

导读:etcd 作为 K8s 集群中的存储组件,读写性能方面会受到很多压力,而 etcd 3.4 中的新特性将有效缓解压力,本文将从 etcd 数据读写机制的发展历史着手,深入解读 etcd 3.4 新特性。
背景
etcd 是 Kubernetes 集群中存储元数据,保证分布式一致性的组件,它的性能往往影响着整个集群的响应时间。而在 K8s 的使用中,我们发现除了日常的读写压力外,还存在某些特殊的场景会对 etcd 造成巨大的压力,比如 K8s 下 apiserver 组件重启或是其他组件绕过 apiserver cache 直接查询 etcd 最新数据的情况时,etcd 会收到大量的 expensive read(后文会介绍该概念)请求,这对 etcd 读写会造成巨大的压力。更为严重的是,如果客户端中存在失败重试逻辑或客户端数目较多,会产生大量这样的请求,严重情况可能造成 etcd crash。
etcd 3.4 中增加了一个名为“Fully Concurrent Read”的特性,较大程度上解决了上述的问题。在这篇文章中我们将重点解读它。本篇文章首先回顾 etcd 数据读写机制发展的历史,之后剖析为何这个特性能大幅提升 expensive read 场景下 etcd 的读写性能,最后通过真实实验验证该特性的效果。
etcd 读写发展历史
etcd v3.0 及之前早期版本
etcd 利用 Raft 算法实现了数据强一致性,它保证了读操作的线性一致性。在 raft 算法中,写操作成功仅仅以为着写操作被 commit 到日志上,并不能确保当前全局的状态机已经 apply 了该写日志。而状态机 apply 日志的过程相对于 commit 操作是异步的,因此在 commit 后立即读取状态机可能会读到过期数据。
为了保证线性一致性读,早期的 etcd( etcd v3.0 )对所有的读写请求都会走一遍 Raft 协议来满足强一致性。然而通常在现实使用中,读请求占了 etcd 所有请求中的绝大部分,如果每次读请求都要走一遍 raft 协议落盘,etcd 性能将非常差。
etcd v3.1
因此在 etcd v3.1 版本中优化了读请求( PR#6275),使用的方法满足一个简单的策略: 每次读操作时记录此时集群的 commit index,当状态机的 apply index 大于或者等于 commit index 时即可返回数据。由于此时状态机已经把读请求所要读的 commit index 对应的日志进行了 apply 操作,符合线性一致读的要求,便可返回此时读到的结果。
根据 Raft 论文 6.4 章的内容,etcd 通过 ReadIndex 优化读取的操作核心为以下两个指导原则:
- 让 Leader 处理 ReadIndex 请求,Leader 获取的 commit index 即为状态机的 read index,follower 收到 ReadIndex 请求时需要将请求 forward 给 Leader;
- 保证 Leader 仍然是目前的 Leader,防止因为网络分区原因,Leader 已经不再是当前的 Leader,需要 Leader 广播向 quorum 进行确认。
ReadIndex 同时也允许了集群的每个 member 响应读请求。当 member 利用 ReadIndex 方法确保了当前所读的 key 的操作日志已经被 apply 后,便可返回客户端读取的值。对 etcd ReadIndex 的实现,目前已有相对较多的文章介绍,本文不再赘述。
etcd v3.2
即便 etcd v3.1 中通过 ReadIndex 方法优化了读请求的响应时间,允许每个 member 响应读请求,但当我们把视角继续下移到底层 k/v 存储 boltdb 层,每个独立的 member 在获取 ReadIndex 后的读取任然存在性能问题。
v3.1 中利用 batch 来提高写事务的吞吐量,所有的写请求会按固定周期 commit 到 boltDB。当上层向 底层 boltdb 层发起读写事务时,都会申请一个事务锁(如以下代码片段),该事务锁的粒度较粗,所有的读写都将受限。对于较小的读事务,该锁仅仅降低了事务的吞吐量,而对于相对较大的读事务(后文会有详细解释),则可能阻塞读、写,甚至 member 心跳都有可能出现超时。
// release-3.2: mvcc/kvstore.go
func (s *store) TxnBegin() int64 {
...
s.tx = s.b.BatchTx()
// boltDB 事务锁,所有的读写事务都需要申请该锁
s.tx.Lock()
...
}针对以上提到的性能瓶颈,_ etcd v3.2_ 版本中对 boltdb 层读写进行优化,包含以下两个核心点:
- 实现“N reads 或 1 write”的并行,将上文提到的粗粒度锁细化成一个读写锁,所有读请求间相互并行;
- 利用 buffer 来提高了吞吐量。3.2 中对 readTx,batchTx 分别增加了一个 buffer,所有读事务优先从 buffer 进行读取,未命中再通过事务访问 boltDB。同样,写事务在写 boltDB 的同时,也会向 batchTx 的 buffer 写入数据,而 batch commit 结束时,batchTx 的 buffer 会 writeBack 回 readTx 的 buffer 防止脏读。
// release-3.3: mvcc/kvstore_txn.go
func (s *store) Read() TxnRead {
tx := s.b.ReadTx()
// 获取读事务的 RLock 后进行读操作
tx.RLock()
}
// release-3.3: mvcc/backend/batch_tx.go
func (t *batchTxBuffered) commit(stop bool) {
// 获取读事务的 Lock 以确保 commit 之前所有的读事务都已经被关闭
t.backend.readTx.Lock()
t.unsafeCommit(stop)
t.backend.readTx.Unlock()
}完全并发读
_ etcd v3.2_ 的读写优化解决了大部分读写场景的性能瓶颈,但我们再从客户端的角度出发,回到文章开头我们提到的这种场景,仍然有导致 etcd 读写性能下降的危险。
这里我们先引入一个 expensive read 的概念,在 etcd 中,所有客户端的读请求最后都是转化为 range 的请求向 KV 层进行查询,我们以一次 range 请 求的 key 数量以及 value size 来衡量一次 read 请求的压力大小。综合而言,当 range 请求的 key 数量越多,平均每个 key 对应的 value size 越大,则该 range 请求对 DB 层的压力就越大。 而实际划分 expensive read 和 cheap read 边界视 etcd 集群硬件能力而定。
从客户端角度,在大型集群中的 apiserver 进行一次 pod、node、pvc 等 resource 的全量查询,可以视为一次 expensive read。简要分析下为何 expensive read 会对 boltDB 带来压力。上文提到,为了防止脏读,需要保证每次 commit 时没有读事务进行,因此写事务每次 commit 之前,需要将当前所有读事务进行回滚,所以 commit interval 时间点上需要申请 readTx.lock ,会将该锁从 RLock() 升级成 Lock() ,该读写锁的升级会可能导致所有读操作的阻塞。
如下图( 以下图中,蓝色条为读事务,绿色条为写事务,红色条为事务因锁问题阻塞),t1 时间点会触发 commit,然而有事务未结束,T5 commit 事务因申请锁被阻塞到 t2 时间点才进行。理想状态下大量的写事务会在一个 batch 中结束,这样每次 commit 的写事务仅仅阻塞少部分的读事务(如图中仅仅阻塞了 T6 这个事务)。
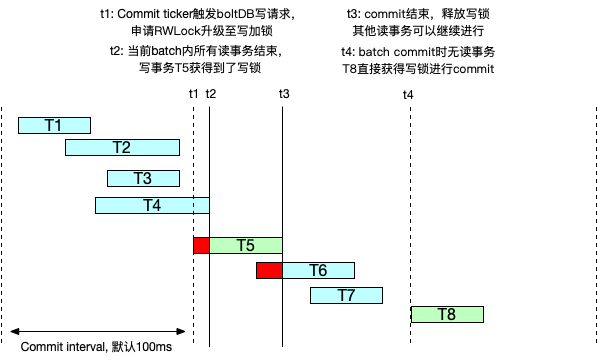
然而此时如果 etcd 中有非常大的读请求,那么该读写锁的升级将被频繁阻塞。如下图,T3 是一个非常长的读事务,跨过了多个 commit batch。每个 commit batch 结束时间点照常触发了 commit 的写事务,然而由于读写锁无法升级,写事务 T4 被推迟,同样 t2 commit 点的写事务 T7 因为申请不到写锁一样也被推迟。
此外,在写事务的 commit 进行了之后,需要将写缓存里的 bucket 信息写入到读缓存中,此时同样需要升级 readTx.lock 到 Lock() 。而上层调用 backend.Read() 获取 readTx 时,需要确保这些 bucket 缓存已经成功写过来了,需要申请读锁 readTx.RLock() ,而如果这期间存在写事务,该锁则无法得到,这些读事务都无法开始。如上的情形下,在第三个 batch(t2-t3)中其他读事务因为得不到读锁都无法进行了。
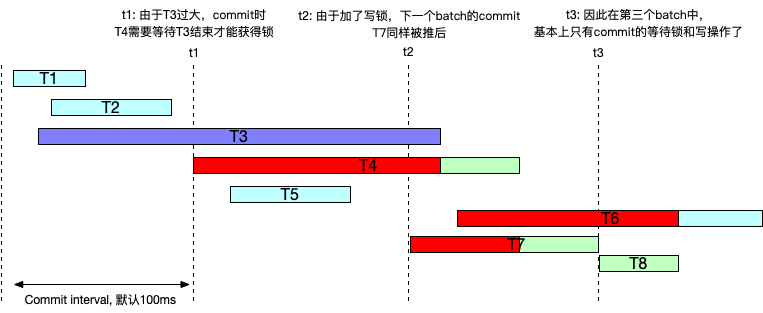
总结而言,因 expensive read 造成读写锁频繁升级,导致写事务的 commit 不断被后移(通常我们将这种问题叫做 head-of-line blocking),从而导致 etcd 读写性能雪崩。
_ etcd v3.4_ 中,增加了一个 “Fully Concurrent Read” 的 feature,核心指导思想是如下两点:
- 将上述读写锁去除(事实上是对该锁再次进行细化),使得所有读和写操作不再因该锁而频繁阻塞;
- 每个 batch interval 不再 reset 读事务
readTxn,而是创建一个新的concurrentReadTxn实例去服务新的读请求,而原来的readTxn在所有事务结束后会被关闭。每个concurrentReadTxn实例拥有一片自己的 buffer 缓存。
除了以上两点变动外,fully concurrent read 在创建新的 ConcurrentReadTx 实例时需要从 ReadTx copy 对应的 buffer map,会存在一定的额外开销,社区也在考虑将这个 copy buffer 的操作 lazy 化,在每个写事务结束后或者每个 batch interval 结束点进行。然而在我们的实验中发现,该 copy 带来的影响并不大。改动的核心代码如以下片段所示:
// release-3.4: mvcc/backend/read_tx.go
type concurrentReadTx struct {
// 每个 concurrentReadTx 实例保留一份 buffer,在创建时从 readTx 的 buffer 中获得一份 copy
buf txReadBuffer
...
}
// release-3.4: mvcc/backend/backend.go
func (b *backend) ConcurrentReadTx() ReadTx {
// 由于需要从 readTx 拷贝 buffer,创建 concurrentReadTx 时需要对常驻的 readTx 上读锁。
b.readTx.RLock()
defer b.readTx.RUnlock()
...
}
// release-3.4: mvcc/backend/read_tx.go
// concurrentReadTx 的 RLock 中不做任何操作,不再阻塞读事务
func (rt *concurrentReadTx) RLock() {}
// release-3.4: mvcc/kvstore_tx.go
func (s *store) Read() TxnRead {
// 调用 Read 接口时,返回 concurrentReadTx 而不是 readTx
tx := s.b.ConcurrentReadTx()
// concurrentReadTx 的 RLock 中不做任何操作
tx.RLock()
}我们再回到上文提到的存在 expensive read 的场景。在 fully concurrent read 的改动之后,读写场景如下图所示。
首先在 mvcc 创建 backend 时会创建一个常驻的 readTx 实例,和之后的写事务 batchTx 存在锁冲突的也仅仅只有这一个实例。之后的所有读请求(例如 T1,T2,T3 等),会创建一个新的 concurrentReadTx 实例进行服务,同时需要从 readTx 拷贝 buffer;当出现 expensive read 事务 T3 时,T4 不再被阻塞并正常执行。同时 T5 需要等待 T4 commit 完成后, readTx 的 buffer 被更新后,再进行 buffer 拷贝,因此阻塞一小段时间。而 t2、t3 commit 时间点的写事务 T7、T8 也因为没有被阻塞而顺利进行。
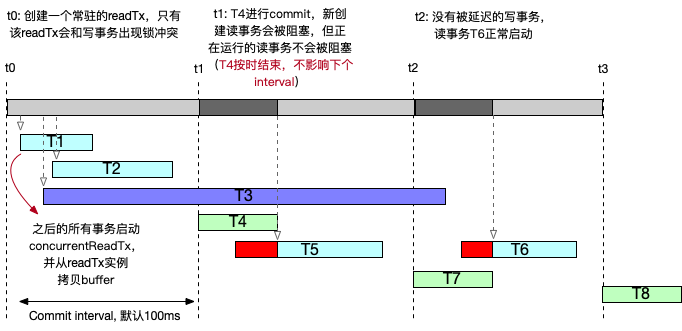
在 fully concurrent read 的读写模式下, concurrentReadTx 仅在创建时可能存在阻塞(因为依赖从 readTx 进行 buffer 拷贝的操作),一旦创建后则不再有阻塞的情况,因此整个流程中读写吞吐量有较大的提升。
读写性能验证实验
针对 etcd v3.4 fully concurrent read 的新 feature,我们在集群中进行了实验对比增加该 feature 前后读写性能的变化。为了排除网络因素干扰,我们做了单节点 etcd 的测试,但是已经足以从结果上看出该 feature 的优势。以下是验证实验的设置:
- 读写设置
- 模拟集群已有存储量,预先写入 100k KVs,每个 KV 由一个128B key和 一个 1~32KB 随机的 values 组成(平均 16KB)
- expensive read:每次 range 20k keys,每秒 1 并发。
- cheap read:每次 range 10 keys,每秒 100 并发。
- write:每次 put 1 key,每秒 20 并发。
- 对照组
- 普通读写场景:cheap read + write;
- 模拟存在较重的读事务的场景:cheap read + expensive read + write。
- 对比版本:
- etcd – ali2019rc2 未加入该优化
- etcd – ali2019rc3 加入该优化
- 防止偶然性:每组 test case 跑 5 次, 取 99 分位(p99)的响应时间的平均值作为该组 test case 的结果。
实验结果如下表所示。对于 普通读写场景,3.4 中的读写性能和 3.3 近似;对于 存在较重的读事务的场景,3.4 中的 fully concurrent read feature 一定程度降低了 expensive read 的响应时间。而在该场景下的 cheap read 和 write,rc2 中因读写锁导致读写速度非常缓慢,而 rc3 中实现的完全并行使得读写响应时间减少到约为原来的 1/7。
| etcd
version | cheap
read + write | | expensive
| read + cheap read + write | ||
|---|---|---|
| p99 read (ms) | p99 write (ms) | |
| read (ms) | p99 cheap read (ms) | p99 write (ms) |
| 3.3 | 14.1 | 15.1 |
| 3.4 (with FCR) | 16.1 | 14.2 |
其他场景下,如在 Kuberentes 5000节点性能测试,也表明在大规模读压力下,P99 写的延时降低 97.4%。
总结
etcd fully concurrent read 的新 feature 优化 expensive 降低了近 85% 的写响应延迟以及近 80% 的读响应延迟,同时提高了 etcd 的读写吞吐量,解决了在读大压力场景下导致的 etcd 性能骤降的问题。调研和实验的过程中感谢宇慕的指导,目前我们已经紧跟社区应用了该新能力,经过长时间测试表现稳定。未来我们也会不断优化 etcd 的性能和稳定性,并将优化以及最佳实践经验反馈回社区。
参考文献
- Etcd Fully Concurrent Read Design Proposal
- Strong consistency models
- Attiya H, Welch J L. Sequential consistency versus linearizability[J]. ACM Transactions on Computer Systems (TOCS), 1994, 12(2): 91-122.
- Ongaro D, Ousterhout J. In search of an understandable consensus algorithm[C]//2014 {USENIX} Annual Technical Conference ({USENIX}{ATC} 14). 2014: 305-319. [raft paper]
本文作者: 陈洁(墨封)
本文为云栖社区原创内容,未经允许不得转载。