
介绍
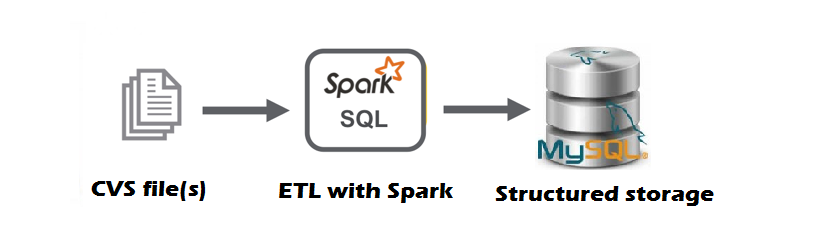
本文演示了 Apache Spark 如何使用 PySpark 编写强大的 ETL 作业。PySpark 可帮助您创建更具可扩展性的处理和分析(大)数据。
在我们的案例中,我们将使用一个数据集,其中包含来自超过 370,000 辆二手车的信息(在 Kaggle 上托管的数据)。 请务必注意,数据的内容是德语。
什么是阿帕奇火花
Apache Spark是最受欢迎的大规模数据处理引擎之一。它是一个开源系统,具有支持多态编程语言的 API。数据处理在内存中完成,因此比 MapReduce 快 100 倍。Spark 附带的库支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的Spark SQL、用于机器学习的 MLlib、用于图形处理的GraphX和Spark 流式处理。它可以从本地计算机运行,但也可以扩展到数百个节点的群集。
什么是 ETL?
ETL(Extract、T ransform 和Load)是将数据从一个系统迁移到另一个系统的过程。 T数据提取是从同质或异构源检索数据的过程,用于进一步的数据处理和数据存储。在数据处理期间,数据正在清理,并修改或删除错误或不准确的记录。最后,将处理后的数据加载(例如存储)到目标系统,如数据仓库或数据湖或 NoSQL 或 RDBMS。
提取
每个 Spark 应用程序的出发点都是创建 SparkSession。这是一个驱动程序过程,用于维护有关 Spark 应用程序的所有相关信息,它还负责在所有执行器之间分发和调度应用程序。我们只需通过以下方式创建 SparkSession:
格式("csv") |
.架构(架构) |
.选项("标题","真") |
.load(环境="HOME"]="/数据/自动.csv")
打印("加载到 PySpark 中的数据","\n")
返回 df' 数据朗="文本/x-python"*
Ⅹ
defload_df_with_schema(火花):
架构结构类型(*
结构字段("日期已爬"时间戳类型 true),
结构字段("卖方",字符串类型(),假),6结构字段("报价类型"字符串类型true),7结构场("价格"长类型真),8结构字段("abtest"字符串类型true),9结构字段("车辆类型"字符串类型true),10结构字段("年度注册"字符串类型true),11结构场("电源PS",短型(),真),13结构字段("模型"字符串类型true),14结构场("公里"长类型真),15结构字段("月注册"字符串类型true),16结构场("燃料类型"字符串类型true),17结构场("品牌"字符串类型真),18结构字段("日期创建",日期类型(),真),20结构场("nrofPictures"短型真),21结构字段("邮码"字符串类型true),22结构字段("最后看到"时间戳类型true)23])2425df火花|26读取 |27.格式("csv"|28.架构(架构|29.选项("标题""true"|30.负载(环境="HOME"="/数据/自动.csv")3132打印("加载到 PySpark 中的数据""\n")33对汽车数据集的五行进行采样
如您所见,有多列包含空值。我们可以处理丢失的数据与各种各样的选项。但是,讨论此情况已不及本文的范围。因此,我们选择将缺少的值保留为 null。但是,此数据集中有更多的奇怪的值和列,因此需要一些基本转换:
此清理的基本原理基于以下内容:列"日期已爬"和"lastSeen"似乎对任何未来的分析都不起作用。列"nrOfPictures"中的所有值等于 0,因此我们决定删除此列。
卖方
格韦利希 3
私人 371525优惠类型
安格博特 371513
格苏 12检查"卖方"和"报价类型"列时,会产生以下数字。因此,我们可以删除包含值"gewerblich"的三行,然后删除列"卖方"。相同的逻辑也适用于列"offerType",因此,我们只剩下一个更加平衡的数据集。例如,我们将数据集如下所示:
"已清理"汽车数据集的最后五行
负荷
我们已经将原始数据转换为分析就绪数据,因此,我们已准备好将数据加载到本地运行的 MySQL 数据库中进行进一步分析。例如,我们初始化了 MySQL 数据库,其中带有"自动"和"汽车"的表。
使用 MySQL 连接器 Python 在 Python 中连接 MySQL 数据库的步骤
1. 使用 pip 安装 MySQL 连接器 Python。
2. 使用 MySQL 连接器 Python 的 mysql.connector.connect() 方法,具有所需的参数来连接 MySQL。
3. 使用 connect() 方法返回的连接对象创建游标对象以执行数据库操作。
4执行() 从 Python 执行 SQL 查询。
5. 工作完成后,使用 cursor.close() 和 MySQL 数据库连接使用连接.close()关闭 Cursor 对象。
6. 捕获异常,如果在此过程中可能发生任何异常。
现在,我们已经创建了一个游标,我们可以在我们的"自动"数据库中创建名为"汽车"的表:
创建表后,现在可以使用数据集填充它了。我们可以将数据作为元组列表(其中每个记录都是一个元组)添加到我们的 INSERT 语句中:
因此,现在可以使用我们以前定义的游标执行此命令:
Python
xxxxxxx11cur.执行许多(insert_querycars_seqcars_seq= 我们将多行(从列表中)插入到表中png"数据-新="假"数据大小="14380"数据大小格式化="14.4 kB"数据类型="临时"数据 url="/存储/临时/134514 96-3 行.png"src_"http://www.cheeli.com.cn/wp-内容/上传/2020/05/13451496-3行.png"/]
我们需要调用以下代码将事务提交到 MySQL:
Python
xxxxxxx11康恩 .提交()为了确保数据集在 MySQL 中正确加载,我们可以在 MySQL 工作台中检查:
最后评论
对于试图构建可扩展数据应用程序的任何数据工程师或数据科学家而言,PySpark是一个非常强大且非常有用(大)的数据工具。本文的代码可以在GitHub上找到。由于这是我在平台上的第一篇文章。请随时给我您的反馈或意见。
引用



/filters:no_upscale()/news/2026/02/mysql-foreign-keys/en/resources/1innodb-vs-sql-engine-foreign-key-cascade-1024x510-1770991931623.jpg "MySQL 9.6:对外键约束及级联操作的修改")
