
我们刚刚发布了一个新的 ScyllaDB 示例应用程序,一个视频流应用程序。该项目可在 GitHub 上获取。该博客介绍了视频流应用程序的功能和技术堆栈,并详细介绍了数据建模过程。
Video 流媒体应用功能
该应用程序采用简约设计,具有最基本的视频流应用程序功能:
- 列出所有视频,按创建日期排序(主页)
- 列出您开始观看的视频
- 观看视频
- 从上次停下的地方继续观看视频
- 在每个视频缩略图下显示进度条
技术堆栈
- 编程语言:TypeScript
- 数据库:ScyllaDB
- 框架:NextJS(页面路由器)
- 组件库:Material_UI
使用 ScyllaDB 实现低延迟视频流应用
ScyllaDB 是一款低延迟、高性能的 NoSQL 数据库,与 Apache Cassandra 和 DynamoDB 兼容。它非常适合处理视频流应用程序的大规模数据存储和检索要求。 ScyllaDB 具有所有流行编程语言的驱动程序,并且如本示例应用程序所示,它与 NextJS 等现代 Web 开发框架很好地集成。
视频流服务中的低延迟对于提供无缝的用户体验至关重要。为了为高性能奠定基础,您需要设计一个适合您需求的数据模型。让我们继续使用示例数据建模过程来看看它是什么样子的。
视频流应用数据建模
在 ScyllaDB 大学数据建模课程中,我们教导 NoSQL 数据建模应始终首先从您的应用程序和查询开始。然后,您可以逆向工作并根据要在应用程序中运行的查询创建架构。此过程可确保您创建适合您的查询并满足您的要求的数据模型。
考虑到这一点,让我们回顾一下我们的视频流应用程序在每个页面加载时需要运行的查询!
页面:继续观看
在此页面上,您可以列出他们已开始观看的所有视频。此视图包括视频缩略图和缩略图下的进度条。
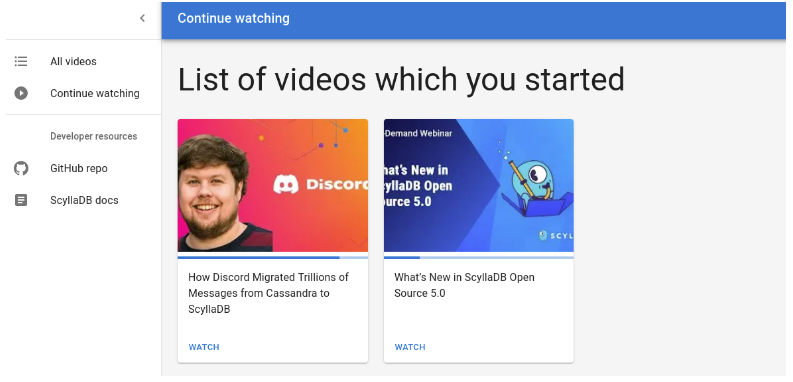
查询:获取观看进度
CQL
从 watch_history 中选择 video_id,进度,其中 user_id = ?限制 9; 查询:获取视频内容
查询:获取视频内容


