
本文介绍了如何在不使用任何额外库的情况下用 C++20 实现 Raft Server 共识模块。叙述分为三个主要部分:
- Raft 算法全面概述
- Raft Server 开发详细说明
- 基于自定义协程的网络库的描述
该实现利用了 C++20 的强大功能,特别是协程,提供了一种有效且现代的方法来构建 分布式系统。本次阐述不仅展示了 C++20 协程在复杂编程环境中的实际应用和优势,还深入探讨了从头开始构建共识模块(例如 Raft Server)时遇到的挑战和解决方案。 Raft 服务器和网络库存储库,miniraft-cpp 和 coroio,可供进一步探索和实际应用。
简介
在深入研究 Raft 算法的复杂性之前,让我们考虑一个现实世界的示例。我们的目标是开发一个网络键值存储(K/V)系统。在C++中,这可以通过使用unordered_map轻松完成。然而,在实际应用中,需要容错存储系统 增加复杂性。看似简单的方法可能需要部署三台(或更多)机器,每台机器托管该服务的副本。用户的期望可能是管理数据复制和一致性。但是,此方法可能会导致不可预测的行为。例如,可以使用特定密钥更新数据,然后稍后检索旧版本。
用户真正想要的是一个分布式系统,可能分布在多台机器上,运行像单主机系统一样流畅。为了满足这个要求,通常会在K/V存储(或任何类似的服务,以下简称“状态机”)之前放置一个共识模块。此配置确保所有用户与状态机的交互都通过共识模块专门路由,而不是直接访问。考虑到这一点,现在让我们以 Raft 算法为例来看看如何实现这样一个共识模块。
Raft 概述
在 Raft 算法中,有奇数个参与者,称为peer。每个对等点都保留自己的记录日志。有一名同行领导者,其他人是追随者。用户将所有请求(读取和写入)发送给领导者。当收到更改状态机的写入请求时,领导者首先将其记录下来,然后将其转发给追随者,追随者也将其记录下来。一旦大多数节点成功响应,领导者就会认为该条目已提交,将其应用到状态机,并通知用户其成功。
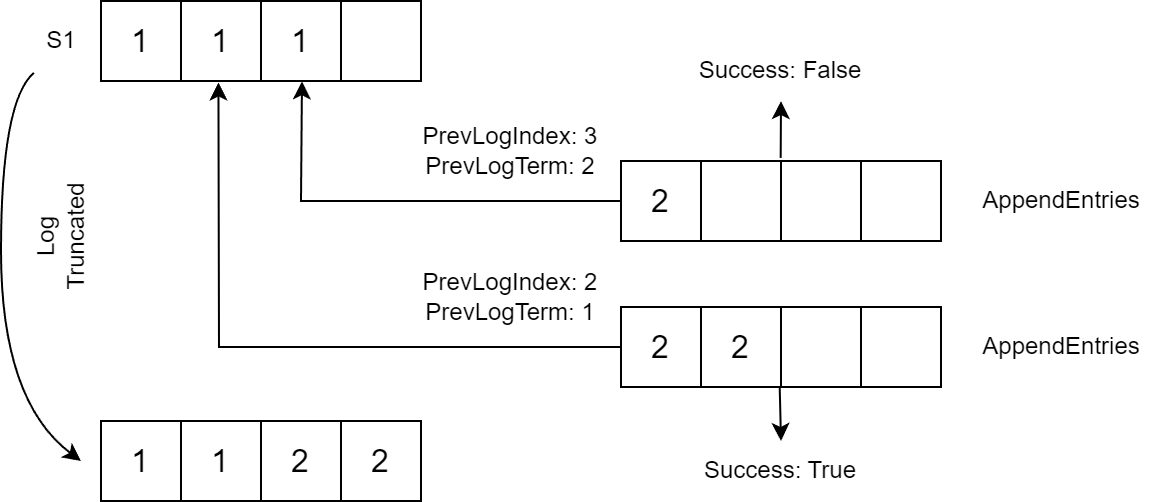
Term 是 Raft 中的一个关键概念,而且它只会不断增长。当系统发生变化(例如领导层发生变化)时,任期就会发生变化。 Raft 中的日志具有特定的结构,每个条目由Term 和Payload 组成。该术语指的是撰写初始条目的领导者。 有效负载表示要对状态机进行的更改。 Raft 保证具有相同索引和术语的两个条目是相同的。 Raft 日志不是仅追加的,并且可能会被截断。例如,在下面的场景中,领导者 S1 在崩溃之前复制了两个条目。 S2率先开始复制条目,S1的日志与S2和S3的日志不同。因此,S1 日志中的最后一个条目将被删除并替换为新条目。

Raft RPC API
让我们检查一下 Raft RPC。值得注意的是,Raft API 非常简单,只有两次调用。我们将首先查看领导者选举 API。需要注意的是,Raft 确保每个任期只能有一个领导者。也可能存在没有领导人的任期,例如选举失败。为了确保只发生一次选举,节点将其投票保存在名为 VotedFor 的持久变量中。选举 RPC 称为 RequestVote,具有三个参数:Term、LastLogIndex 和 LastLogTerm.响应包含 Term 和 VoteGranted。值得注意的是,每个请求都包含 Term,而在 Raft 中,节点只有在 Term 兼容的情况下才能有效地进行通信。
当节点发起选举时,它会向其他节点发送 RequestVote 请求并收集他们的选票。如果大多数响应都是积极的,则同伴将晋升为领导者角色。
现在让我们看看 AppendEntries 请求。它接受 Term、PrevLogIndex、PrevLogTerm 和 Entries 等参数,响应包含 Term 和成功。如果请求中的 Entries 字段为空,则它充当 Heartbeat。
当收到 AppendEntries 请求时,关注者会检查 PrevLogIndex 中的 Term。如果它与 PrevLogTerm 匹配,则关注者会将 Entries 添加到其以 PrevLogIndex + 1 开头的日志中(PrevLogIndex 之后的条目为如果存在则删除):

如果条款不匹配,关注者将返回 Success=false。在这种情况下,领导者会重试发送请求,将 PrevLogIndex 降低 1。
当对等方收到 RequestVote 请求时,它将其 LastTerm 和 LastLogIndex 对与最新的日志条目进行比较。如果该对小于或等于请求者的,则对等方返回 VoteGranted=true。
Raft 中的状态转换
Raft 的状态转换如下所示。每个对等点都以Follower 状态开始。如果 Follower 在设定的超时时间内没有收到 AppendEntries,它将延长其 Term 并移至 Candidate 状态,触发选举。如果赢得选举,节点可以从 Candidate 状态移动到 Leader 状态,或者如果收到 Follower 状态,则返回到 Follower 状态code>AppendEntries 请求。如果 Candidate 未在以下时间内转变为 Follower 或 Leader,它也可以恢复为 Candidate超时时间。如果处于任何状态的对等方收到 Term 大于其当前状态的 RPC 请求,它就会转移到 Follower 状态。
提交
现在让我们考虑一个例子来演示 Raft 并不像看起来那么简单。我从迭戈·翁加罗(Diego Ongaro)的论文中举了这个例子。 S1 是第 2 期的领导者,它在崩溃之前复制了两个条目。此后,S5 在Term 3 中领先,添加了一个条目,然后崩溃了。接下来,S2 在第 4 学期接管了领导权,复制了第 2 学期的条目,为第 4 学期添加了自己的条目,然后崩溃了。这会导致两种可能的结果:S5 收回领导权并截断第 2 期的条目,或者 S1 重新获得领导权并提交第 2 期的条目。仅当新领导者的后续条目涵盖第 2 项后,第 2 项才会安全提交。

此示例演示了 Raft 算法如何在动态且通常不可预测的环境中运行。事件序列(包括多个领导者和崩溃)展示了在分布式系统中维持一致状态的复杂性。这种复杂性并不是立即显现出来,但在涉及领导者变更和系统故障的情况下变得很重要。该示例强调了采用稳健且深思熟虑的方法来处理此类复杂性的重要性,这正是 Raft 寻求解决的问题。
其他材料
为了进一步学习和更深入地了解 Raft,我推荐以下材料: 原始 Raft 论文,非常适合实现。 Diego Ongaro 的博士论文提供了更多内容深入的见解。 Maxim Babenko 的讲座更深入详细信息。
Raft 实现
现在让我们继续讨论 Raft 服务器实现,在我看来,它极大地受益于 C++20 协程。在我的实现中,持久状态存储在内存中。然而,在现实场景中,它应该保存到磁盘。稍后我将详细讨论 MessageHolder。它的功能与 shared_ptr 类似,但专门为处理 Raft 消息而设计,确保有效管理和处理这些通信。
在不稳定状态中,我用 L 表示“领导者”或 F 表示“追随者”来标记条目澄清它们的用途。 CommitIndex 表示最后提交的日志条目。相反,LastApplied 是应用于状态机的最新日志条目,并且它始终小于或等于CommitIndex。 NextIndex 很重要,因为它标识要发送到对等方的下一个日志条目。同样,MatchIndex 跟踪发现匹配的最后一个日志条目。 Votes 部分包含为我投票的同伴的 ID。超时是管理的一个重要方面:HeartbeatDue 和 RpcDue 管理领导者超时,而 ElectionDue 处理跟随者超时。
Raft API
我的 Raft 算法实现有两个类。第一个是INode,它表示对等点。该类包含两个方法:Send(将传出消息存储在内部缓冲区中)和 Drain(处理实际的消息调度)。 Raft是第二类,它管理当前peer的状态。它还包括两个方法:Process,用于处理传入连接;ProcessTimeout,必须定期调用它来管理超时,例如领导者选举超时。这些类的用户应根据需要使用 Process、ProcessTimeout 和 Drain 方法。 INode 的 Send 方法在 Raft 类内部调用,确保消息处理和状态管理在 Raft 框架内无缝集成。
Raft 消息
现在让我们看看如何发送和读取 Raft 消息。我没有使用序列化库,而是以 TLV 格式读取和发送原始结构。消息标题如下所示:
struct TMessage {
uint32_t 类型;
uint32_t Len;
字符值[0];
};为了更加方便,我引入了二级标头:
struct TMessageEx: public TMessage {
uint32_t源=0;
uint32_t 目标=0;
uint64_t 项= 0;
};这包括每条消息中的发送者和接收者的 ID。除了LogEntry 之外,所有消息都继承自TMessageEx。 LogEntry 和 AppendEntries 实现如下:
为了方便消息处理,我使用了一个名为 MessageHolder 的类,让人想起 shared_ptr:
此类包含一个包含消息本身的 char 数组。它还可能包括一个Payload(仅用于AppendEntry),以及将基本类型消息安全地转换为特定消息的方法( Maybe 方法)和不安全的转换(Cast 方法)。以下是使用 MessageHolder 的典型示例:
以及 Candidate 状态处理程序中的真实示例:
这种设计方法提高了 Raft 实现中消息处理的效率和灵活性。
Raft 服务器
让我们讨论一下 Raft 服务器的实现。 Raft 服务器将为网络交互设置协程。首先,我们将看看处理消息读取和写入的协程。本文稍后将讨论用于这些协程的原语以及对网络库的分析。写入协程负责将消息写入套接字,而读取协程稍微复杂一些。要读取,它必须首先检索 Type 和 Len 变量,然后分配一个 Len 字节数组,最后读取其余部分信息。这种结构有利于Raft服务器内网络通信的高效管理。
模板<类型名称 TSocket>
TValueTask<空>
TMessageWriter::Write(TMessageHolder 消息) {
co_await TByteWriter(Socket).Write(message.Mes, message->Len);
自动有效负载 = std::move(message.Payload);
for (uint32_t i = 0; i < message.PayloadSize; ++i) {
co_await Write(std::move(payload[i]));
}
共同返回;
}
模板<类型名称 TSocket>
TValueTask> TMessageReader::Read() {
decltype(TMessage::Type) 类型; decltype(TMessage::Len) len;
auto s = co_await Socket.ReadSome(&type, sizeof(type));
if (s != sizeof(type)) { /* 抛出 */ }
s = co_await Socket.ReadSome(&len, sizeof(len));
if (s != sizeof(len)) { /* 抛出 */}
自动消息 = NewHoldedMessage(type, len);
co_await TByteReader(Socket).Read(mes->Value, len - sizeof(TMessage));
auto MaybeAppendEntries = mes.Maybe();
如果(也许AppendEntries){
自动appendEntries = MaybeAppendEntries.Cast();
自动nentries =appendEntries->Nentries; mes.InitPayload(nentries);
for (uint32_t i = 0; i < nentries; i++) mes.Payload[i] = co_await Read();
}
co_return me;
} 要启动 Raft 服务器,请创建 RaftServer 类的实例并调用 Serve 方法。 Serve 方法启动两个协程。 Idle 协程负责定期处理超时,而 InboundServe 管理传入连接。
类 TRaftServer {
民众:
无效服务(){
闲置的();
入站服务();
}
私人的:
TVoidTask InboundServe();
TVoidTask InboundConnection(TSocket 套接字);
TVoidTask 空闲();
}传入连接通过accept 调用接收。接下来,启动 InboundConnection 协程,它读取传入消息并将其转发到 Raft 实例进行处理。此配置可确保 Raft 服务器能够有效处理内部超时和外部通信。
TVoidTask InboundServe() {
而(真){
自动客户端 = co_await Socket.Accept();
InboundConnection(std::move(client));
}
共同返回;
}
TVoidTask InboundConnection(TSocket套接字){
而(真){
auto mes = co_await TMessageReader(client->Sock()).Read();
Raft->Process(std::chrono::steady_clock::now(), std::move(mes),
客户);
Raft->ProcessTimeout(std::chrono::steady_clock::now());
漏极节点();
}
共同返回;
}Idle 协程的工作原理如下:它在每个睡眠秒调用 ProcessTimeout 方法。值得注意的是,这个协程使用了异步睡眠。这种设计使Raft服务器能够高效管理时间敏感的操作,而不会阻塞其他进程,从而提高服务器的整体响应能力和性能。
while (true) {
Raft->ProcessTimeout(std::chrono::steady_clock::now());
漏极节点();
自动 t1 = std::chrono::steady_clock::now();
如果(t1 > t0 + dt){
调试打印();
t0 = t1;
}
co_await Poller.Sleep(t1 + sleep);
}协程是为了发送传出消息而创建的,并且设计得很简单。它循环地重复将所有累积的消息发送到套接字。如果发生错误,它会启动另一个协程来负责连接(通过 connect 函数)。这种结构确保传出消息能够顺利、高效地处理,同时通过错误处理和连接管理保持稳健性。
尝试 {
while (!Messages.empty()) {
自动发送 = std::move(消息); Messages.clear();
for (auto&& m : 发送) {
co_await TMessageWriter(Socket).Write(std::move(m));
}
}
} catch (const std::Exception& ex) {
连接();
}
co_return;实现 Raft 服务器后,这些示例展示了协程如何极大地简化开发。虽然我没有研究过 Raft 的实现(相信我,它比 Raft Server 复杂得多),但整体算法不仅简单,而且设计紧凑。
接下来,我们将看一些 Raft 服务器示例。接下来,我将描述我专门为 Raft 服务器从头开始创建的网络库。该库对于在 Raft 框架内实现高效的网络通信至关重要。
以下是启动具有三个节点的 Raft 集群的示例。每个实例接收自己的 ID 作为参数,以及其他实例的地址和 ID。在这种情况下,客户只与领导者进行沟通。它发送随机字符串,同时保留一定数量的传输中消息并等待它们的承诺。此配置描述了多节点 Raft 环境中客户端和领导者之间的交互,演示了算法对分布式数据的处理和共识。
$ ./server --id 1 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1: 8003:3
...
候选人,期限:2,索引:0,CommitIndex:0,
...
领导者,任期:3,索引:1080175,提交索引:1080175,延迟:2:0 3:0
匹配索引: 2:1080175 3:1080175 下一个索引: 2:1080176 3:1080176
....
$ ./server --id 2 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
$ ./server --id 3 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
关注者,期限:3,索引:1080175,CommitIndex:1080175,
...
$ dd if=/dev/urandom | 64 位 |光伏-l | ./client --node 127.0.0.1:8001:1 >log1
198k 0:00:03 [159.2k/s] [ <=>我测量了 3 节点和 5 节点集群配置的提交延迟。正如预期的那样,5 节点设置的延迟较高:
- 3 个节点
- 50%(中位数):292,872 ns
- 80%:407,561 ns
- 90%:569,164 ns
- 99 百分位数:40,279,001 纳秒
-
5 个节点
- 50%(中位数):425,194 ns
- 80%:672,541 ns
- 90 百分位:1,027,669 纳秒
- 99 百分位数:38,578,749 纳秒
I/O 库
现在让我们看看我从头开始创建并在 Raft 服务器实现中使用的 I/O 库。我从下面的示例开始,取自 cppreference.com,这是一个 echo 服务器的实现:
任务<> tcp_echo_server() {
字符数据[1024];
而(真){
std::size_t n = co_await socket.async_read_some(buffer(data));
co_await async_write(socket, buffer(data, n));
}
}我的库需要一个事件循环、一个套接字原语以及诸如 read_some/write_some(在我的库中名为 ReadSome/WriteSome)之类的方法,以及更高级别的包装器,例如 async_write/async_read (在我的库中名为 TByteReader/TByteWriter)。
要实现套接字的 ReadSome 方法,我必须创建一个 Awaitable,如下所示:
auto ReadSome(char* buf, size_t size) {
结构体 TAwaitable {
bool wait_ready() { 返回 false; /* 始终挂起 */ }
无效等待_挂起(std :: coroutine_handle <> h){
轮询器->AddRead(fd, h);
}
int wait_resume() {
返回读取(fd,b,s);
}
TSelect* 轮询器; int fd;字符* b; size_t s;
};
返回 TAwaitable{Poller_,Fd_,buf,size};
}当调用 co_await 时,协程会挂起,因为 await_ready 返回 false。在 await_suspend 中,我们捕获 coroutine_handle 并将其与套接字句柄一起传递给轮询器。当套接字准备好时,轮询器调用 Coroutine_handle 来重新启动协程。恢复时,调用 await_resume,执行读取并将读取的字节数返回给协程。 WriteSome、Accept 和 Connect 方法以类似的方式实现。
轮询器设置如下:
结构 TEvent {
int Fd; int 类型; // 读 = 1,写 = 2;
std::coroutine_handle<> 句柄;
};
类 TSelect {
无效民意调查(){
for (const auto& ch : 事件) { /* FD_SET(ReadFds); FD_SET(WriteFds);*/ }
pselect(Size, ReadFds, WriteFds, nullptr, ts, nullptr);
for (int k = 0; k < 大小; ++k) {
if (FD_ISSET(k, WriteFds)) {
事件[k].Handle.resume();
}
// ...
}
}
std::vector 事件;
// ...
}; 我保留了一个数组(套接字描述符、协程句柄),用于初始化轮询器后端的结构(在本例中为 select)。当与就绪套接字对应的协程唤醒时,将调用 Resume。
这在主函数中应用如下:
TSimpleTask 任务(TSelect& poller) {
TSocket 套接字(0,轮询器);
字符缓冲区[1024];
而(真){
auto readSize = co_await socket.ReadSome(buffer, sizeof(buffer));
}
}
int main() {
T选择轮询器;
任务(轮询器);
while (true) { poller.Poll(); }
}我们启动一个协程(或多个协程),该协程在 co_await 上进入睡眠模式,然后将控制权传递给调用轮询器机制的无限循环。如果轮询器内的套接字准备就绪,则会触发并执行相应的协程,直到下一个 co_await。
要读取和写入 Raft 消息,我需要在 ReadSome/WriteSome 上创建高级包装器,类似于:
TValueTask Read() {
特雷斯; size_t 大小 = sizeof(T);
char* p = reinterpret_cast(&res);
而(大小!= 0){
自动 readSize = co_await Socket.ReadSome(p, 大小);
p += 读取大小;
大小-=读取大小;
}
co_return 资源;
}
// 用法
T t = co_await Read(); 为了实现这些,我需要创建一个也充当 Awaitable 的协程。协程由一对组成:coroutine_handle 和 promise。 Coroutine_handle 用于从外部管理协程,而 Promise 用于内部管理。 coroutine_handle 可以包含 Awaitable 方法,该方法允许使用 co_await 等待协程的结果。 promise 可用于存储 co_return 返回的结果并唤醒调用协程。
在 coroutine_handle 中的 await_suspend 方法中,我们存储调用协程的 coroutine_handle。它的值将保存在promise中:
模板<类型名称 T>
结构 TValueTask : std::coroutine_handle<> {
bool wait_ready() { return !!this->promise().Value; } }
void wait_suspend(std::coroutine_handle<> 调用者) {
this->promise().Caller = 调用者;
}
T wait_resume() { return *this->promise().Value; } }
使用 Promise_type = TValuePromise;
}; 在 promise 本身内,return_value 方法将存储返回值。调用协程通过可等待项唤醒,该可等待项在 final_suspend 中返回。这是因为编译器在 co_return 之后,在 final_suspend 上调用 co_await。
模板<类型名称 T>
结构 TValuePromise {
void return_value(const T& t) { 值 = t; }
std::suspend_never 初始挂起() { 返回 {}; }
// 在这里恢复调用者
TFinalSuspendContinuation Final_Suspend() noexcept;
std::可选 值;
std::coroutine_handle<> 调用者 = std::noop_coroutine();
}; 在await_suspend中,可以返回调用协程,并且会自动唤醒。需要注意的是,被调用的协程现在将处于睡眠状态,并且它的 coroutine_handle 必须使用 destroy 来销毁,以避免内存泄漏。例如,这可以在 TValueTask 的析构函数中完成。
模板<类型名称 T>
结构 TFinalSuspendContinuation {
bool wait_ready() noexcept { 返回 false; }
std::coroutine_handle<>等待_挂起(
std::coroutine_handle> h) noexcept
{
return h.promise().Caller;
}
无效await_resume()noexcept {}
}; 完成库描述后,我将 libevent 基准移植到其中以确保其性能。该基准测试生成一系列 N 个 Unix 管道,每个管道都链接到下一个管道。然后,它向链中发起 100 个写入操作,该操作一直持续到总共有 1000 个写入调用。下图将我的库 (coroio) 与 libevent 的各种后端的基准测试运行时间描述为 N 的函数。此测试表明我的库的性能与 libevent 类似,证实了它在管理 I/O 操作方面的效率和有效性。

结论
最后,本文描述了使用 C++20 协程实现 Raft 服务器,强调了这种现代 C++ 功能所提供的便利性和效率。从头开始编写的自定义 I/O 库对此实现至关重要,因为它可以有效地处理异步 I/O 操作。该库的性能已根据 libevent 基准进行了验证,证明了其能力。
对于那些有兴趣了解更多信息或使用这些工具的人,可以在 coroio 上找到 I/O 库,在 miniraft-cpp 上找到 Raft 库(链接在文章开头)。这两个存储库都详细介绍了如何使用 C++20 协程来构建健壮、高性能的分布式系统。