
01背景
闲鱼目前实际生产部署环境越来越复杂,横向依赖各种服务盘宗错节,纵向依赖的运行环境也越来越复杂。当服务出现问题的时候,能否及时在海量的数据中定位到问题根因,成为考验闲鱼服务能力的一个严峻挑战。
线上出现问题时常常需要十多分钟,甚至更长时间才能找到问题原因,因此一个能够快速进行自动诊断的系统需求就应用而生,而快速诊断的基础是一个高性能的实时数据处理系统。这个实时数据处理系统需要具备如下的能力:
1、数据实时采集、实时分析、复杂计算、分析结果持久化。
2、可以处理多种多样的数据。包含应用日志、主机性能监控指标、调用链路图。
3、高可靠性。系统不出问题且数据不能丢。
4、高性能,底延时。数据处理的延时不超过3秒,支持每秒千万级的数据处理。
本文不涉及问题自动诊断的具体分析模型,只讨论整体实时数据处理链路的设计。
02输入输出定义
为了便于理解系统的运转,我们定义该系统整体输入和输出如下:
输入:
服务请求日志(包含traceid、时间戳、客户端ip、服务端ip、耗时、返回码、服务名、方法名)
环境监控数据(指标名称、ip、时间戳、指标值)。比如cpu、 jvm gc次数、jvm gc耗时、数据库指标。
输出:
一段时间内的某个服务出现错误的根因,每个服务的错误分析结果用一张有向无环图表达。(根节点即是被分析的错误节点,叶子节点即是错误根因节点。叶子节点可能是一个外部依赖的服务错误也可能是jvm异常等等)。
03架构设计
在实际的系统运行过程中,随着时间的推移,日志数据以及监控数据是源源不断的在产生的。每条产生的数据都有一个自己的时间戳。而实时传输这些带有时间戳的数据就像水在不同的管道中流动一样。

如果把源源不断的实时数据比作流水,那数据处理过程和自来水生产的过程也是类似的:

自然地,我们也将实时数据的处理过程分解成采集、传输、预处理、计算、存储几个阶段。
整体的系统架构设计如下:
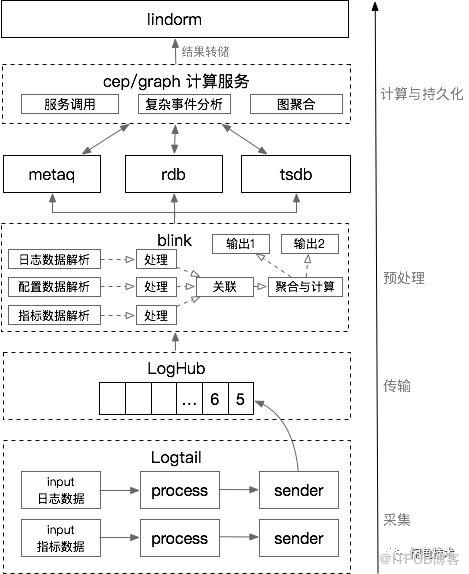
采集
采用阿里自研的sls日志服务产品(包含logtail+loghub组件),logtail是采集客户端,之所以选择logtail是因为其优秀的性能、高可靠性以及其灵活插件扩展机制,闲鱼可以定制自己的采集插件实现各种各样数据的实时采集。

传输
loghub可以理解为一个数据发布订阅组件,和kafka的功能类似,作为一个数据传输通道其更稳定、更安全,详细对比文章参考:https://yq.aliyun.com/articles/35979?spm=5176.10695662.1996646101.searchclickresult.6f2c7fbe6g3xgP
预处理
实时数据预处理部分采用blink流计算处理组件(开源版本叫做flink,blink是阿里在flink基础上的内部增强版本)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。Jstorm由于没有中间计算状态的,其计算过程中需要的中间结果必然依赖于外部存储,这样会导致频繁的io影响其性能;SparkStream本质上是用微小的批处理来模拟实时计算,实际上还是有一定延时;Flink由于其出色的状态管理机制保证其计算的性能以及实时性,同时提供了完备SQL表达,使得流计算更容易。
计算与持久化
数据经过预处理后最终生成调用链路聚合日志和主机监控数据,其中主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。tsdb由于其针对时间指标数据的特别存储结构设计,非常适合做时序数据的存储与查询。调用链路日志聚合数据,提供给cep/graph service做诊断模型分析。cep/graph service是闲鱼自研的一个应用,实现模型分析、复杂的数据处理以及外部服务进行交互,同时借助rdb实现图数据的实时聚合。
最后cep/graph service分析的结果作为一个图数据,实时转储在lindorm中提供在线查询。lindorm可以看作是增强版的hbase,在系统中充当持久化存储的角色。04详细设计与性能优化
采集
日志和指标数据采集使用logtail,整个数据采集过程如图:

其提供了非常灵活的插件机制,共有四种类型的插件:
- inputs: 输入插件,获取数据。
- processors: 处理插件,对得到的数据进行处理。
- aggregators: 聚合插件,对数据进行聚合。
- flushers: 输出插件,将数据输出到指定 sink。
由于指标数据(比如cpu、内存、jvm指标)的获取需要调用本地机器上的服务接口获取,因此应尽量减少请求次数,在logtail中,一个input占用一个goroutine。闲鱼通过定制input插件和processors插件,将多个指标数据(比如cpu、内存、jvm指标)在一个input插件中通过一次服务请求获取(指标获取接口由基础监控团队提供),并将其格式化成一个json数组对象,在processors插件中再拆分成多条数据,以减少系统的io次数同时提升性能。
传输
数据传输使用LogHub,logtail写入数据后直接由blink消费其中的数据,只需设置合理的分区数量即可。分区数要大于等于blink读取任务的并发数,避免blink中的任务空转。
预处理
预处理主要采用blink实现,主要的设计和优化点:
编写高效的计算流程

blink是一个有状态的流计算框架,非常适合做实时聚合、join等操作。
在我们的应用中只需要关注出现错误的的请求上相关服务链路的调用情况,因此整个日志处理流分成两个流:
1、服务的请求入口日志作为一个单独的流来处理,筛选出请求出错的数据。
2、其他中间链路的调用日志作为另一个独立的流来处理,通过和上面的流join on traceid实现出错服务依赖的请求数据塞选。
如上图所示通过双流join后,输出的就是所有发生请求错误相关链路的完整数据。
设置合理的state生命周期
blink在做join的时候本质上是通过state缓存中间数据状态,然后做数据的匹配。而如果state的生命周期太长会导致数据膨胀影响性能,如果state的生命周期太短就会无法正常关联出部分延迟到来的数据,所以需要合理的配置state生存周期,对于该应用允许最大数据延迟为1分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒state.backend.type=niagarastate.backend.niagara.ttl.ms=60000
开启MicroBatch/MiniBatch
MicroBatch 和 MiniBatch 都是微批处理,只是微批的触发机制上略有不同。原理上都是缓存一定的数据后再触发处理,以减少对 state 的访问从而显著提升吞吐,以及减少输出数据量。
开启joinblink.miniBatch.join.enabled=true使用 microbatch 时需要保留以下两个 minibatch 配置blink.miniBatch.allowLatencyMs=5000防止OOM,每个批次最多缓存多少条数据blink.miniBatch.size=20000
动态负载使用Dynamic-Rebalance替代Rebalance
blink任务在运行是最忌讳的就是存在计算热点,为保证数据均匀使用Dynamic Rebalance,它可以根据当前各subpartition中堆积的buffer的数量,选择负载较轻的subpartition进行写入,从而实现动态的负载均衡。相比于静态的rebalance策略,在下游各任务计算能力不均衡时,可以使各任务相对负载更加均衡,从而提高整个作业的性能。
开启动态负载task.dynamic.rebalance.enabled=true
自定义输出插件
数据关联后需要将统一请求链路上的数据作为一个数据包通知下游图分析节点,传统的方式的是通过消息服务来投递数据。但是通过消息服务有两个缺点:
1、其吞吐量和rdb这种内存数据库相比比还是较大差距(大概差一个数量级)。
2、在接受端还需要根据traceid做数据关联。
我们通过自定义插件的方式将数据通过异步的方式写入RDB,同时设定数据过期时间。在RDB中以
图聚合计算
cep/graph计算服务节点在接收到metaQ的通知后,综合根据请求的链路数据以及依赖的环境监控数据,会实时生成诊断结果。诊断结果简化为如下形式:

说明本次请求是由于下游jvm的线程池满导致的,但是一次调用并不能说明该服务不可用的根本原因,需要分析整体的错误情况,那就需要对图数据做实时聚合。
聚合设计如下(为了说明基本思路,做了简化处理):
1、首先利用redis的zrank能力为根据服务名或ip信息为每个节点分配一个全局唯一排序序号。
2、为图中的每个节点生成对应图节点编码,编码格式:
-对于头节点:头节点序号|归整时间戳|节点编码
-对于普通节点:|归整时间戳|节点编码
3、由于每个节点在一个时间周期内都有唯一的key,因此可以将节点编码作为key利用redis为每个节点做计数。同时消除了并发读写的问题。
4、利用redis中的set集合可以很方便的叠加图的边。
5、记录根节点,即可通过遍历还原聚合后的图结构。
聚合后的结果大致如下:

这样最终生成了服务不可用的整体原因,并且通过叶子节点的计数可以实现根因的排序。
05收益
系统上线后,整个实时处理数据链路的延迟不超过三秒。闲鱼服务端问题的定位时间从十多分钟甚至更长时间下降到五秒内。大大的提升了问题定位的效率。
06展望
目前的系统可以支持闲鱼每秒千万的数据处理能力。后续自动定位问题的服务可能会推广到阿里内部更多的业务场景,随之而来的是数据量的成倍增加,因此对于效率和成本提出了更好的要求。
未来我们可能做的改进:
1、能够自动的减少或者压缩处理的数据。
2、复杂的模型分析计算也可以在blink中完成,减少io,提升性能。
3、支持多租户的数据隔离。