
influxDB数据库以其优秀的时序数据存储和查询能力,在处理和分析类似资源监控等时序数据方面得到了广泛的应用。而influxDB自带的各种特殊函数如求平均值、标准差、随机取数据,使数据分析变得十分方便。本文作者基于360内部对产生的大量时序数据的存储为背景需求,设计了性能优异的influxDB集群,下来就跟随作者一探究竟吧。
1
基础概念
TSDB与传统DB比较
- 传统数据库多用于记录数据的当前值。
- 时序数据库记录基于时间的一系列数据。
TSDB应用场景
由时序产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。具体场景:各类设备的监控数据,医学中的血糖、血压、心率的监控数据,金融业中交易、成交数据等。
为什么选择influxdb
- 开发者社区活跃,使用者众多,开源时间较长。性能经过检验;
- 类SQL的插入、查询语言,不会增加太大的学习成本;
- 原生HTTP接口支持各类语言调用;
- 仅仅作为存储方案,可插拔。
influxdb之TSM存储引擎概述
- TSM 存储引擎主要由几个部分组成:
- cache。在内存中是一个简单的 map 结构默认配置文件中为1g。
- wal。记录内容和cache一样,目的是为了持久化cache数据,influxdb启动时会加载wal的数据到内存。
- tsm file。用于数据存储。
- compactor。主要进行两类操作:
- cache->snapshot->tsm;
- 合并小tsm成为大的 tsm。
Shard——TSM存储引擎之上的概念
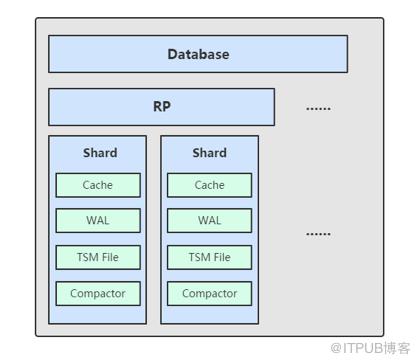
- 按时间戳所在不同范围创建不同Shard;
- 根据时间可以快速定位要查询的数据资源,加快查询的过程;
- 让根据时间的批量删除操作变得非常简单且高效。
2
项目由来
- influxdb社区版默认并未提供集群解决方案。
- 官方开源的influxdb-relay仅仅支持双写功能,并未支持负载均衡能力。
- 饿了么开源的influx-proxy集群方案组件众多,安装部署、后期维护成本高、复杂度大。
- 360公司内部需求:提供十万台主机的两百个监控项数据的实时出图、访问,基于这些监控项的告警以及故障预测。
- 基于上述需求,于是有了influxDB-HA项目。
3
程序架构
官方开源influxdb-relay方案
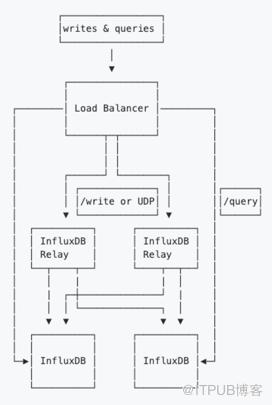
未解决的问题:
- 采用双写仅仅解决了数据备份的问题,并未解决influxdb读写性能的问题;
- 只是写入了数据,查询还是需要去读influxdb。增加了配置文件的复杂度不易维护;
- 并未对写入失败的数据做任何重试机制的处理。
饿了么influxdb高可用解决方案
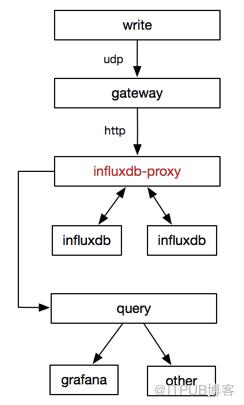
优势:
- influx-proxy是饿了么在influxdb-relay满足不了其性能要求、配置维护要求痛定思痛后重构的产物;
- influxdb机器支持动态扩缩;
- 增加了强大的请求失败后的重试机制。
劣势:
- 架构中使用的组件较多,增加了使用者的学习成本,且不易于后期的维护;
- 请求失败重试本身是双刃剑,试想机器性能达到极限,重试无形中又增加了机器的负载;
- 与自身场景需求不相符,我们内部只是做监控数据的持久化存储,应该是最简单的接入和与influxdb最小的架构改造。
360内部influxDB-HA解决方案
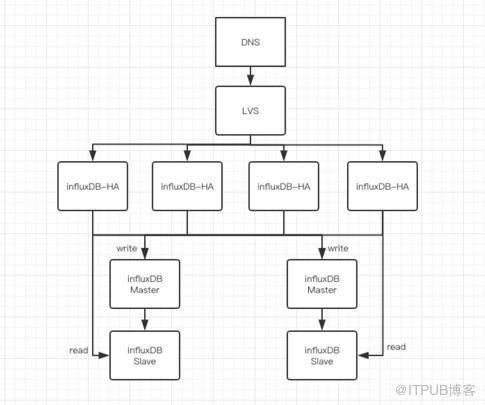
优势:
- 以measurement为最小拆分单元,从而保证以时序查询influxdb的高效性。
- 支持业务层动态的拆库、拆表操作。
4
性能比较
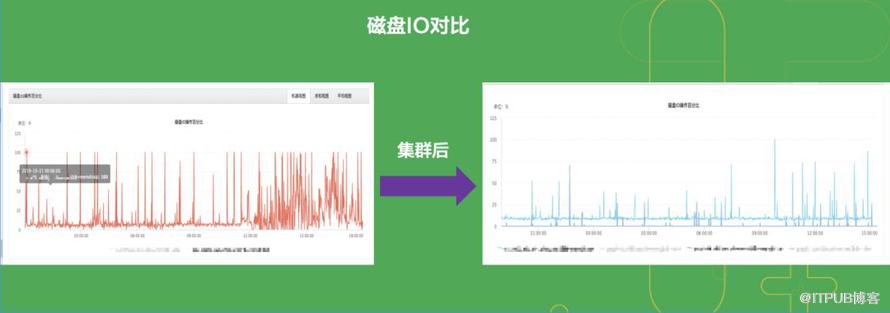
与单机influxdb 磁盘IO对比。
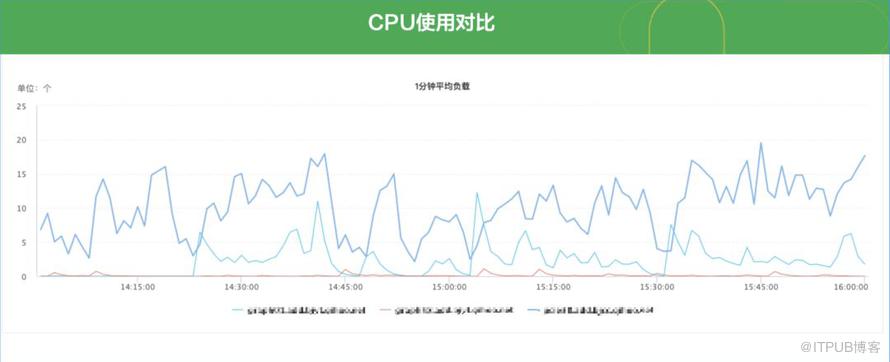
与单机influxdb CPU使用对比。
5
业务方接入influxDB-HA说明
influxDB-HA管理influxdb实例配置。

Grafana接入influxDB-HA说明。
三方程序接入influxDB-HA写入数据说明。
- 完全兼容influxdb原生的/write接口方式写入,且支持原生查询接口的所有参数;
- 如果您说您以前习惯了使用influxdb的SDK方式写入,那也恭喜您。influxDB-HA支持任何语言的influxdb SDK接入。
6
后期迭代计划
一个优秀的项目需要经历无数的版本迭代和优化,而对于开发者而言,能兼容各类需求、适应各类场景是沉淀、提升技术的不二法门。鉴于此,我们应该不断完善influxDB-HA以支持360内部各类使用场景。接来下,仅提出未来可见的优化点:
- 接入kafka、RabbitMQ做写入请求之前的缓冲,降低数据丢失的风险;
- influxDB-HA配置文件的热加载(目前已经通过golang的fsnotify库实现,将来更大规模的influxDB-HA集群应该通过etcd等外部的配置统一管理来实现);
- 对接业务方分表,以支持更大数据规模场景下的解决方案,measurement始终作为influxDB-HA集群中可拆分的最小单元,避免不同measurement的合并排序问题。
7
influxdb使用注意事项
经过一段时间(近一个多月)的实践和对influxdb性能的综合观察,总结出以下结论供我们大家一起探讨:
1、continuous queries/select:
笔者看见很多对于influxdb的不满来自于对其性能的诟病。然而有目共睹的是其写入性能是极其优秀的,那究竟查询性能如何呢?
实践总结:对于超过10万样本数据的查询操作而言,我们通过索引(即influxdb中的tag)查询将能够节省机器性能,大大降低查询时间。查询操作往往耗死机器的根本原因是:OOM(Out Of Memory)
那么在配置CQ时,应该:
- 尽可能使用tag;
- 应该拿写好的CQ充分模拟线上环境的测试,证明性能没问题后再上线。
2、retention policy:
配置数据的留存策略好处是数据持久化,但数据量较大时劣势也非常明显,会占用很大的CPU,造成读写数据异常。所以配置RP时我们必须注意:
- 尽量在读写并发量较小的时刻去操作;
- 可以在influxdb slave库中反复设置RP实践出最佳方式再上线。