
在DolphinDB中,我们可以将历史数据作为“实时数据”按时间顺序导入到流表中,这样同一个脚本就可以用于回测和实时交易。关于DolphinDB中的流式传输,请参考< em>DolphinDB 流媒体教程。
本文介绍了replay和replayDS函数,然后演示了数据重放的过程。
<图>
<源data-testid =“og”尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px) )50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5 dppx)和(最大宽度:700px)80vw,(-webkit-min-device-pixel-ratio:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px ) 100vw, (-webkit-min-device-pixel-ratio: 2) 和 (最大宽度: 700px) 100vw, 700px" srcset="https://miro.medium.com/v2/resize:fit:640/ 1*pUAc_rbZ19W6rts0jkNnQA.jpeg 640w,https://miro.medium.com/v2/resize:fit:720/1*pUAc_rbZ19W6rts0jkNnQA.jpeg 720w,https://miro.medium.com/v2/resize:fit:750/ 1*pUAc_rbZ19W6rts0jkNnQA.jpeg 750w,https://miro.medium.com/v2/resize:fit:786/1*pUAc_rbZ19W6rts0jkNnQA.jpeg 786w,https://miro.medium.com/v2/resize:fit:828/ 1*pUAc_rbZ19W6rts0jkNnQA.jpeg 828w,https://miro.medium.com/v2/resize:fit:1100/1*pUAc_rbZ19W6rts0jkNnQA.jpeg 1100w,https://miro.medium.com/v2/resize:fit:1400/ 1*pUAc_rbZ19W6rts0jkNnQA.jpeg 1400w"/>
1.功能
重播
重播(inputTables、outputTables、[dateColumn]、[timeColumn]、[replayRate]、[absoluteRate=true]、[parallelLevel=1])
函数
replay将指定表或数据源中的数据注入流表中。
'inputTables'是一个表或一个元组。元组的每个元素都是一个未分区的表或由函数replayDS生成的数据源。‘outputTables’是一个表或表的元组,或者是字符串或字符串向量。outputTables的元素数量必须与inputTables的元素数量相同。如果是向量,则为共享流表名称列表,其中保存inputTables对应表的重放数据。如果是元组,则每个元素都是一个共享流表,其中保存了inputTables中对应表的重播数据。outputTables中每个表的架构必须与inputTables中相应表的架构相同。‘dateColumn’和‘timeColumn’是表示 inputTables 中日期列和时间列的字符串。如果两者均未指定,则表的第一列将选择为‘dateColumn’。如果有‘dateColumn’,它一定是分区列之一。如果仅指定‘timeColumn’,则它必须是分区列之一。如果有关日期和时间的信息来自同一列(例如,DATETIME、TIMESTAMP),请对‘dateColumn’和‘timeColumn’使用同一列。如果未指定'timeColumn',则按'timeColumn'或'dateColumn'中的最小时间单位确定数据的批量重播。例如,如果‘timeColumn’中的最小时间单位是秒,那么同一秒内的所有数据都会在同一个批次中重播;如果不指定‘timeColumn’,则同一批重播同一天的所有数据。‘replayRate’是一个非负整数,指示每秒重播的行数。如果不指定,则表示以最大速度重放数据。‘replayRate’是一个整数。‘absoluteRate’是一个布尔值。默认值为 true。
关于‘replayRate’和‘absoluteRate’:
- 如果
'replayRate' 为正整数且absoluteRate=true,则以'replayRate' 的速度重播< /code> 每秒行数。 - 如果
'replayRate'是正整数且absoluteRate=false,则按'replayRate'重播数据原始速度的倍。例如,如果'dateColumn'或'timeColumn'的最大值和最小值之间的差异为n秒,则需要n/replayRate 秒完成重播。 - 如果“
replayRate”未指定或为负数,则以最大速度重播。‘parallelLevel’是一个正整数。当数据源中各个分区的大小相对于内存大小太大时,我们需要使用函数replayDS将各个分区进一步划分为更小的数据源。'parallelLevel'表示同时从这些较小数据源将数据加载到内存中的线程数量。默认值为 1。如果'inputTables'是一个表或表的元组,则有效的'parallelLevel'始终为 1。
replayDS
replayDS(sqlObj, [dateColumn], [timeColumn], [timeRepartitionSchema])
函数 replayDS 生成一组数据源,用作函数 replay 的输入。它基于 'timeRepartitionSchema' 将 SQL 查询拆分为多个子查询,每个 'dateColumn' 分区内都有 'timeColumn'。
'sqlObj'是一个表或元代码,其中包含 SQL 语句(例如),指示要处理的数据被重播。 select from 的表对象必须使用DATE类型列作为分区列之一。‘dateColumn’和‘timeColumn’是表示日期列和时间列的字符串。如果两者均未指定,则表的第一列将选择为‘dateColumn’。如果有‘dateColumn’,它一定是分区列之一。如果仅指定‘timeColumn’,则它必须是分区列之一。如果有关日期和时间的信息来自同一列(例如,DATETIME、TIMESTAMP),请对‘dateColumn’和‘timeColumn’使用同一列。函数replayDS和相应的函数replay必须使用同一组'dateColumn'和'timeColumn'。< /里>‘timeRepartitionSchema’是 TIME 或 NANOTIME 类型向量。'timeRepartitionSchema'在每个'dateColumn'分区内的'timeColumn'维度上划分多个数据源。例如,如果 timeRepartitionSchema=[t1, t2, t3],则一天内有 4 个数据源:[00:00:00.000,t1)、[t1,t2)、[t2,t3) 和 [t3,23] :59:59.999)。
重播单个内存表
重播(inputTable,outputTable,`日期,`时间,10)
使用数据源重播单个表
要重放包含大量行的单个表,我们可以将函数 replayDS 与函数 replay 一起使用。函数replayDS在每个“dateColumn”分区内的“timeColumn”维度上划分多个数据源。函数replay的参数“parallelLevel”指定同时从这些较小数据源将数据加载到内存中的线程数。在此示例中,“parallelLevel”设置为 2。
inputDS = replayDS(
使用数据源同时重播多个表
要同时重播多个表,请将这些表名称的元组分配给函数 replay 的参数 'inputTables' 并指定输出表。每个输出表对应一个输入表,并且应该与相应的输入表具有相同的模式。所有输入表都应具有相同的 'dateColumn' 和 'timeColumn'。
ds1 = replayDS(
取消重播
如果使用 submitJob 调用函数 replay,我们可以使用 getRecentJobs 获取 jobId,然后取消使用命令cancelJob重播。
getRecentJobs()
取消作业(jobid)
如果直接调用函数replay,我们可以在另一个GUI会话中使用getConsoleJobs来获取jobId,然后取消重播并使用命令cancelConsoleJob。
getConsoleJobs()
cancelConsoleJob(jobId)
2.如何使用重播数据
重播的数据是流数据。我们可以通过以下3种方式订阅并处理重播数据:
- 订阅 DolphinDB。在DolphinDB中编写用户定义的函数来处理流数据。
- 订阅 DolphinDB。要对流数据进行实时计算,请使用DolphinDB内置的流聚合器,例如时间序列聚合器、横截面聚合器和异常检测引擎。它们非常易于使用并且具有出色的性能。在第 3.2 节中,我们使用横截面聚合器来计算 ETF 的内在价值。
- 通过 DolphinDB 的流式 API 与第三方客户端合作。
3.示例
重播 1 级股票报价以计算 ETF 内在价值。
在此示例中,我们重播 2007 年 8 月 17 日美国股市的 1 级股票报价,并使用内置横截面聚合器计算 ETF 的内在价值在 DolphinDB 中。以下是输入表“quotes”的架构和数据预览。
quotes = database("dfs://TAQ").loadTable("quotes");
quote.schema().colDefs;
<图>
<源尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px)50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5dppx)和(最大宽度:700px)80vw,(-webkit-最小设备像素比:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px)100vw,(-webkit-最小设备像素比:2) 和(最大宽度:700px)100vw,266px" srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*GblNEY_cBMymiJU6CwHlyA .png 640w,https://miro.medium.com/v2/resize:fit:720/format:webp/1*GblNEY_cBMymiJU6CwHlyA.png 720w,https://miro.medium.com/v2/resize:fit:750 /格式:webp/1*GblNEY_cBMymiJU6CwHlyA.png 750w,https://miro.medium.com/v2/resize:fit:786/format:webp/1*GblNEY_cBMymiJU6CwHlyA.png 786w,https://miro.medium.com /v2/resize:fit:828/format:webp/1*GblNEY_cBMymiJU6CwHlyA.png 828w,https://miro.medium.com/v2/resize:fit:1100/format:webp/1*GblNEY_cBMymiJU6CwHlyA.png 1100w,https ://miro.medium.com/v2/resize:fit:532/format:webp/1*GblNEY_cBMymiJU6CwHlyA.png 532w" type="image/webp"/>
<源data-testid =“og”尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px) )50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5 dppx)和(最大宽度:700px)80vw,(-webkit-min-device-pixel-ratio:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px ) 100vw, (-webkit-min-device-pixel-ratio: 2) 和 (最大宽度: 700px) 100vw, 266px" srcset="https://miro.medium.com/v2/resize:fit:640/ 1*GblNEY_cBMymiJU6CwHlyA.png 640w,https://miro.medium.com/v2/resize:fit:720/1*GblNEY_cBMymiJU6CwHlyA.png 720w,https://miro.medium.com/v2/resize:fit:750/ 1*GblNEY_cBMymiJU6CwHlyA.png 750w,https://miro.medium.com/v2/resize:fit:786/1*GblNEY_cBMymiJU6CwHlyA.png 786w,https://miro.medium.com/v2/resize:fit:828/ 1*GblNEY_cBMymiJU6CwHlyA.png 828w,https://miro.medium.com/v2/resize:fit:1100/1*GblNEY_cBMymiJU6CwHlyA.png 1100w,https://miro.medium.com/v2/resize:fit:532/ 1*GblNEY_cBMymiJU6CwHlyA.png 532w"/>
从 date=2007.08.17 的报价中选择前 10 个 *
<图>
<源data-testid =“og”尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px) )50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5 dppx)和(最大宽度:700px)80vw,(-webkit-min-device-pixel-ratio:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px ) 100vw, (-webkit-min-device-pixel-ratio: 2) 和 (最大宽度: 700px) 100vw, 700px" srcset="https://miro.medium.com/v2/resize:fit:640/ 1*OBmGFkt8Z2jdNEgyWpP8zg.png 640w,https://miro.medium.com/v2/resize:fit:720/1*OBmGFkt8Z2jdNEgyWpP8zg.png 720w,https://miro.medium.com/v2/resize:fit:750/ 1*OBmGFkt8Z2jdNEgyWpP8zg.png 750w,https://miro.medium.com/v2/resize:fit:786/1*OBmGFkt8Z2jdNEgyWpP8zg.png 786w,https://miro.medium.com/v2/resize:fit:828/ 1*OBmGFkt8Z2jdNEgyWpP8zg.png 828w,https://miro.medium.com/v2/resize:fit:1100/1*OBmGFkt8Z2jdNEgyWpP8zg.png 1100w,https://miro.medium.com/v2/resize:fit:1400/ 1*OBmGFkt8Z2jdNEgyWpP8zg.png 1400w"/>
1.要重放大量数据,如果我们先将所有数据加载到内存中,则可能会出现内存不足的问题。我们可以首先使用函数replayDS并指定参数'timeRepartitionSchema',根据'time'列将数据分为60份。
trs = cutPoints(09:30:00.000..16:00:00.000, 60)
rds = replayDS(
2.定义输出流表‘outQuotes’。
sch = 选择 name,typeString 作为quotes.schema().colDefs 中的类型
分享streamTable(100:0, sch.name, sch.type)作为outQuotes
3.定义 ETF 成分权重的字典和函数 etfVal 来计算 ETF 内在价值。为简单起见,我们使用仅包含 6 只成分股的 ETF。
defg etfVal(权重,sym,价格) {
返回 wsum(价格, 权重[sym])
}
权重 = dict(STRING, DOUBLE)
权重[`AAPL] = 0.1
权重[`IBM] = 0.1
权重[`MSFT] = 0.1
权重[`NTES] = 0.1
权重[`AMZN] = 0.1
权重[`GOOG] = 0.5
4.定义一个流聚合器来订阅输出流表'outQuotes'。我们为订阅指定了一个过滤条件,即只有股票代码为 AAPL、IBM、MSFT、NTES、AMZN 或 GOOG 的数据才会发布到聚合器。这显着减少了不必要的网络开销和数据传输。
setStreamTableFilterColumn(outQuotes, `符号) 输出表 = 表(1:0, `time`etf, [TIMESTAMP,DOUBLE]) tradesCrossAggregator=createCrossSectionalAggregator("etfvalue", <[etfVal{weights}(symbol, ofr)]>, 报价, outputTable, `symbol, `perBatch) subscribeTable(tableName="outQuotes", actionName="tradesCrossAggregator", offset=-1, handler=append!{tradesCrossAggregator}, msgAsTable=true, filter=`AAPL`IBM`MSFT`NTES`AMZN`GOOG)
5.开始以每秒 100,000 行的指定速度重播数据。流媒体聚合器对回放的数据进行实时计算。
submitJob("replay_quotes", "replay_quotes_stream", replay, [rds], [`outQuotes], `date, `time, 100000, true, 4)
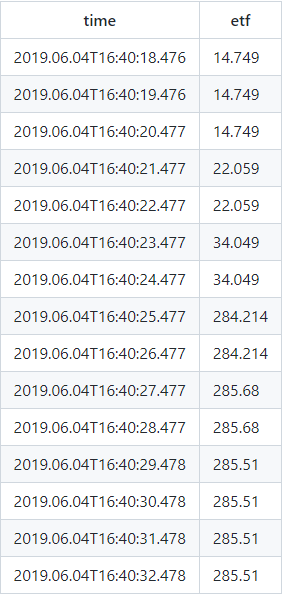
6.检查ETF内在价值
从outputTable中选择前15个*<图>
<源尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px)50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5dppx)和(最大宽度:700px)80vw,(-webkit-最小设备像素比:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px)100vw,(-webkit-最小设备像素比:2)和(最大宽度:700px)100vw,284px“srcset =”https://miro.medium.com/v2/resize:fit:640/format:webp/1*XjCXub -G6q2PHz965oWq4A.png 640w,https://miro.medium.com/v2/resize:fit:720/format:webp/1*XjCXub-G6q2PHz965oWq4A.png 720w,https://miro.medium.com/v2/resize :fit:750 /格式:webp / 1 * XjCXub-G6q2PHz965oWq4A.png 750w,https://miro.medium.com/v2/resize:fit:786/格式:webp/1 *XjCXub-G6q2PHz965oWq4A.png 786w,https ://miro.medium.com/v2/resize:fit:828/format:webp/1*XjCXub-G6q2PHz965oWq4A.png 828w,https://miro.medium.com/v2/resize:fit:1100/format: webp/1*XjCXub-G6q2PHz965oWq4A.png 1100w,https://miro.medium.com/v2/resize:fit:568/format:webp/1*XjCXub-G6q2PHz965oWq4A.png 568w" type="image/webp"/ >
<源data-testid =“og”尺寸=“(最小分辨率:4dppx)和(最大宽度:700px)50vw,(-webkit-min-device-pixel-ratio:4)和(最大宽度:700px) )50vw,(最小分辨率:3dppx)和(最大宽度:700px)67vw,(-webkit-min-device-pixel-ratio:3)和(最大宽度:700px)65vw,(最小分辨率:2.5 dppx)和(最大宽度:700px)80vw,(-webkit-min-device-pixel-ratio:2.5)和(最大宽度:700px)80vw,(最小分辨率:2dppx)和(最大宽度:700px ) 100vw, (-webkit-min-device-pixel-ratio: 2) 和 (最大宽度: 700px) 100vw, 284px" srcset="https://miro.medium.com/v2/resize:fit:640/ 1*XjCXub-G6q2PHz965oWq4A.png 640w,https://miro.medium.com/v2/resize:fit:720/1*XjCXub-G6q2PHz965oWq4A.png 720w,https://miro.medium.com/v2/resize:适合:750/1*XjCXub-G6q2PHz965oWq4A.png 750w,https://miro.medium.com/v2/resize:适合:786/1*XjCXub-G6q2PHz965oWq4A.png 786w,https://miro.medium.com/ v2/resize:fit:828/1*XjCXub-G6q2PHz965oWq4A.png 828w,https://miro.medium.com/v2/resize:fit:1100/1*XjCXub-G6q2PHz965oWq4A.png 1100w,https://miro。 medium.com/v2/resize:fit:568/1*XjCXub-G6q2PHZ965oWq4A.png 568w"/>
4.性能测试
我们在具有以下配置的服务器上测试了 DolphinDB 中的数据重放:
- 服务器:DELL PowerEdge R730xd
- CPU:Intel Xeon(R) CPU E5–2650 v4(24 核、48 线程、2.20GHz)
- RAM:512 GB(32GB × 16,2666 MHz)
- 硬盘:17T HDD(1.7T × 10,读取速度 222 MB/s,写入速度 210 MB/s)
- 网络:10 Gb 以太网
DolphinDB 脚本:
sch = 选择 name,typeString 作为quotes.schema().colDefs 中的类型
trs = cutPoints(09:30:00.000..16:00:00.001,60)
rds = replayDS(<从引号中选择 *,其中 date=2007.08.17>, `日期, `时间, trs);
共享streamTable(100:0, sch.name, sch.type) as outQuotes1
jobid = SubmitJob("replay_quotes","replay_quotes_stream", replay, [rds], [`outQuotes1], `日期, `时间, , ,4)
以最大速度重放时(未指定参数'replayRate')输出表未订阅,重放336,305,414行只需要100秒左右数据的。