
Milvus 旨在实现大规模矢量的高效相似性搜索和分析。独立的 Milvus 实例可以轻松地处理十亿比例矢量矢量的矢量搜索。但是,对于 100 亿、1000 亿甚至更大的数据集,需要 Milvus 群集。该群集可用作上层应用程序的独立实例,并可满足大规模数据的低延迟、高并发性业务需求。Milvus 群集可以重新发送请求、将读取与写入分开、水平缩放和动态扩展,从而提供可以无限制扩展的 Milvus 实例。Mishards 是 Milvus 的分布式解决方案。
本文将简要介绍 Mishards 体系结构的组件。更详细的信息将在即将发表的文章中介绍。
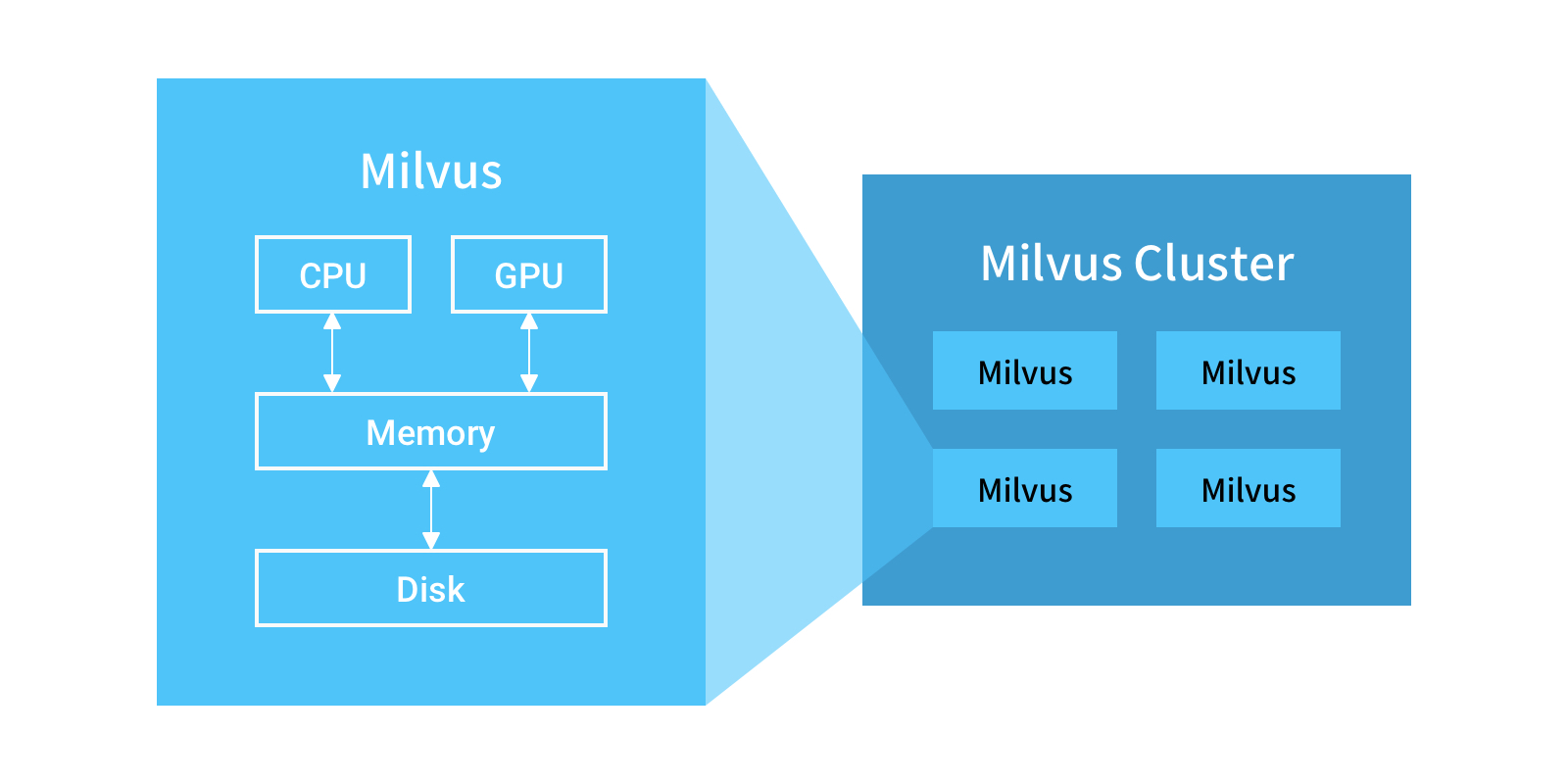
分布式体系结构概述
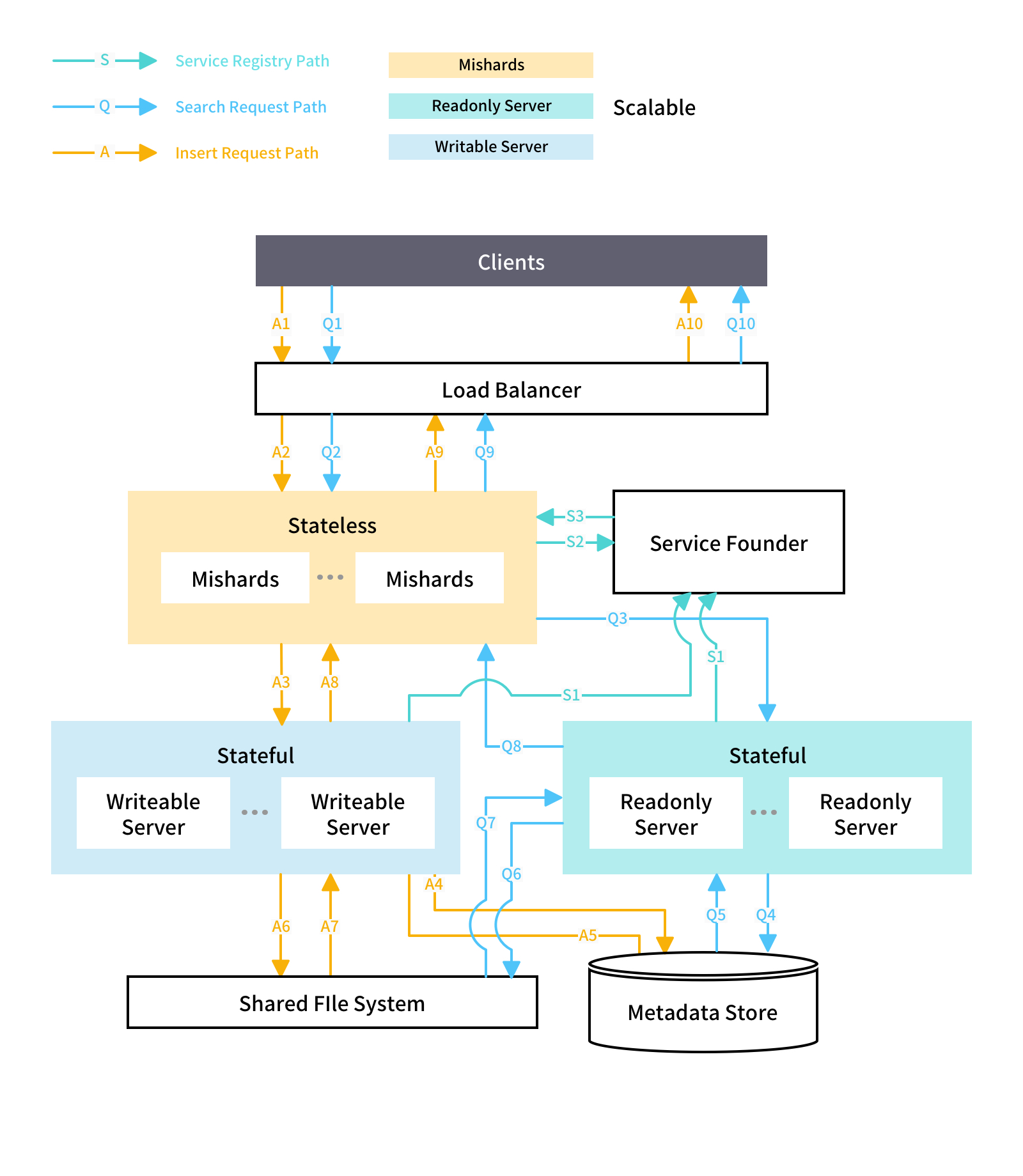
服务跟踪
主要服务组件
- 服务发现框架,如动物园管理员等,和领事
- 负载均衡器,如 Nginx、HAProxy、入口控制器
- 错误节点:无状态、可扩展
- 仅写入 Milvus 节点:单个节点且不可伸缩。您需要为此节点使用高可用性解决方案,以避免单点故障
- 只读 Milvus 节点:有状态节点和可扩展节点
- 共享存储服务:所有 Milvus 节点都使用共享存储服务来共享数据,如 NAS 或 NFS
- 元数据服务:所有 Milvus 节点使用此服务共享元数据
此服务需要 MySQL 高可用性解决方案
可扩展组件
- 米沙德
- 只读 Milvus 节点
组件简介
错误节点
Mishard 负责分解上游请求和将子请求路由到子服务。结果汇总后返回上游。
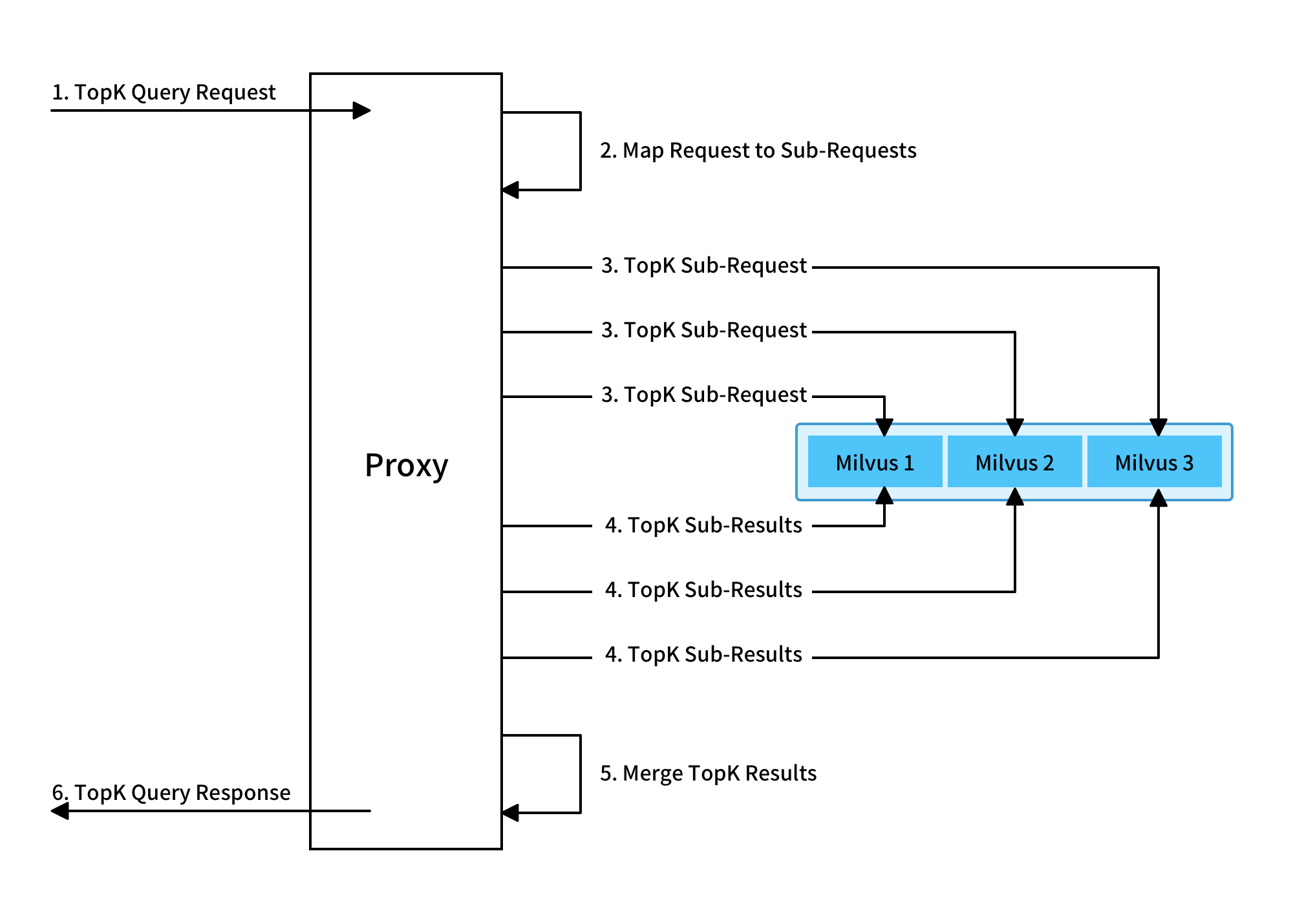
如上表所示,Mishards 在接受 TopK 搜索请求后,首先将请求分解为子请求,然后将子请求发送到下游服务。收集所有子响应时,将合并子响应并返回到上游。
由于 Mishards 是一种无状态服务,因此它不会保存数据或参与复杂的计算。因此,节点的配置要求不高,计算能力主要用于合并子结果。因此,可以增加高并发的 Mishards 节点数。
米尔武斯节点
Milvus 节点负责 CRUD 相关的核心操作,因此它们具有相对较高的配置要求。首先,内存大小应足够大,以避免磁盘 IO 操作太多。其次,CPU 配置也会影响性能。随着群集大小的增加,需要更多的 Milvus 节点来增加系统吞吐量。
只读节点和可写节点
- Milvus 的核心操作是矢量插入和搜索。搜索对 CPU 和 GPU 配置有极高的要求,而插入或其他操作的要求相对较低。将运行搜索的节点与运行其他操作的节点分离会导致更经济的部署。
- 在服务质量方面,当节点执行搜索操作时,相关硬件将满载运行,无法确保其他操作的服务质量。因此,使用两种节点类型。搜索请求由只读节点处理,其他请求由可写节点处理。
只允许一个可写节点
- 目前,Milvus 不支持为多个可写实例共享数据
需要为可写节点准备高可用性解决方案。
只读节点可伸缩性
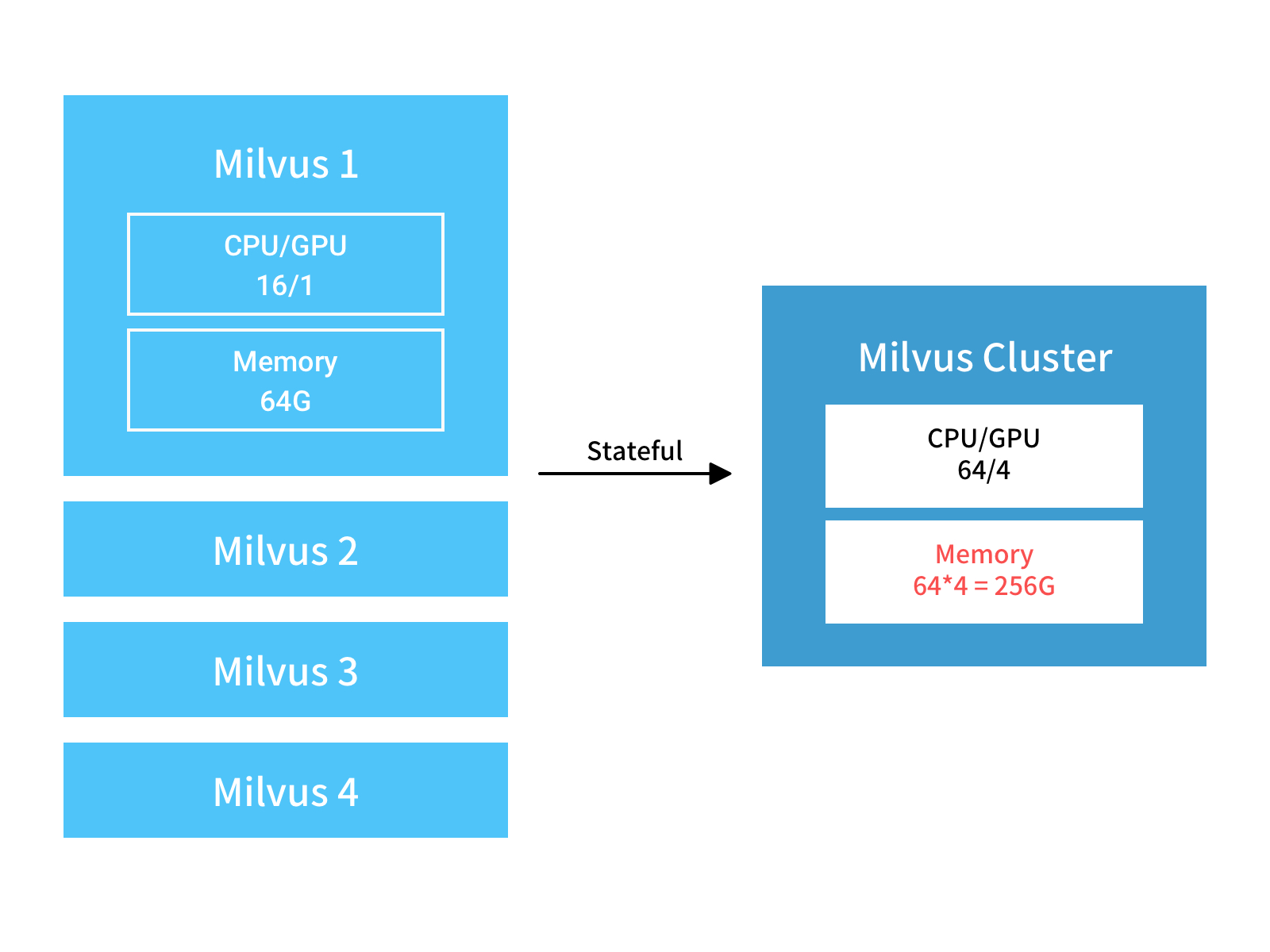
- 当数据大小非常大或延迟要求极高时,您可以将只读节点水平缩放为有状态节点。假设有 4 台主机,每个主机具有以下配置:CPU 核心:16、GPU:1、内存:64 GB。下图显示了水平缩放有状态节点时的群集。计算能力和内存均以线性方式扩展。数据被拆分为 8 个分片,每个节点处理来自 2 个分片的请求。
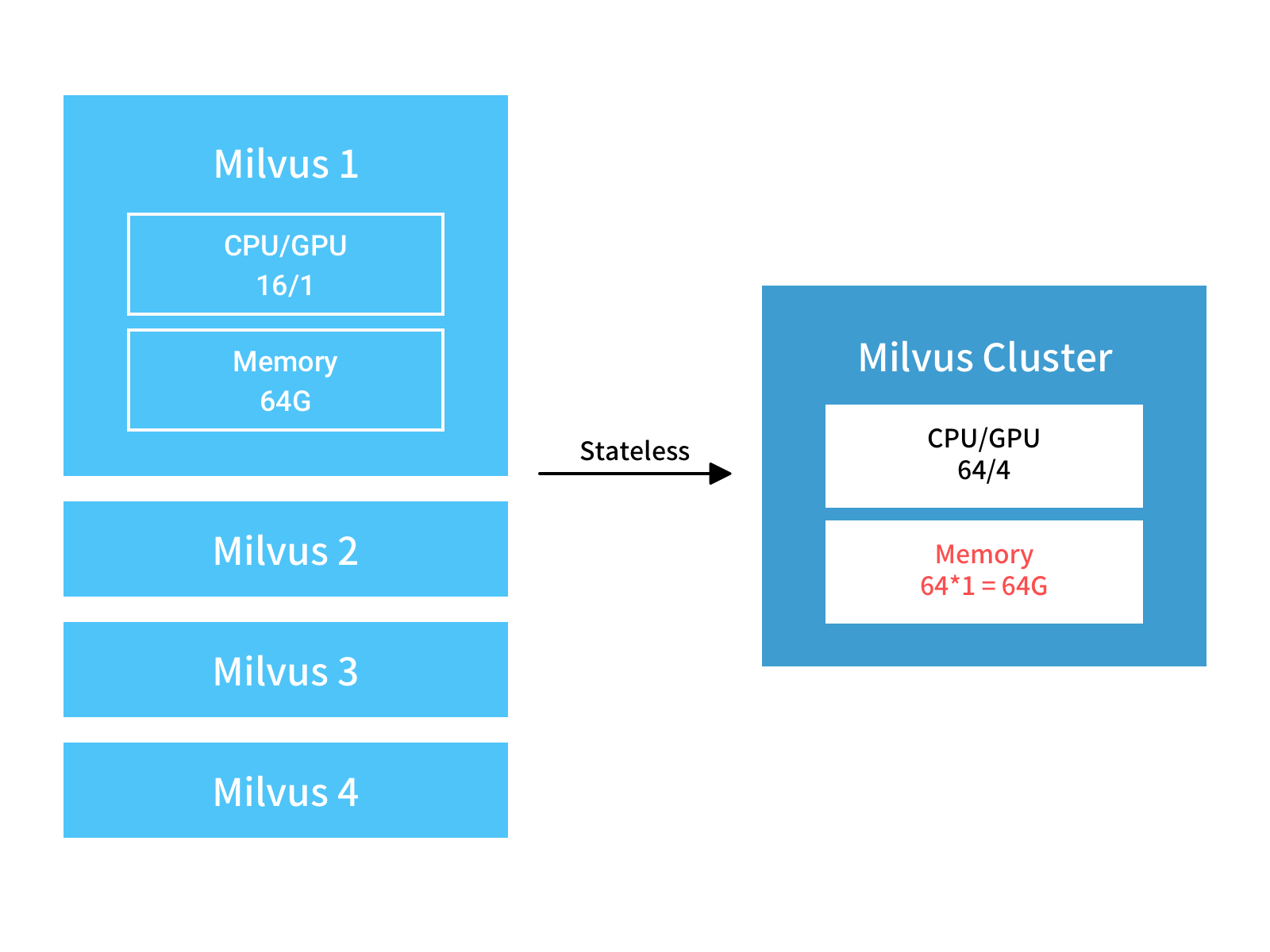
- 当某些分片的请求数很大时,可以为这些分片部署无状态只读节点以提高吞吐量。以上面的主机为例。当主机组合成无服务器群集时,计算能力将线性增加。由于要处理的数据不会增加,因此同一数据分片的处理能力也会线性增加。
元数据服务
关键词: MySQL
在分布式系统中,Milvus 可写节点是唯一的元数据生成者。Mishards 节点、Milvus 可写节点和 Milvus 只读节点都是元数据的使用者。目前,Milvus 仅支持 MySQL 和 SQLite 作为元数据的存储后端。在分布式系统中,服务只能部署为高可用 MySQL。
服务发现
关键词: 阿帕奇动物园管理员, 等, 领事, 库伯内特斯

服务发现提供有关所有 Milvus 节点的信息。Milvus 节点在联机时注册其信息,在脱机时注销。Milvus 节点还可以通过定期检查服务的运行状况来检测异常节点。
服务发现包含很多框架,包括等、领事、动物园管理员等。Mishards 定义了服务发现接口,并为按插件进行扩展提供了可能性。目前,Mishards 提供两种插件,它们对应于 Kubernetes 群集和静态配置。您可以通过遵循这些插件的实现来自定义自己的服务发现。接口是暂时的,需要重新设计。有关编写自己的插件的更多信息将在即将发表的文章中详细阐述。
负载平衡和服务分片
关键词: Nginx, HAProxy, Kubernetes
服务发现和负载平衡一起使用。负载平衡可以配置为轮询、哈希或一致哈希。
负载均衡器负责将用户请求重新发送到 Mishards 节点。
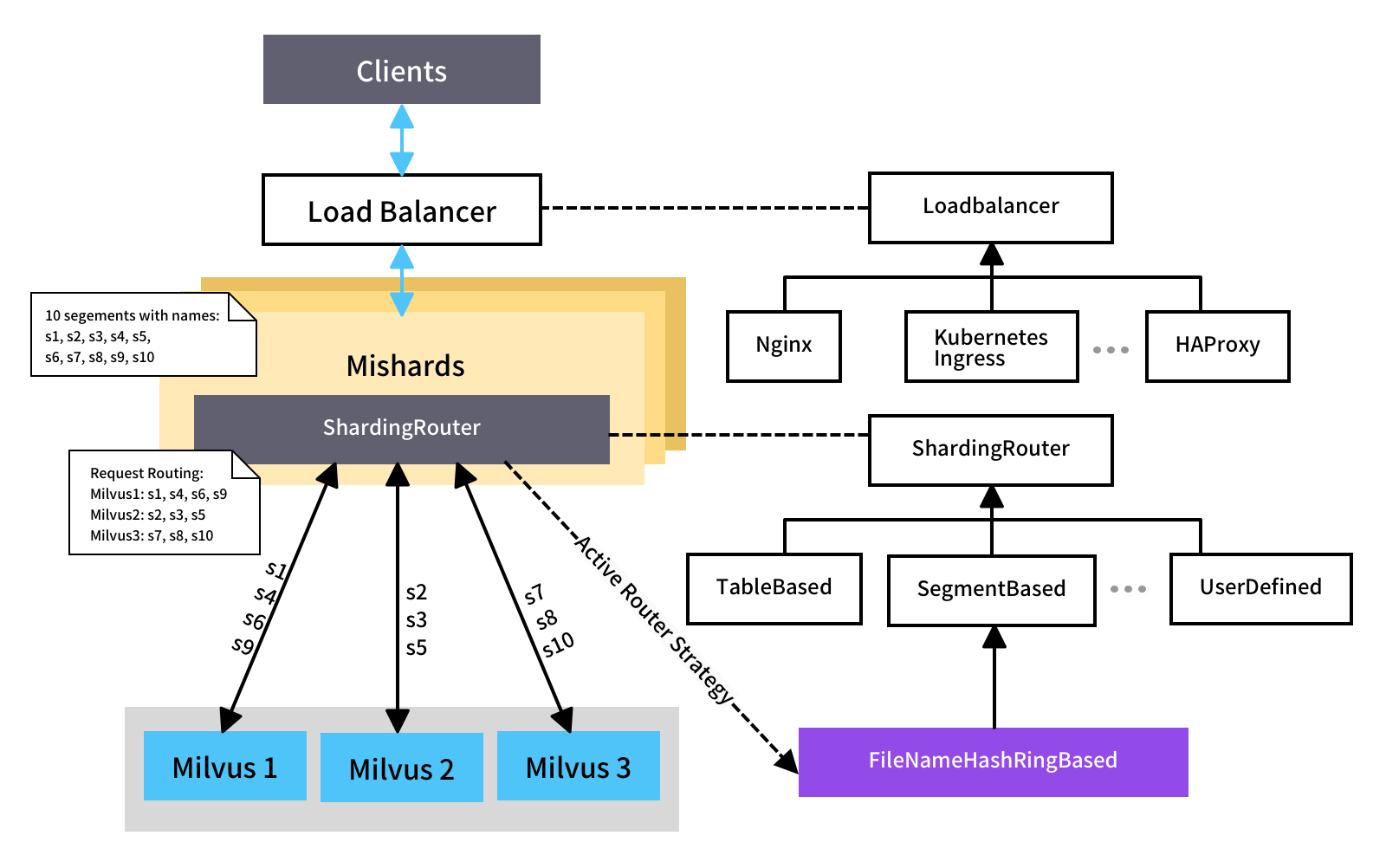
每个 Mishards 节点通过服务发现中心获取所有下游 Milvus 节点的信息。元数据服务可以获取所有相关的元数据。Mishards 通过消耗这些资源实现分片。Mishards 定义了与路由策略相关的接口,并通过插件提供扩展。目前,Mishards 提供了基于最低段级别的一致的哈希策略。如图所示,有 10 个段,s1 到 s10。根据基于段的一致哈希策略,Mishards 将有关 s1、24、s6 和 s9 的请求路由到 Milvus 1 节点,s2、s3、s5 到 Milvus 2 节点,将 s7、s8、s10 到 Milvus 3 节点。
根据您的业务需求,您可以按照默认的一致哈希路由插件自定义路由。
跟踪
关键词: 开放跟踪, 杰格, 齐普金
鉴于分布式系统的复杂性,请求将发送到多个内部服务调用随着复杂性的增加,可用跟踪系统的好处不言自明。我们选择 CNCF 开放式跟踪标准。OpenTracing 提供独立于平台、独立于供应商的 API,供开发人员方便地实现跟踪系统。
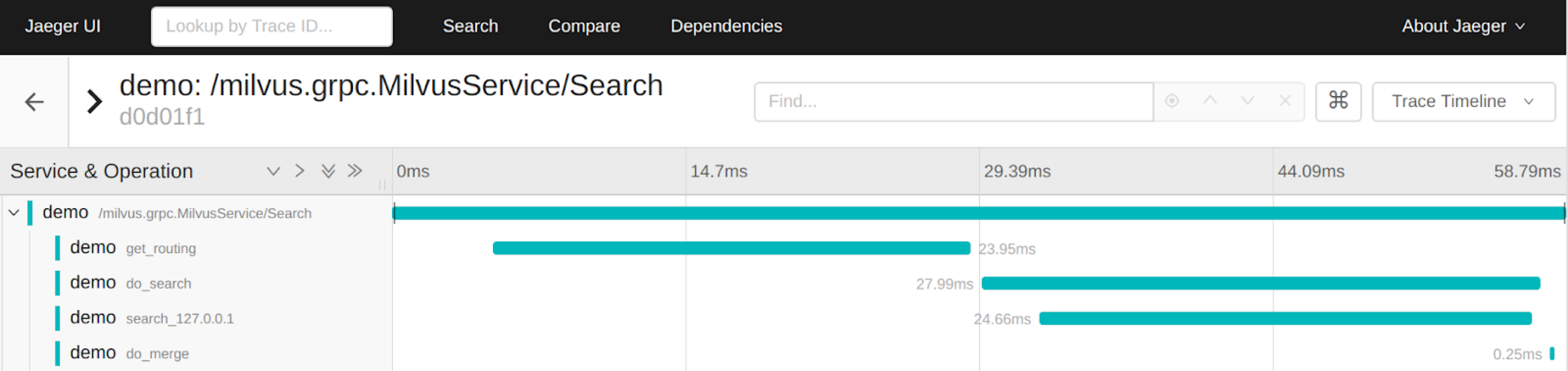
上图是在搜索调用期间跟踪的示例。搜索调用 get_routing do_search 和 do_merge 连续 do_search search_127.0.0.1 调用。
整个跟踪记录形成以下树:
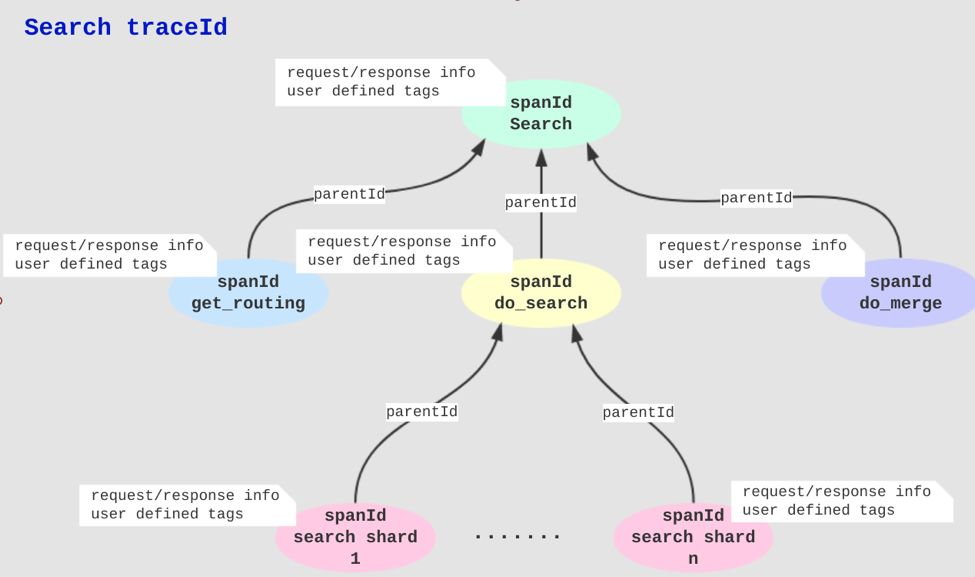
以下图表显示了每个节点的请求/响应信息和标记的示例:

开放跟踪已集成到米尔武斯。更多信息将在即将发布的文章中介绍。
监控和警报
关键词:普罗米修斯,格拉马纳

米尔武斯集成了普罗米修斯来收集指标数据。Grafana 实现基于指标的监视,警报管理器用于警报。米沙德也将整合普罗米修斯。
日志分析
关键词: 弹性, 洛普斯塔什, 基巴纳
对于群集服务,日志文件分布在不同的节点中。要确定问题,您需要登录到相应的服务器来获取日志。由于需要一起分析多个日志文件,因此使用 ELK 堆栈进行服务器日志分析是不错的选择。
总结
作为服务中间件,Mishards 集成了服务发现、路由请求、结果合并和跟踪。还提供基于插件的扩展。目前,基于 Mishard 的分布式解决方案仍有以下挫折:
- Mishards 使用代理作为中间层,并且具有延迟成本
- Milvus 可写节点是单点服务
- 依赖于高可用 MySQL 服务
- 当有多个分片且单个分片具有多个副本时,部署很复杂
- 缺少缓存层,例如对元数据的访问
今后,我们将继续改进 Mishards,以便更方便地应用于生产环境。我们欢迎任何反馈和建议,希望我们能一起构建更好的开源工具!