
和许多拥有与计算机编程无关的学位的程序员一样,我从2019年开始一直在努力自学编码,希望能在这项工作中取得成功。作为一名自学成才的开发人员,我对所学的东西更加实用和面向目标。这就是为什么我特别喜欢网络刮擦,它不仅有各种各样的用例,如产品监控,社交媒体监控,内容聚合等,而且很容易拿起。
Web 刮擦的基本思想是从网站中提取信息片段并将其导出为易于阅读的格式。如果您是数据驱动型人员,您将在 Web 抓取中找到出色的价值。幸运的是,有免费的 Web 刮削工具可用于自动捕获 Web 数据,而无需编码。
网络上下文比我们想象的要复杂。话虽如此,我们需要投入时间和精力来维护刮擦工作,更不用说从多个网站大规模刮擦。另一方面,刮工具使我们免于编写代码和无休止的维护工作。
为了让您了解蛇刮和网站刮工具的利弊,我将引导您完成 Python 的整个工作。然后,我将比较该过程与一个网页刮削工具。
我们开始吧!
使用 Python 进行 Web 擦除
项目:
-
网站: Yelp.com
-
刮取内容:业务标题、评级、审核计数、电话号码、价格范围、地址、邻里
您将在这里找到完整的编码: https://github.com/whateversky/yelp
前提
-
Pycharm – 用于快速检查和修复编码错误
一般刮擦过程如下所示:
-
首先,我们创建一个蜘蛛来定义我们如何执行和提取 Yelp 的数据。换句话说,我们发送 GET 请求,然后设置刮刀抓取网站的规则。
-
然后,我们分析网页内容,并返回字典与提取的数据。话虽如此,我们告诉蜘蛛它必须返回 Item 对象或请求对象。
-
最后,导出从蜘蛛返回的提取数据。
我只专注于蜘蛛和解析器。但是,我们当然需要了解数据提取前的 Web 结构。在编码时,您还会发现自己不断检查网页,以访问 div 和类选择”检查”,并在”网络”下找到”XHR”选项卡。
您将找到相应的列表信息,包括商店名称、电话号码、位置和评级。随着我们扩展”PaginationInfo”,它向我们显示每个页面上有30个列表,并且有6932个列表。因此,在本视频结束时,我们应该能够得到这么多的结果。现在,让我们前往有趣的部分:
蜘蛛
首先,打开Pycharm并设置一个新项目。然后设置 python 文件,并将其命名为”yelp_spider”
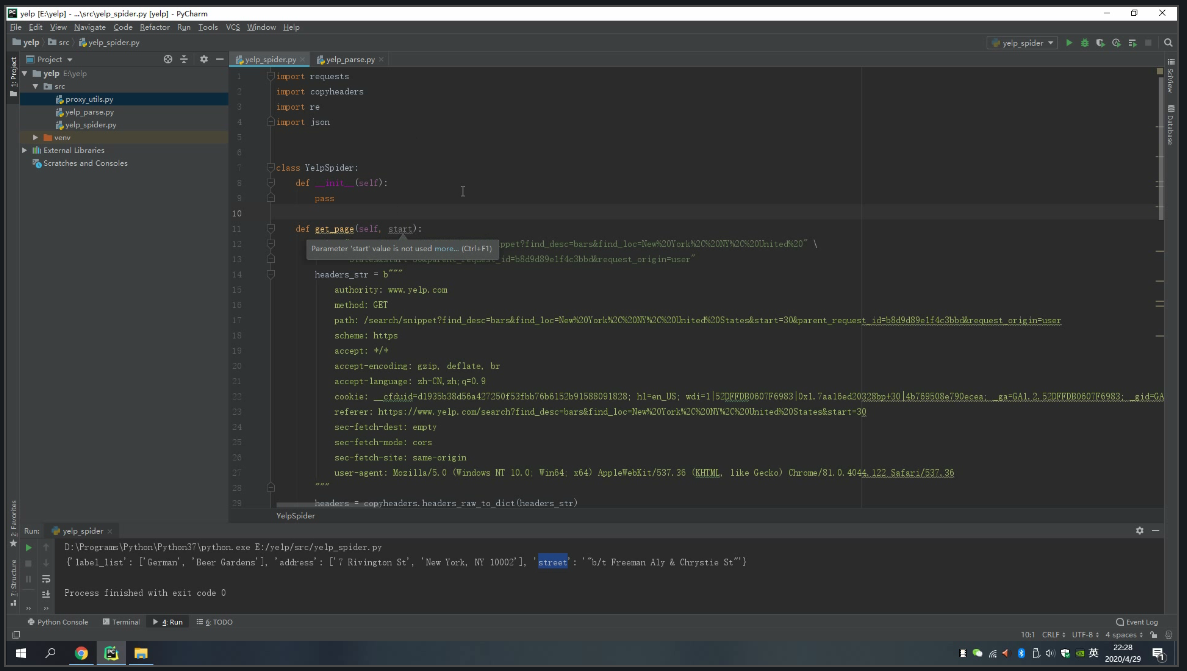
获取页面:
我们创建一个get_page方法。这将传递包含所有列表 Web URL 的查询参数,然后返回页面 JSON。请注意,我还添加一个用户代理字符串来欺骗 Web 服务器以绕过任何刮刀检测。我们只需复制和粘贴请求标头即可。这是没有必要的,但你会发现它很有用,在大多数情况下,如果你倾向于刮一个网站反复。
我添加 .format 参数来格式化 URL,以便返回终结点遵循的模式,在这种情况下,从”纽约市的 Bar” 搜索结果中的所有列表页
get_page(自我、start_number):
url="https://www.yelp.com/search/snippet?find_desc=bars&find_loc=New%20York%2C%20NY%2C%20United%20States&start={}&parent_request_id=dfcaae5fb7b44685&request_origin=user” \ .format(start_number)
.格式(start_number)
获取详细信息:
我们刚刚成功地收集到列表页的 URL,我们现在可以告诉刮刀使用get_detail方法访问每个详细信息页。
详细信息页面 URL 由一个域名和指示业务的路径组成。

由于我们已经收集了列表 URL,我们可以简单地定义 URL 模式,该模式包括附加https://www.yelp.com的路径。这样,它将返回详细信息页 URL 的列表
xxxxxxx
defget_detail(自我url_suffix): url="https://www.yelp.com/" = 路径
接下来,我们仍然需要添加一个标头,以使刮刀看起来更人性化。这类似于我们进入前敲门的常见礼仪。
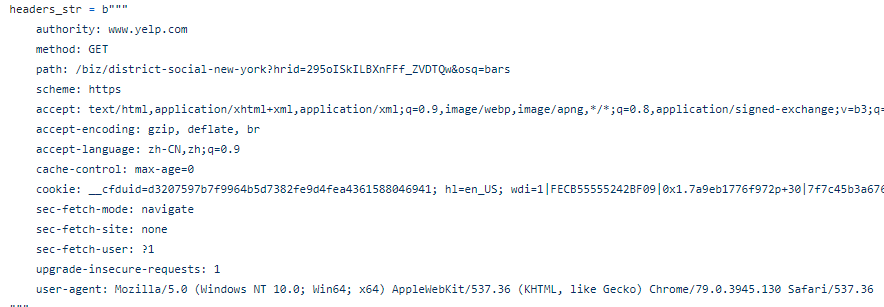
然后,我创建了一个 FOR 循环与 IF 语句相结合,以找到我们将要获取的标记。在这种情况下,包含业务名称、评级、审核、电话等的标记。
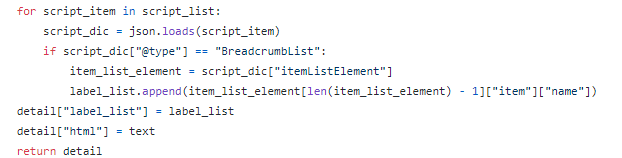
与将返回 JSON 格式的列表页面不同,详细信息页面通常以 HTML 格式响应我们。因此,我剥离了标点符号和额外的空格,使它们看起来干净整洁,而解析。
解析
当我们逐个访问这些页面时,我们可以指示我们的蜘蛛通过分析页面来获取详细信息。
首先,在同一文件夹下创建第二个名为”yelp_parse.py”的文件。从导入开始,执行 YelpSpider”start_number”是偏移值,在这种情况下为”0″。当我们完成对当前页面的爬网后,它会增加 30 个数字。这样,逻辑将如下所示:
- 获取前 30 个列表
- 帕金吉特
- 获取 31-60 个列表
- 帕金吉特
- 获取 61-90 个列表…
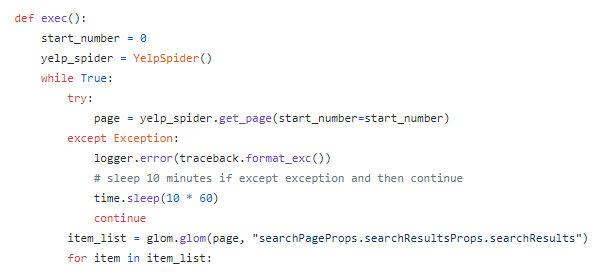
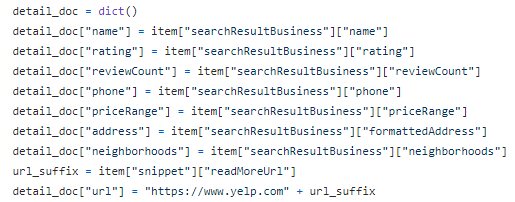
最后但并非最不重要的一点,我创建一个字典,将键和值与相应的数据属性(包括业务名称、评级、电话、价格范围、地址、邻域等)进行配对。
使用 Web 刮削工具进行刮擦:
使用 python,我们直接与 Web 服务器、门户和源代码进行交互。理想情况下,此方法将更有效,但涉及编程。由于网站用途广泛,我们需要不断编辑刮刀并适应变化。硒和木偶一家也是如此,他们是近亲,但与Python相比,它们具有局限性,用于大规模提取。
另一方面,网络刮削工具更友好。让我们以八角形为例:
Octoparse 的最新版本 OP 8.1 应用了训练算法,该算法在加载网页时检测数据属性。如果你曾经经历过iPhone的面部解锁,应用人工智能,”检测”是不是一个奇怪的术语给你。
同样,Octoparse 会自动分解网页并识别各种数据属性,例如业务名称、联系人信息、评论、位置、评级等。
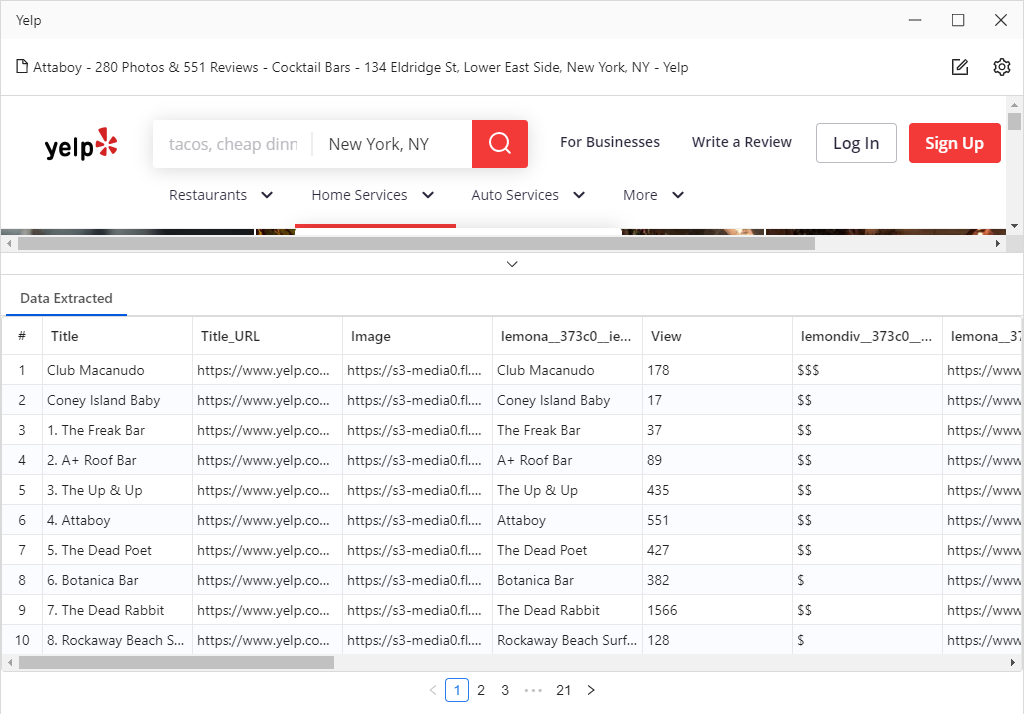
以 yelp 为例。加载网页后,它会自动分析 Web 元素并自动读取数据属性。一旦检测过程完成,我们可以看到所有数据,八度从预览部分为我们捕获,漂亮和整洁!然后,您会注意到工作流已自动创建。工作流类似于刮削路线图,刮刀将遵循该方向来捕获数据。
我们在 python 部分中创建了相同的事物,但它们没有用清晰的语句和图形(如 Octoparse)进行可视化。编程更合乎逻辑和抽象,如果没有在这一领域的坚实基础,很难概念化。
但是,这还不一部分,我们希望从详细的页面获取信息。很容易就容易了。只需按照提示面板中的指南操作,然后找到”在后面的页面上收集 Web 数据”。
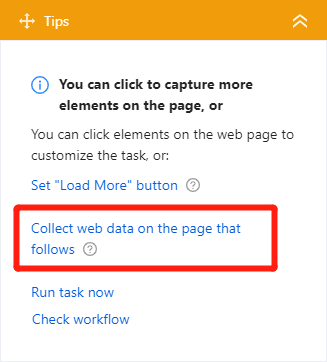
然后选择title_url,这可以带我们到细节页面。
确认此步骤后,将自动向工作流添加新步骤。然后浏览器将显示一个详细信息页,我们可以单击页面中的任何数据属性。例如,当我们单击业务标题”ARDYN”时,提示指南将响应一组操作,供我们选择。只需单击”提取所选元素的文本”命令,即可处理其余部分并将操作添加到工作流中。同样,重复上述步骤,以获得”评级”、”审核计数”、”电话号码”、”价格范围”、”地址”。
一旦我们设置了所有的东西,我们可以执行刮刀确认。
最终想法:使用 Python 与 Web 刮削工具进行刮擦
它们都能获得相似的结果,但性能不同。对于 python,在实施之前肯定有许多基础需要进行。然而,刮刀工具在许多层面上更加友好。
如果你是编程世界的新人,想要探索网络刮擦的力量,尽管如此,可以说,一个网页刮削工具是一个很好的起点。当你踏上编码的大门时,有更广泛的选择和组合,我相信这将激发新的想法,使事情更轻松,更容易。
