
直到最近, 大多数组织一直在努力实现信息传递的圣杯, 即一次传递的语义。尽管这是自 apache kafkas 0.11 以来的一个开箱即用的功能, 但人们在获取此功能方面仍然进展缓慢。让我们花点时间来理解一次的语义学。有什么大不了的, 卡夫卡是如何解决这个问题的?
阿帕奇卡提供以下送货保证。让我们了解这到底意味着什么:
-
最多一次交付:它保证特定消息可以传递一次, 也可以根本不传递。消息可能会丢失, 但消息永远不会多次传递。
-
至少在传递之后: 它保证将始终传递特定的消息。它可以多次传递, 但永远不会丢失任何消息。
-
准确一次交付: 它保证所有消息将始终只传递一次。准确一次并不意味着不会出现失败或重试。这些都是不可避免的。重要的是重试成功。换句话说, 无论是否成功地处理了一次, 结果都应该是一样的。
为什么最重要的一次是重要的
有一些用例 (如金融应用程序、物联网应用程序和其他流应用程序) 不能承受任何低于一次的费用。从银行账户存款或取款时, 您不能承担重复或丢失消息的费用。它需要精确的一次作为最终结果。
为什么很难实现
假设您有一个小型的卡夫卡流应用程序, 很少输入进料分区, 也没有输出分区。应用程序的目的和期望是从输入分区接收数据, 处理数据, 并将数据写入输出分区。这就是一个人想要实现一次准确的保证的地方。由于网络故障、系统崩溃和其他错误, 在此过程中会引入重复项。
问题 1: 重复或多写入
请参见图1a。正在处理消息m1并将其写入主题 b. 原因可能是, 比如说, 网络延迟, 这最终会被定时。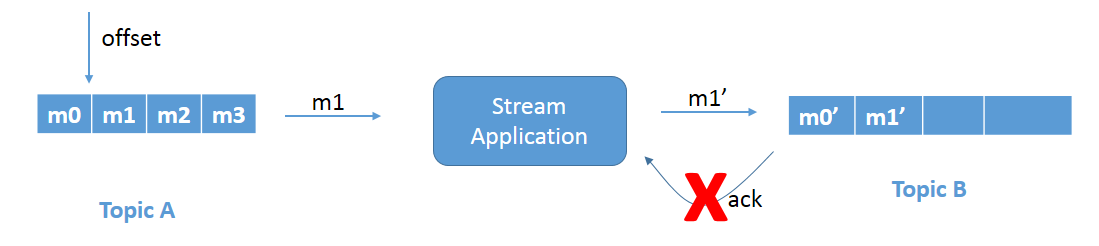
图 1a: 重复写入问题。
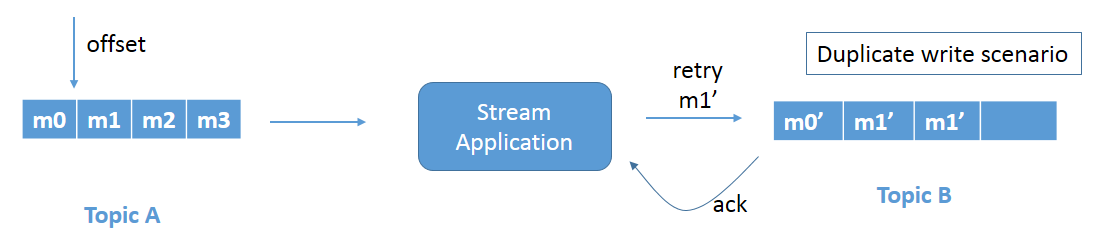
图 1b: 重试导致的重复写入问题。
由于应用程序不知道消息已成功写入, 因为它从未收到确认, 因此它将重试并导致重复写入。请参见图1b。消息m1 将被重写到主题 b。这是一个重复的写入问题, 需要修复。
问题 2: 重读输入记录
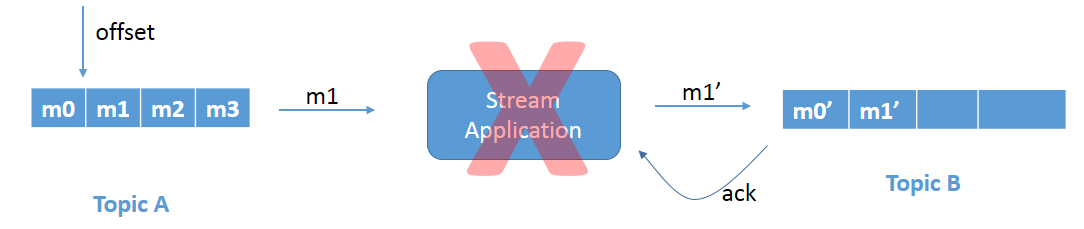
图 2a: 由于应用程序崩溃而导致的重新读取问题。

阿帕奇·卡夫卡如何帮助
apache 卡卡通过使用以下方法的精确一次性语义解决上述问题。
等价制作人
通过防止消息被多次处理, 可以实现生成器方面的低效。这是通过只保留一次消息来实现的。启用等价性后, 每个卡夫卡消息都会得到两件事: 生成器 id (pid) 和序列号 (seq)。pid 分配对用户是完全透明的, 并且客户端永远不会公开。
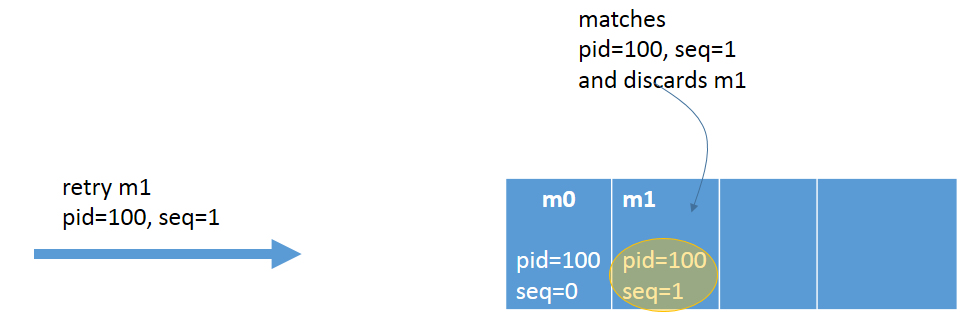
图 3: 等价生产者
producerProps.put("enable.idempotence", "true");
producerProps.put("transactional.id", "100");在代理失败或客户端失败的情况下, 在重试消息发送期间, 该主题将只接受具有新的唯一序列号和生成器 id 的消息。代理会自动删除此生成器发送的任何消息, 以确保一致性。不需要进行其他代码更改。
跨分区的事务
为了确保每条消息都得到精确的一次处理, 可以使用事务。事务有一个全或无的方法。它们确保在选取消息后, 可以将消息转换并以原子方式写入多个主题分区, 同时使用消息的偏移量。
原子事务的代码段
producer.initTransactions();
try {
producer.beginTxn();
// ... read from input topic
// ... transform
producer.send(rec1); // topic A
producer.send(rec2); // topic B
producer.send(rec3); // topic C
producer.sendOffsetsToTxn(offsetsToCommit, “group-id”);
producer.commitTransaction();
} catch ( Exception e ) {
producer.abortTransaction();
}apache 卡夫卡·v0.11 引入了两个组件-事务协调器和事务日志, 它们维护原子写入的状态。
下图详细介绍了支持跨不同分区的原子事务的高级事件流:
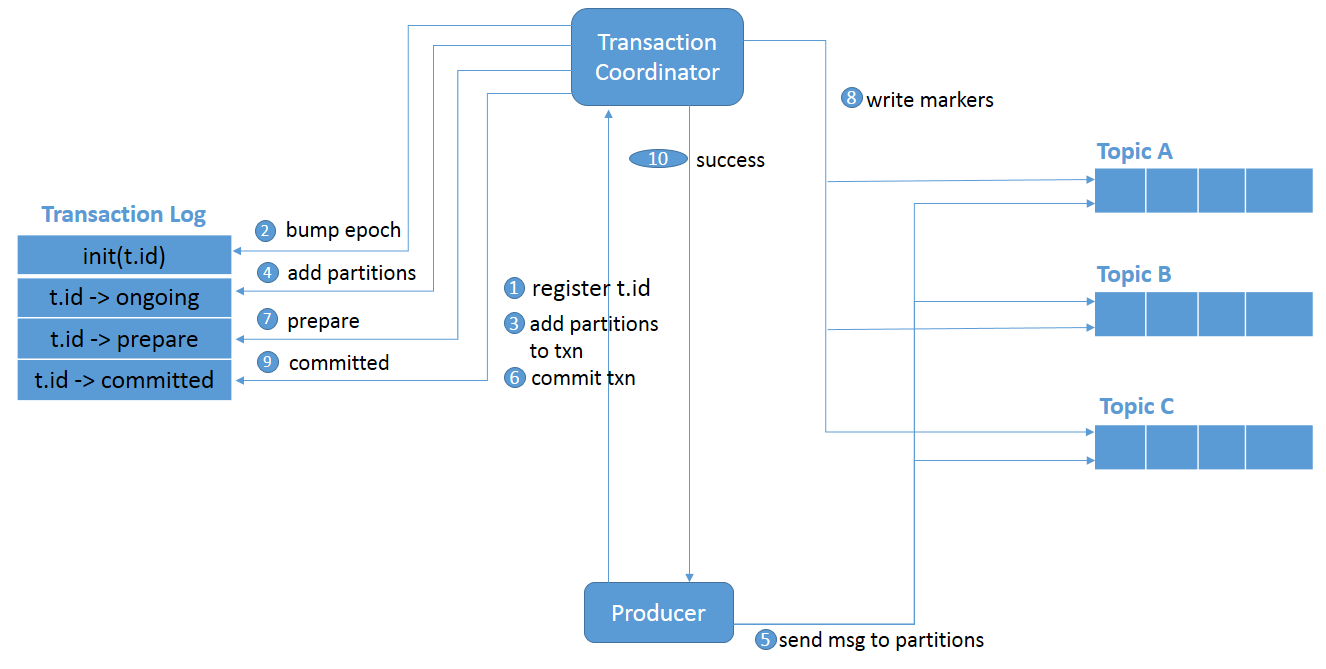
图 4: 跨分区的事务。
initTransactions()向协调员登记.transactional.id- 协调器启动了 pid 的时代, 因此该 pid 的前一个实例被视为僵尸并被围起来。未来没有从这些僵尸中接受任何写作。
- 当生成器要将数据发送到分区时, 生成器将向协调器添加一个分区。
- 事务协调器在内存中保留它所拥有的每个事务的状态, 并将该状态写入事务日志 (在本例中为分区信息)。
- 生成器将数据发送到实际分区。
- 生成器启动提交事务, 因此, 协调器开始两阶段提交协议。
- 这是第一阶段开始的地方, 协调员更新事务日志以 “准备 _ 提交”
交易消费者
如果使用者是事务性的, 则应使用隔离级别. read_committed这可确保它只读取提交的数据。
的默认值 isolation.level 为 read_uncommitted 。
这只是对 apache kafka 中事务如何工作的高级视图。如果你有兴趣进行更深入的潜水, 我建议你探索博士。
结论
在这篇文章中, 我们讨论了各种传递保证语义, 例如最少一次、最多一次和一次。我们还讨论了为什么精确一次是重要的, 实现精确的一次性的问题, 以及卡夫卡如何通过简单的配置和最少的编码来支持它开箱即用。