

哈多普生态系统
在本博客中,让我们了解 Hadoop 生态系统。在开始使用 Hadoop 之前,需要了解一个基本主题。此 Hadoop 生态系统博客将让您熟悉业界使用的大数据框架,这些框架是 Hadoop 认证所必需的。
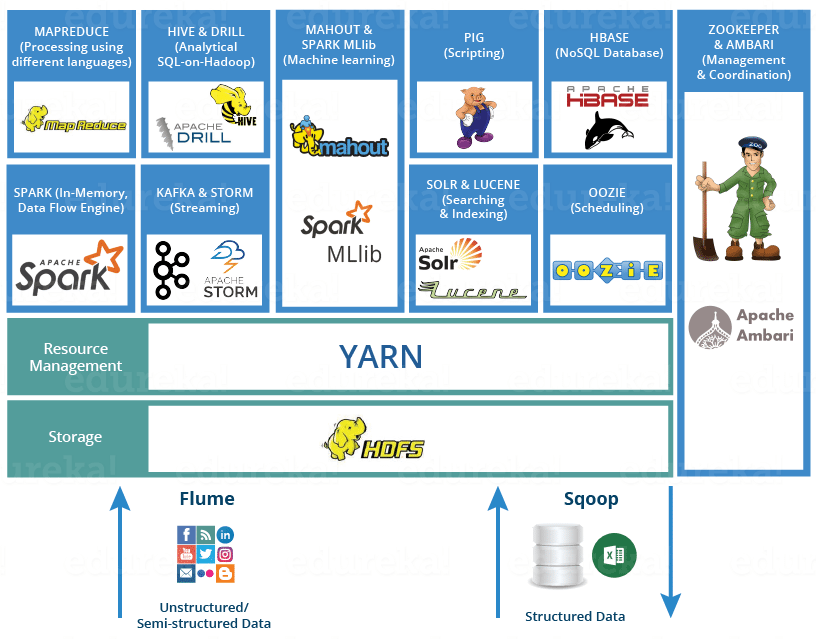
Hadoop 生态系统既不是编程语言,也不是服务;它是解决大数据问题的平台或框架。您可以将它视为包含其内部许多服务(引入、存储、分析和维护)的套件。让我们讨论并简要了解服务如何单独和协作地工作。
下面是 Hadoop 组件,它们共同构成了 Hadoop 生态系统。我将在这个博客中介绍他们每个人:
- HDFS =哈多普分布式文件系统。
- YARN –另一个资源谈判者。
- 映射减少=使用编程进行数据处理。
- 火花= 内存中数据处理。
- PIG、HIVE和使用查询的数据处理服务(类似于 SQL)。
- HBase = NoSQL 数据库。
- 马胡,火花MLlib –机器学习。
- 阿帕奇钻–哈迪奥普上的 SQL。
- 动物园管理员和管理群集。
- Oozie =作业计划。
- Flume、Sqoop =数据引入服务。
- 索尔和卢塞内»搜索和索引。
- Ambari =预配、监控和维护群集。
你可能也喜欢:完整的Apache火花集合[教程和文章]。
哈多普分布式文件系统
- Hadoop 分布式文件系统是 Hadoop 生态系统的核心组件或主干组件。
- HDFS 可以存储不同类型的大型数据集(即结构化、非结构化和半结构化数据)。
- HDFS 在资源上创建了一个抽象级别,我们可以将整个 HDFS 视为一个单元。
- 它帮助我们跨各种节点存储数据,并维护有关存储数据的日志文件(元数据)
NameNode的主节点,它不存储实际数据。它包含元数据,就像日志文件一样,或者你可以说是一个目录。因此,它需要较少的存储和高计算资源。- 另一方面,您的所有数据都存储在
DataNodes上,因此需要更多的存储资源。这些数据节点是分布式环境中的商品硬件(如笔记本电脑和台式机)。这就是 Hadoop 解决方案极具成本效益的原因。 - 在写入数据时,您始终与 通信
NameNode。然后,它在内部向客户端发送请求,以存储和复制各种 上的数据DataNodes。

纱
将YARN视为您的 Hadoop 生态系统的大脑。它通过分配资源和计划任务来执行所有处理活动。
- 它有两个主要组件 (
ResourceManager和NodeManager)。ResourceManager再次是处理部门中的主要节点。- 它接收处理请求,然后将请求的各个部分传递到相应的
NodeManagers,其中进行实际处理。 NodeManagers安装在每个DataNode上。它负责在每个 DataNode 上执行任务。
- 计划程序:根据应用程序资源要求,计划程序执行计划算法并分配资源。
- 应用程序管理器:虽然
ApplicationsManager接受作业提交,但它协商到容器(即执行流程的数据节点环境),以执行应用程序的特定ApplicationMaster和监视进度。ApplicationMastersDataNodeDataNodeResourceManager有两个组件 (Schedulers和ApplicationsManager)
换句话说,MapReduce是一个软件框架,可帮助编写使用 Hadoop 环境中的分布式和并行算法处理大型数据集的应用程序。
- 在 MapReduce 程序中
Map(),Reduce()是两个函数。- 该
Map函数执行筛选、分组和排序等操作。 - 函数
Reduce聚合和汇总函数生成的结果map。 - Map 函数生成的结果是键值对 (K, V),它充当函数的输入
Reduce。
- 该
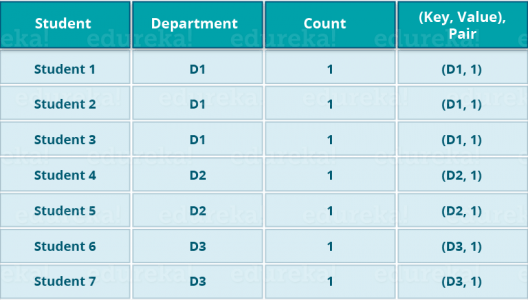
让我们以上述示例来更好地了解 MapReduce 计划。
我们有一个学生和他们各自的部门的例子。我们想计算每个系的学生人数。最初,Map 程序将执行并计算每个部门中出现的学生,从而生成键值对,如上所述。此键值对是函数的输入 Reduce 。Reduce然后,该职能部门将聚合每个部门,并计算每个部门的学生总数,并生成给定的结果。
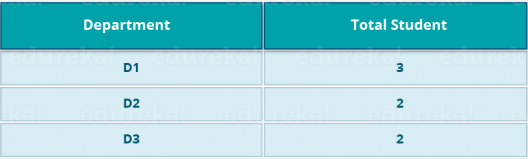 映射减少结果
映射减少结果
阿帕奇猪
PIG有两个部分:猪拉丁语,语言,和猪运行时,执行环境。你可以更好地理解它作为Java和JVM。
它支持猪拉丁语言,它有一个类似SQL的命令结构。
Apache PIG 缓解了那些不是来自编程背景的人。你可能很想知道怎么做?好吧,我会告诉你一个有趣的事实:10行猪拉丁文 = 约200行映射-减少Java代码
但是,当我说在 Pig 作业的后端执行地图缩减作业时,不要感到震惊。
- 编译器在内部将猪拉丁文转换为 MapReduce。它生成一组连续的 MapReduce 作业。
- PIG最初由雅虎开发。
- 它为您提供了一个平台,用于构建 ETL(提取、转换和加载)、处理和分析大型数据集的数据流。
猪是如何工作的?
在 PIG 中,首先,加载命令加载数据。然后,我们执行各种功能,如分组,筛选,联接,排序等。最后,您可以将数据转储到屏幕上,也可以将结果存储在 HDFS 中。
阿帕奇蜂巢
Facebook 为精通 SQL 的用户创建了HIVE。因此,在 Hadoop 生态系统中工作时,HIVE 会让他们有宾到家的感觉。
基本上,HIVE 是一个数据仓库组件,使用类似 SQL 的接口在分布式环境中执行读取、写入和管理大型数据集。
HIVE + SQL = HQL
- Hive 的查询语言称为 Hive 查询语言 (HQL)。
- 它有两个基本组件:蜂巢命令线和JDBC/ODBC驱动程序。
- Hive 命令行接口用于执行 HQL 命令。
- Java数据库连接 (JDBC) 和对象数据库连接 (ODBC) 用于从数据存储建立连接.
- 蜂巢具有高度可扩展性。它可以对大型数据集处理(即批处理处理)和实时处理(即交互式查询处理)执行操作。
- 它支持 SQL 的所有基元数据类型。
- 您可以使用预定义函数或编写定制的用户定义函数 (UDF) 来完成您的特定需求。
阿帕奇·马胡
![]()
现在,让我们来谈谈以机器学习闻名的 Mahout。Mahout 提供了一个用于创建可扩展的机器学习应用程序的环境。
马胡德是做什么的?
它执行协作筛选、聚类和分类。有些人也认为频繁的项目集缺失作为马胡的功能典型的用例是电子商务网站。
Mahout 提供了一个命令行来调用各种算法。它有一个预定义的库集,该库已经包含针对不同用例的不同内置算法。
阿帕奇火花
Apache Spark 是分布式计算环境中实时数据分析的框架。Spark 写于 Scala,最初由加州大学伯克利分校开发。它执行内存中计算,以提高通过 Map-Reduce 的数据处理速度。
通过利用内存计算和其他优化,它比 Hadoop 快 100 倍,用于大规模数据处理。因此,它要求的处理能力比映射减少更高的。

正如您所看到的,Spark 包含高级库,包括对 R、SQL、Python、Scala、Java 等的支持。这些标准库增加了复杂工作流中的无缝集成。在此,它还允许各种服务集与它集成,如 MLlib、GraphX、SQL 和数据帧、流式处理服务等,以提高其功能。
这是每个人心目中的一个很常见的问题:
“阿帕奇火花:阿帕奇·哈多普的杀手或救世主?” – 奥赖利
答案 – 这不是一个苹果比。Apache Spark 最适合实时处理,而 Hadoop 旨在存储非结构化数据并执行批处理。结合 Apache Spark 的能力,即高处理速度、高级分析和多集成支持,以及 Hadoop 在商用硬件上的低成本操作,从而获得最佳效果
阿帕奇HBase
![]()
HBase 是一个开源、非关系式分布式数据库。换句话说,它是一个 NoSQL 数据库。它支持所有类型的数据,这就是为什么它能够处理 Hadoop 生态系统中的任何事物。
它仿制了谷歌的BigTable,这是一个分布式存储系统,旨在应对大型数据集。HBase 设计为在 HDFS 上运行,并提供类似 BigTable 的功能。
它为我们提供了一种容错存储稀疏数据的方法,这在大多数大数据用例中很常见。HBase 是用 Java 编写的,而 HBase 应用程序可以用 REST、Avro 和节俭 API 编写。
为了更好地理解,让我们举一个例子。您有数十亿封客户电子邮件,您需要了解在其电子邮件中使用”投诉”一词的客户数量。请求需要快速处理(即实时处理)。因此,在这里,我们处理大型数据集,同时检索少量数据。HBase 是为解决此类问题而设计的。
阿帕奇演习
![]()
顾名思义,Apache Drill 用于钻取任何类型的数据。它是一个开源应用程序,用于与分布式环境一起分析大型数据集。
- 它是谷歌德雷梅尔的复制品。
- 它支持不同类型的 NoSQL 数据库和文件系统,包括 Azure Blob 存储、Google 云存储、HBase、MongoDB、MapR-DB HDFS、MapR-FS、Amazon S3、Swift、NAS 和本地文件。
从本质上讲,Apache Drill 背后的主要目的是提供可扩展性,以便我们可以高效地处理 PB 和艾字节的数据(或者您可以在几分钟内说)
阿帕奇动物园管理员
Apache ZooKeeper 是任何 Hadoop 作业的协调员,其中包括 Hadoop 生态系统中各种服务的组合。Apache ZooKeeper 与分布式环境中的各种服务进行协调。
在动物园管理员之前,在 Hadoop 生态系统中协调不同服务非常困难且耗时。服务在同步数据时与交互(如通用配置)存在许多问题。即使配置了服务,服务配置的更改也会使其变得复杂且难以处理。分组和命名也是一个耗时的因素。
由于上述问题,动物园管理员被引入。通过执行同步、配置维护、分组和命名,可以节省大量时间。尽管这是一个简单的服务,但它可用于构建强大的解决方案。
像Rackspace、雅虎和eBay这样的大牌公司在其数据工作流程中都使用这项服务,所以你对ZooKeeper的重要性有了了解。
![]()
阿帕奇·奥齐
将 Apache Oozie 视为 Hadoop 生态系统内的时钟和报警服务。对于Apache工作,Oozie就像一个调度程序。它计划 Hadoop 作业并将其绑定为一个逻辑工作。
有两种类型的 Oozie 工作:
- Oozie工作流:这些是要执行的连续操作集。你可以把它看作是一个接力赛,每个运动员等待最后一个完成他们的部分。
- Oozie 协调员:这些是 Oozie 作业,当数据提供给它时触发。把它看作是我们身体的反应刺激系统。正如我们对外部刺激做出反应一样,Oozie 协调员对数据的可用性做出响应,否则就如此。
 阿帕奇弗卢姆标志
阿帕奇弗卢姆标志
阿帕奇·弗卢姆
引入数据是我们 Hadoop 生态系统的重要组成部分。
- Flume 是一项帮助将非结构化和半结构化数据引入 HDFS 的服务。
- 它为我们提供了一个可靠和分布式的解决方案,并帮助我们收集、聚合和移动大量的数据集。
- 它有助于从 HDFS 中从各种来源(如网络流量、社交媒体、电子邮件、日志文件等)引入在线流数据。
现在,让我们从下图中了解 Flume 的体系结构:
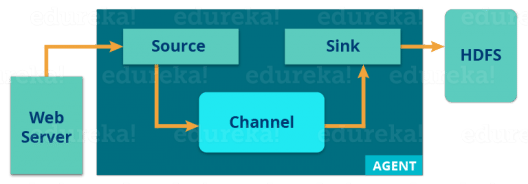
Flume 代理将各种数据源的流数据引入 HDFS。从图中,您可以轻松地了解 Web 服务器指示数据源。Twitter是著名的流媒体数据来源之一。
烟道代理有三个组件:源、接收器和通道。
- 源:接受来自传入流线型的数据,并将该数据存储在通道中。
- 频道:充当本地存储或主存储。通道是 HDFS 中数据源和持久数据之间的临时存储。
- 水槽:从通道收集数据,并在 HDFS 中永久提交或写入数据。
阿帕奇·斯库普
现在,让我们来谈谈另一个数据引入服务,即 Sqoop。Flume 和 Sqoop 的主要区别是:
- 流塞只将非结构化数据或半结构化数据引入 HDFS
让我们使用下图了解 Sqoop 的工作原理:
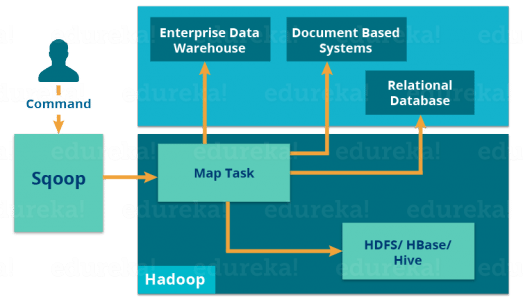
当我们提交 Sqoop 命令时,我们的主要任务被划分为子任务,然后由单个映射任务在内部处理。映射任务是子任务,它将部分数据导入 Hadoop 生态系统。
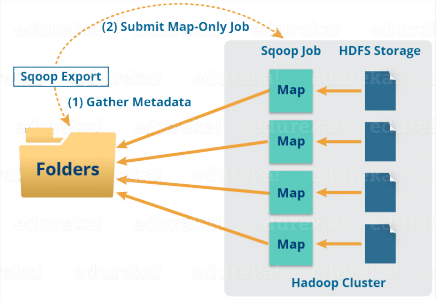
当我们提交作业时,它会映射到地图任务,这将从 HDFS 带来大量数据。这些数据块将导出到结构化数据目标。结合所有这些导出的数据块,我们会在目标接收整个数据,在大多数情况下,这是一个 RDBMS(MYSQL/Oracle/SQL 服务器)。
阿帕奇·索尔和卢塞恩
Apache Solr 和 Apache Lucene 用于在 Hadoop 生态系统中搜索和索引。
- Apache Lucene 基于 Java,这也有助于拼写检查
它使用Lucene Java搜索库作为搜索和完整索引的核心。
阿帕奇·安巴里
![]()
Ambari 是一个 Apache 软件基础项目,旨在使 Hadoop 生态系统更易于管理。
它包括用于预配、管理和监视Apache Hadoop 群集的软件。
安巴里提供:
- 哈多普群集预配:
- 它为我们提供了在多台主机上安装 Hadoop 服务的分步过程。
- 它还处理群集上的 Hadoop 服务的配置。
- 哈多普群集管理:
- 它提供用于跨群集启动、停止和重新配置 Hadoop 服务的集中管理服务。
- 哈多普群集监视:
- 为了监视运行状况和状态,Ambari 提供了一个仪表板。
- 琥珀色警报框架是一种警报服务,它在需要时通知用户(例如,如果节点在节点上出现故障或磁盘空间不足等)。
最后,我想提请你注意三个重要说明:
- Hadoop 生态系统的成功归功于整个开发人员社区。许多大型组织,如Facebook、谷歌、雅虎、加州大学伯克利分校(Berkeley)等,都为提高Hadoop的能力做出了贡献。
- 在 Hadoop 生态系统中,有关一个或两个工具(Hadoop 组件)的知识无助于构建解决方案。您需要学习一组 Hadoop 组件,这些组件协同工作以构建解决方案。
- 根据用例,我们可以从 Hadoop 生态系统中选择一组服务,并为组织创建量身定制的解决方案。
我希望这个博客是翔实的,增加的价值给你。