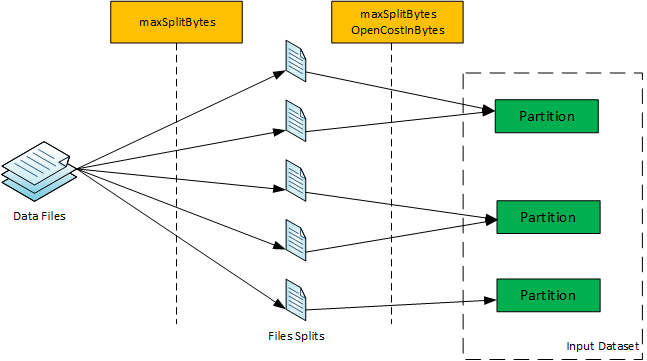
大多数 Spark 应用程序从一组数据文件(以各种格式)为其执行管道提供输入数据。为了便于从文件读取数据,Spark 在原始 RDD 和数据集的上下文中提供了专用 API。这些 API 将读取过程从数据文件抽象为输入 RDD 或具有明确数量的分区的数据集。然后,用户可以对这些输入 RDD/数据集执行各种转换/操作。
输入原始 RDD 或数据集中的每个分区都映射到一个或多个数据文件,映射在文件的一部分或整个文件上完成。在执行具有输入 RDD/数据集的 Spark 作业期间,输入 RDD/数据集的每个分区都通过根据分区映射到数据文件读取数据来计算,然后计算的分区数据将馈送到从属 RDD/Dataset 进一步输入执行管道中。
输入 RDD/数据集(映射到数据文件)中的分区数是根据多个参数决定的,以实现最佳的并行性。这些参数具有默认值,也可以由用户调整。在输入 RDD/Dataset 中确定的分区数可能会影响作业的整个执行管道的效率。因此,请务必了解如何根据输入 RDD 或数据集时的特定参数确定分区数。
用于读取数据文件的数据集 API 时的分区数:提供了多个 API 将数据文件读取到数据集中,其中每个 API 都调用SparkSession的实例,该实例自版本 2.0 起形成 Spark 应用程序的统一入口点。其中一些 API 如下所示:
xxxxxxx
•文件格式特定API*
数据集<行>=火花会话。阅读。csv(字符串路径或Listof路径列表 )
阅读。json(字符串路径或Listof路径列表)4数据集<行>=火花会话。阅读。文本(字符串路径或Listof路径列表)5数据集<行>=火花会话。阅读。镶木地板(字符串路径或Listof路径列表)6数据集<行>=火花会话。阅读。orc(字符串路径或Listof路径列表)7]通用 API|9数据集<行>=火花会话。阅读。格式(字符串文件格式).负载(字符串路径或Listof路径列表)1011上面的 API中的"路径"是either实际文件路径或目录路径,也可以could包含通配符,如as"*"。这些 API 有更多的变体,其中包括指定与特定文件读取相关的各种选项apache.org/docs/2.3.0/api/java/org/apache/spark/sql/DataFrameReader.html"href"https://spark.apache.org/docs/2.3.0/api/java/org/apache/火花/sql/DataFrameReader.html"rel="不跟随"目标="_blank"*可在此处提及。
查看用于读取数据文件的 API 后,下面是影响数据文件中数据的数据的数据集中分区数的配置参数列表:
Java
xxxxxxx11(a)火花。默认值。并行性(默认总计否9896px; ">
2(b)火花。SQL.文件。最大分区字节(默认128MB)3(c)火花。SQL.文件。开放成本字节(默认4MB)使用这些配置参数值,将计算称为 maxSplitBytes 的最大拆分准则,如下所示:
Java
xxxxxxx11最大分值=最小值 (最大分区字节字节 percore)其中字节PerCore的计算方式如下:
Java
xxxxxxx11(of所有数据data文件of的大小之和=文件数数量of=打开成本字节/默认值。并行性现在使用"maxSplit字节",如果共享数据,则拆分每个数据文件(要读取)。因此,如果文件是可拆分的,其大小大于"最大拆分字节",则该文件将拆分为多个"最大拆分字节"块,最后一个区块小于或等于"最大拆分字节"。如果文件不可拆分或大小小于"最大拆分字节",则只有一个大小相等的文件块大小相等的文件大小。
为所有数据文件计算文件块后,一个或多个文件块将打包在分区中。打包过程从初始化空分区开始,然后针对每个迭代的文件块在文件块上迭代:
- 如果没有正在打包当前分区,请初始化要打包的新分区,并将其迭代的文件块分配给它。分区大小将成为块大小和"openCostInBytes"的额外开销的总和。
- 如果块大小的添加不超过当前分区的大小(正在打包)超过"最大拆分字节",则文件块将成为当前分区的一部分。分区大小由块大小和"openCostInBytes"的额外开销增加。
- 如果块大小的添加超过当前分区的大小,则压缩的当前分区超过"最大拆分字节",则当前分区将声明为已完成,并启动新的分区。迭代文件块将成为正在启动的较新的分区的一部分,较新的分区大小将成为块大小和"openCostInBytes"的额外开销的总和
说明为一组数据文件派生分区的过程,首先根据计算值的最大SplitBytes拆分数据文件,然后根据 maxSplitBYtes 和 opencostBytes 将拆分打包到一个或多个分区中。 尽管到达分区数的过程似乎有点复杂,但基本的想法是,如果文件是可拆分的,则首先在 maxSplitBytes 的边界处拆分各个文件。在此之后,文件或未拆分文件的拆分块被打包到分区中,这样,如果分区大小超过最大 SplitBytes,则在将块打包到分区期间,该分区被视为完整的打包,然后采取新的分区进行打包。因此,一定数量的分区最终从包装过程派生出来。为了便于说明,下面是一些在数据集 API 中到达分区数的示例:
(a) 54个镶木地板文件,每个65MB,所有3个配置参数默认,No.核心等于 10:此分区数为 54。每个文件只有一个区块。这里很明显,在此示例中,两个文件无法打包在一个分区中(因为大小将超过"最大拆分字节",添加第二个文件后为 128 MB)。
(b)
54 个镶木地板文件,每个 63 MB,默认所有 3 个配置参数,No.核心等于 10:分区数再次为 54。似乎可以在这里打包两个文件,但由于在打包第一个文件后存在"openCostInBytes"(4 MB)的开销,因此,在添加第二个文件后,128 MB 的限制被交叉,因此,在本示例中,两个文件无法打包在一个分区中png" 数据-新="false"数据大小="7761"数据大小格式化="7.8 kB"数据类型="临时"数据 url="/存储/临时/13631081-1592405604675 .png"src="http://www.cheeli.com.cn/wp-内容/上传/2020/06/13631081-1592405604675.png"样式="宽度:700px;"/>
(c)
54 个镶木地板文件,每个 40 MB,默认所有 3 个配置参数,No.核心等于 10:这次分区数为 18。根据上述包装过程,即使添加了两个文件 40 MB 和开销为 4 MB 每个, 总大小出来是 88 MB, 因此第三个文件 40 MB 也可以打包, 因为大小出来只有 128 MB.因此,分区数为 18。
需要注意的是,在评估文件块的打包资格时,不考虑 openCost 的开销,仅在考虑在分区中包装文件块后增加分区大小时考虑开销。
(d) 54 个镶木地板文件,每个 40 MB,最大分区字节设置为 88 MB,其他两个默认值配置。核心等于 10:此情况的分区数为 27,而不是 18,如 (c)。这是因为"最大分区字节"的值发生了变化。54 个分区可以根据文件拆分和打包过程轻松推理,如上所述。
(e) 54 个镶木地板文件,每个 40 MB,spark.default.Parallelism 设置为 400,其他两个配置默认值为 No。核心等于 10:此案例的分区数为 378。同样,378 个分区也可以很容易地根据文件拆分和打包过程进行推理,如上所述。
用于读取数据文件的 RDD API 时的分区数:
下面提供了用于将数据文件读取到 RDD 中的 API,在 SparkSession 实例的 SparkContex 上调用了每个 API:
Java
xxxxxxx11newAPIHadoopFile(字符串路径,类<F> fClass,类<K> kClass,类<V> vClass,组织。阿帕奇.有。conf.配置 conf)2*火花上下文。文本文件(字符串路径int最小分区)3*火花上下文。序列文件(字符串路径类<K>键类Class类 <V>值类)4*火花上下文。序列文件(字符串路径类<K>键类类<V>值类intminsss)]火花上下文。对象文件(字符串路径, int 最小分区, scala.反映。类标签<T> 证据$4)在其中一些 API 中,会询问参数"最小分区",而在另一些 API 中则不询问参数。如果未询问,则默认值为 2 或 1,在默认值为 1 时为 1。此"最小分区"是决定这些 API 返回的 RDD 中分区数的因素之一。其他因素包括以下 Hadoop 配置参数的值:
Java
xxxxxxx11最小尺寸(映射)。最小。拆分。大小-default默认值1MB)2块大小(dfs.块大小-默认128MB)根据三个参数的值,一种称为拆分大小的拆分准则计算为:
Java
xxxxxxx11拆分大小=数学。最大值(最小大小数学)。最小(目标大小块大小) );2其中3目标大小=to要读取of的所有文件长度的总和/最小分区现在使用"拆分大小",如果共享数据,则拆分每个数据文件(要读取)。因此,如果文件的大小大于"拆分大小",则该文件将拆分为多个"拆分大小"块,最后一个区块小于或等于"拆分大小"。如果文件不可拆分或大小小于"拆分大小",则只有一个大小大小等于文件长度的文件块。
每个文件区块(大小大于零)都映射到单个分区。因此,RDD 中的分区数(由数据文件的 RDD API 返回)等于使用"拆分大小"切片数据文件派生的非零文件块数png" 数据新="false"数据大小="31210"数据大小格式化="31.2 kB"数据类型="临时"数据 url="/存储/临时/13631089-159240573191 5.png"src="http://www.cheeli.com.cn/wp-内容/上传/2020/06/13631089-1592405731915.png"样式="宽度:700px;"/>
说明为一组数据文件派生分区的过程,首先根据拆分大小的计算值拆分数据文件,然后将每个非零拆分分配给单个分区。 为了便于说明,下面是一些在数据集 API 中到达分区数的示例: (a) 31个镶木地板文件,每个 330 MB,默认 128 MB 的块大小,未指定的最小分区,默认为"mapred.min.split.size",不核心等于 10:此分区数为 93。拆分大小仅来自 128 MB,因此基本上分区数等于 31 个文件占用的块数。每个文件占用 3 个块,因此总块和总分区为 93。
(b) 54
镶木地板文件,每个 40 MB,在默认 128 MB 时块大小,未指定最小分区,默认为"映射.min.split.size",不核心等于 10:此分区数为 54。拆分大小仅来自 128 MB,因此基本上分区数等于 54 个文件的块数。每个文件占用 1 个块,因此总块和总分区为 54。
(c) 31
镶木地板文件,每个 330 MB,在默认 128 MB 时块大小,最小分区指定为 1000,默认为"mapred.min.split.size",不核心等于 10:此分区数为 1023。拆分大小仅来自 10.23 MB,因此每个文件的文件拆分数等于 33,文件拆分总数为 1023,因此分区总数也为 1023。
(d) 31
镶木地板文件,每个 330 MB,在默认 128 MB 时块大小,未指定最小分区,"mapred.min.split.size"设置为 256 MB,否。核心等于 10:此分区数为 62。拆分大小仅来自 256 MB,因此每个文件的文件拆分数等于 2,文件拆分总数为 62,因此分区总数也为 62。
从"拆分大小"计算中可以明显看出,如果希望 Paritions 大小大于块大小,则需要将"mapred.min.split.size"设置为大于块大小的数字。此外,如果希望分区大小小于块大小,则应将"最小分区"设置为相对较高的值,以便目标大小(文件大小的总和/"最小参数")计算小于块大小。
总结
直到最近,针对一组数据文件拾取一定数量的分区的过程,对我来说总是显得很神秘。但是,最近,在优化例程中,我想更改 Spark 为处理一组数据文件而选取的默认分区数,此时我已开始与校样一起全面解码此过程。希望这个解码过程的描述也可以帮助读者更深入地理解Spark,并使他们能够设计一个高效和优化的Spark例程。
请记住,最佳分区数是高效可靠的 Spark 应用程序的关键。如果收到此帖子的反馈或查询,请写在评论部分。我希望你发现它很有用。