cause
)
SELECT
o
FROM
cs UNNEST cs.data AS d1
LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END;
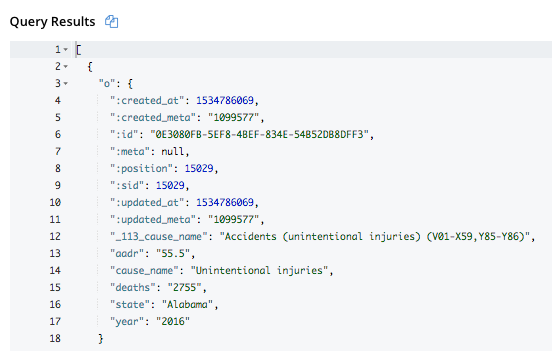
任务 1: 按年份找出一个州大多数死亡的原因。
with 子句 (csdata) 中的公共表表达式 (cte) 将复杂的 json 数据转换为平面 json。你可以动态地这样做, 也可以这样做一次, 然后再插入一个水桶, 就像我在关于纽约婴儿名字的文章中所讨论的那样。在本文中, 我使用 cde。
WITH csdata as (
WITH cs AS (
SELECT
meta.`view`.columns [*].fieldName f,
data
FROM
cause
)
SELECT
o
FROM
cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END
)
SELECT
c.o.state,
c.o.year,
c.o.cause_name,
COUNT(c.o.cause_name),
SUM(TONUMBER(c.o.deaths)) totdeaths
FROM
csdata as c
WHERE
c.o.state <> "United States"
and c因为名字 & 它; & gt;”一切原因” 集团 c.o.state, c.o.year, c.o.cause 名称订单总死亡人数 desc, c.o.state, c.o.year

在这种情况下, 加州所有的死亡人数都排在首位, 主要原因是其人口。
任务 2: 找出2016年每个州的主要死亡原因。
查询 2:使用上一个查询中的结果集, 然后使用 first _ value () 窗口函数来确定最大原因。按状态分区 (在 over by 子句中) 将为您提供按状态和 order by dx. todll 子句中的分区将为您提供每个状态中的最高原因。
WITH csdata as (
WITH cs AS (
SELECT
meta.`view`.columns [*].fieldName f,
data
FROM
cause
)
SELECT
o
FROM
cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END
),
d2 as(
SELECT
c.o.state,
c.o.year,
c.o.cause_name,
SUM(TONUMBER(c.o.deaths)) totdeaths
FROM
csdata as c
WHERE
c.o.state <> "United States"
and c.o.cause_name <> "All causes"
and c.o.year = "2016"
GROUP BY
c.o.state,
c.o.year,
c.o.cause_name),
d3 as (
SELECT dx.state, dx.cause_name, dx.totdeaths,
FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topreason,
FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state ORDER BY dx.totdeaths DESC) topcount
FROM d2 dx)
SELECT d3
FROM d3
WHERE d3.topcount = d3.totdeaths
order by d3.state

任务 3:按州了解从1999年到2016年的最大原因是如何变化的。
查询 3:只需生成所有年份 (1999-2016) 的报告, 然后确定最高原因, 并最终通过按状态、年份分组和获取最高原因的 max (拓扑) 来获得最高原因。
WITH csdata as (
WITH cs AS (
SELECT
meta.`view`.columns [*].fieldName f,
data
FROM
cause
)
SELECT
o
FROM
cs UNNEST cs.data AS d1 LET o = OBJECT p :d1 [ARRAY_POSITION(cs.f, p)] FOR p IN cs.f END
),
d2 as(
SELECT
c.o.state,
c.o.year,
c.o.cause_name,
SUM(TONUMBER(c.o.deaths)) totdeaths
FROM
csdata as c
WHERE
c.o.state <> "United States"
and c.o.cause_name <> "All causes"
GROUP BY
c.o.state,
c.o.year,
c.o.cause_name),
d3 as (
SELECT dx.state, dx.year,
FIRST_VALUE(dx.cause_name) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC ) topreason,
FIRST_VALUE(dx.totdeaths) OVER(PARTITION BY dx.state, dx.year ORDER BY dx.totdeaths DESC) topcount
FROM d2 dx)
SELECT d3.state , d3.year , d3.topreason, max(d3.topcount) topcount
FROM d3
GROUP BY d3.state, d3.year, d3.topreason
order by d3.state, d3.year下面是部分结果。



可视化这给我们提供了以下直方图。
