
如果您有在关注科技相关的新闻,可能读过有关人工智能(AI)应用程序如何通过强化学习训练,在围棋、国际象棋等棋类游戏以及电子游戏中击败人类玩家的报道。作为一名工程师、科学家或研究人员,您可能会希望利用这种新的和不断发展的技术。但是该如何开始呢?最好的起点是什么?如何理解它的概念?如何实现强化学习?以及它是不是解决某个问题的正确办法。

简单来说,强化学习就是一种有潜力解决复杂决策问题的机器学习。但要真正理解它对我们的影响,需要了解三个关键问题:
·什么是强化学习?
·在什么情况下,强化学习才是正确的方法?
·我应该遵循什么样的工作流程,来解决强化学习问题?
什么是强化学习?
强化学习是机器学习的一种,在动态环境中,计算机通过反复的试错交互来学习执行某项任务。这种学习方法使计算机能够做出一系列决策,使任务的奖励指标最大化,而不需要人工干预,也不需要通过明确的编程来完成任务。
为了更好地认识强化学习,我们通过一个现实世界中与其类似的场景进行理解。图1显示了使用强化学习来训练狗的一般表示。
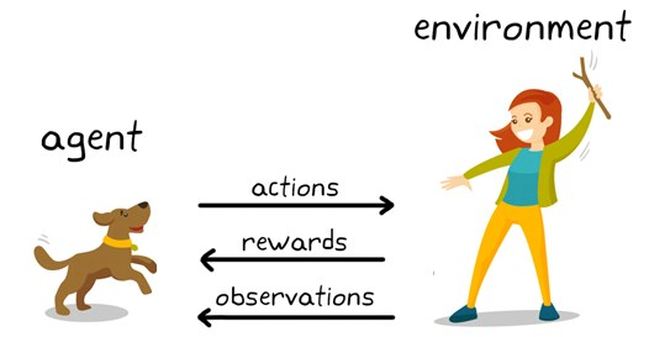
图1:狗狗训练中的强化学习
在这种情况下,强化学习的目标是训练狗(agent)在一个环境(environment)中完成一项任务,这里的“环境”包括狗所处的物理环境和训练者。首先,驯兽师发出一条命令或指示,狗会观察(observation)。然后狗会做出反应。如果动作接近期望的行为,训练者可能会提供奖励,如食物或玩具;否则,将不提供任何奖励或提供负面奖励。在训练开始的时候,狗可能会做出更多的随机动作,比如当命令是“坐下”时,它会翻身,因为它试图将特定的观察与动作和奖励联系起来。观察和动作之间的这种关联或映射称为策略。
从狗的角度来看,最理想的情况是它能对每一个提示做出正确的反应,这样它就能得到尽可能多的奖励。因此,强化学习训练的全部意义在于“调整”狗的策略,使它学习期望的行为,从而获得最大的回报。训练完成后,狗应该能够观察主人并采取适当的行动,例如,当命令它“坐下”时,它应该使用它开发的内部策略来“坐下”。
基于训狗示例,我们可以来想想使用自动驾驶系统来停车的任务。该任务的目标是车载计算机(agent)将车辆停放在正确的停车位置,并具有正确的方向。就像训狗一样,这里的环境是agent之外的一切,包括车辆的动态、附近的其他车辆、天气状况等等。在训练过程中,agent通过摄像头、GPS和激光雷达等传感器的读数(observations)来产生转向、刹车和加速指令(actions)。为了学习如何从观察中生成正确的动作(策略调优),代理通过试错过程反复尝试停车。奖励信号可以用来评估试验的好坏,并指导学习过程。
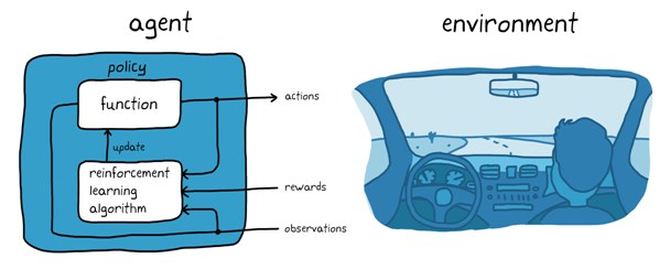
图2:自动停车中的强化学习
在训狗的例子中,训练是在狗的大脑内进行的。在自动停车的例子中,训练是由训练算法来监督的。训练算法负责根据收集到的传感器读数、动作和奖励调整代理的策略。训练结束后,车辆的计算机应该能够仅使用调整后的策略和传感器读数来停车。
在什么情况下,强化学习才是正确的方法?
目前,业界已经发展了许多增强学习的训练算法,虽然本文不讨论训练算法,但值得一提的是,其中一些最流行的算法是依赖于深度神经网络策略的。神经网络最大的优点是它们可以对非常复杂的行为进行编码,这为在应用中使用强化学习打开了方便之门,否则会非常难以处理或极具挑战性,包括使用传统算法。例如,在自动驾驶中,神经网络可以代替驾驶员,通过同时观察来自多个传感器的输入来决定如何转动方向盘,比如摄像头和激光雷达测量(端到端解决方案)。没有神经网络,问题通常会被分解成小块:一个模块,分析相机的输入以识别有用的特性;另一个模块,用于过滤激光雷达测量;可能还需要一个组件, 通过融合传感器的输出来描述车辆所处环境的全貌;还有“司机”模块或更多。不过,虽然端到端解决方案优势很大,但也有一些缺点。
深层神经网络训练策略通常被视为一个“黑箱”,即神经网络的内部结构非常复杂,通常包括数以百万计的参数,几乎不可能去理解、解释和评估网络所采取的决策 (左边的图3)。这使得很难为神经网络建立正式的性能担保政策。可以这样想:即使你对你的宠物进行了训练,仍然会有你的命令被忽视的时候。
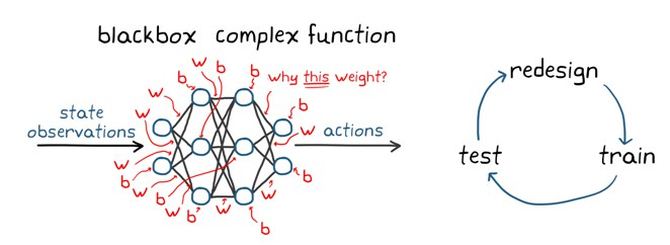
图3:强化学习的一些挑战
另一件需要记住的事情是,强化学习不是样本效率。这意味着,为了达到可接受的表现,通常需要大量的训练。举个例子,AlphaGo是首个在围棋比赛中击败世界冠军的电脑程序,它经过几天的不间断训练,玩了数百万场游戏,积累了数千年的人类知识。即使是相对简单的应用程序,训练时间也可能从几分钟到几小时甚至几天不等。最后,如何正确地设置问题可能也比较棘手;这需要做出许多设计决策,可能需要一些迭代才能正确(图3右侧)。这些决策包括如为神经网络选择适当的架构、调整超参数和形成奖励信号等等。
总而言之,如果你正在进行一个时间或安全因素非常关键的项目,也许应该采用替代的、传统的方法,强化学习可能不是最好的。否则,就试一试吧。
强化学习工作流程
使用强化学习训练代理的一般工作流程包括以下步骤(图4)。
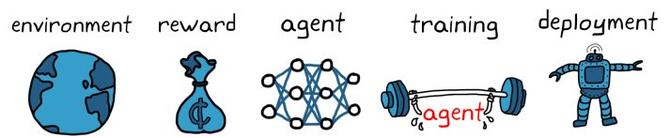
图4:强化学习的工作流程
1. 创建环境
首先,您需要定义代理运行的环境,包括代理和环境之间的接口。环境可以是仿真模型,也可以是真实的物理系统。采用模拟环境通常是很好的选择,因为它们更安全(真实硬件往往非常昂贵)并且允许进行实验。
2. 定义奖励
接下来,需要指定代理用于根据任务目标度量其性能的奖励信号,以及如何从环境中计算该信号。奖励塑造可能是一个棘手的问题,可能需要几次迭代才能得到正确的结果。
3.创建代理
在此步骤中,您将创建代理。代理由策略和训练算法组成,需要:
a.选择一种表示策略的方法(例如,使用神经网络或查找表)。
b.选择合适的训练算法。不同的表现形式通常与特定类别的训练算法相关,但通常,大多数现代算法依赖于神经网络,因为它们是解决大型状态/动作空间和复杂问题的良好候选方法。
4. 对代理进行训练和验证
设置训练选项(例如,停止标准)并对代理进行训练,以此来调整策略。在训练结束后,还需要对其展开验证。根据应用程序的不同,训练可能需要几分钟到几天的时间。对于复杂的应用程序,在多个CPU、GPU和计算机集群上并行化训练可以加快速度。
5. 部署策略
使用生成的C/ c++或CUDA代码部署经过训练的策略表示。此时无需担心代理和训练算法——策略是一个独立的决策系统。
使用强化学习训练代理是一个迭代的过程。后期的决策和结果可能需要您返回到学习工作流的早期阶段。例如,如果训练过程没有在合理的时间内收敛到最优策略,你可能需要在重新训练代理之前更新以下配置:
·训练设置
·学习算法的配置
·策略表示
·奖励信号的定义
·行动与观测信号
·环境动态
今天,像Reinforcement Learning Toolbox(图5)这样的工具可以帮助您快速学习并实现控制器和复杂系统(如机器人和自主系统)的决策算法。
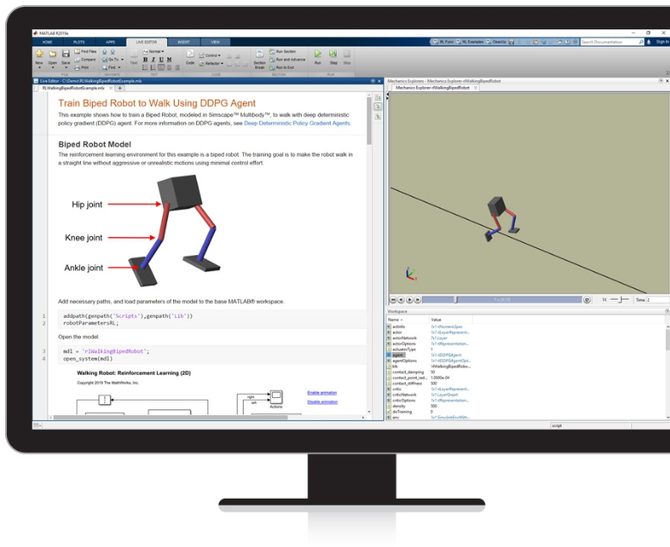
图5.使用Reinforcement Learning Toolbox教机器人走路
不管选择什么工具,在决定采用强化学习之前,一定要思考这样一个问题:“考虑到我在这个项目上拥有的时间和资源,强化学习对我来说是正确的方法吗?”
原文作者:Emmanouil Tzorakoleftherakis